 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom LLMs to LRMs: Rethinking Pruning for Reasoning-Centric Models
Jan 26, 2026Large language models (LLMs) are increasingly costly to deploy, motivating extensive research on model pruning. However, most existing studies focus on instruction-following LLMs, leaving it unclear whether established pruning strategies transfer to reasoning-augmented models that explicitly generate long intermediate reasoning traces. In this work, we conduct a controlled study of pruning for both instruction-following ($\textbf{LLM-instruct}$) and reasoning-augmented ($\textbf{LLM-think}$) models. To isolate the effects of pruning, we align pruning calibration and post-pruning recovery data with each model's original training distribution, which we show yields more stable and reliable pruning behavior. We evaluate static depth pruning, static width pruning, and dynamic pruning across 17 tasks spanning classification, generation, and reasoning. Our results reveal clear paradigm-dependent differences: depth pruning outperforms width pruning on classification tasks, while width pruning is more robust for generation and reasoning. Moreover, static pruning better preserves reasoning performance, whereas dynamic pruning excels on classification and generation but remains challenging for long-chain reasoning. These findings underscore the need for pruning strategies that explicitly account for the distinct characteristics of reasoning-augmented LLMs. Our code is publicly available at https://github.com/EIT-NLP/LRM-Pruning.
A Brain-inspired Embodied Intelligence for Fluid and Fast Reflexive Robotics Control
Jan 21, 2026Recent advances in embodied intelligence have leveraged massive scaling of data and model parameters to master natural-language command following and multi-task control. In contrast, biological systems demonstrate an innate ability to acquire skills rapidly from sparse experience. Crucially, current robotic policies struggle to replicate the dynamic stability, reflexive responsiveness, and temporal memory inherent in biological motion. Here we present Neuromorphic Vision-Language-Action (NeuroVLA), a framework that mimics the structural organization of the bio-nervous system between the cortex, cerebellum, and spinal cord. We adopt a system-level bio-inspired design: a high-level model plans goals, an adaptive cerebellum module stabilizes motion using high-frequency sensors feedback, and a bio-inspired spinal layer executes lightning-fast actions generation. NeuroVLA represents the first deployment of a neuromorphic VLA on physical robotics, achieving state-of-the-art performance. We observe the emergence of biological motor characteristics without additional data or special guidance: it stops the shaking in robotic arms, saves significant energy(only 0.4w on Neuromorphic Processor), shows temporal memory ability and triggers safety reflexes in less than 20 milliseconds.
SemPA: Improving Sentence Embeddings of Large Language Models through Semantic Preference Alignment
Jan 08, 2026Traditional sentence embedding methods employ token-level contrastive learning on non-generative pre-trained models. Recently, there have emerged embedding methods based on generative large language models (LLMs). These methods either rely on fixed prompt templates or involve modifications to the model architecture. The former lacks further optimization of the model and results in limited performance, while the latter alters the internal computational mechanisms of the model, thereby compromising its generative capabilities. We propose SemPA, a novel approach that boosts the sentence representations while preserving the generative ability of LLMs via semantic preference alignment. We leverage sentence-level Direct Preference Optimization (DPO) to efficiently optimize LLMs on a paraphrase generation task, where the model learns to discriminate semantically equivalent sentences while preserving inherent generative capacity. Theoretically, we establish a formal connection between DPO and contrastive learning under the Plackett-Luce model framework. Empirically, experimental results on both semantic textual similarity tasks and various benchmarks for LLMs show that SemPA achieves better semantic representations without sacrificing the inherent generation capability of LLMs.
LongBench Pro: A More Realistic and Comprehensive Bilingual Long-Context Evaluation Benchmark
Jan 06, 2026The rapid expansion of context length in large language models (LLMs) has outpaced existing evaluation benchmarks. Current long-context benchmarks often trade off scalability and realism: synthetic tasks underrepresent real-world complexity, while fully manual annotation is costly to scale to extreme lengths and diverse scenarios. We present LongBench Pro, a more realistic and comprehensive bilingual benchmark of 1,500 naturally occurring long-context samples in English and Chinese spanning 11 primary tasks and 25 secondary tasks, with input lengths from 8k to 256k tokens. LongBench Pro supports fine-grained analysis with task-specific metrics and a multi-dimensional taxonomy of context requirement (full vs. partial dependency), length (six levels), and difficulty (four levels calibrated by model performance). To balance quality with scalability, we propose a Human-Model Collaborative Construction pipeline: frontier LLMs draft challenging questions and reference answers, along with design rationales and solution processes, to reduce the cost of expert verification. Experts then rigorously validate correctness and refine problematic cases. Evaluating 46 widely used long-context LLMs on LongBench Pro yields three findings: (1) long-context optimization contributes more to long-context comprehension than parameter scaling; (2) effective context length is typically shorter than the claimed context length, with pronounced cross-lingual misalignment; and (3) the "thinking" paradigm helps primarily models trained with native reasoning, while mixed-thinking designs offer a promising Pareto trade-off. In summary, LongBench Pro provides a robust testbed for advancing long-context understanding.
SplitFlux: Learning to Decouple Content and Style from a Single Image
Nov 19, 2025



Disentangling image content and style is essential for customized image generation. Existing SDXL-based methods struggle to achieve high-quality results, while the recently proposed Flux model fails to achieve effective content-style separation due to its underexplored characteristics. To address these challenges, we conduct a systematic analysis of Flux and make two key observations: (1) Single Dream Blocks are essential for image generation; and (2) Early single stream blocks mainly control content, whereas later blocks govern style. Based on these insights, we propose SplitFlux, which disentangles content and style by fine-tuning the single dream blocks via LoRA, enabling the disentangled content to be re-embedded into new contexts. It includes two key components: (1) Rank-Constrained Adaptation. To preserve content identity and structure, we compress the rank and amplify the magnitude of updates within specific blocks, preventing content leakage into style blocks. (2) Visual-Gated LoRA. We split the content LoRA into two branches with different ranks, guided by image saliency. The high-rank branch preserves primary subject information, while the low-rank branch encodes residual details, mitigating content overfitting and enabling seamless re-embedding. Extensive experiments demonstrate that SplitFlux consistently outperforms state-of-the-art methods, achieving superior content preservation and stylization quality across diverse scenarios.
Post-Training LLMs as Better Decision-Making Agents: A Regret-Minimization Approach
Nov 06, 2025Large language models (LLMs) are increasingly deployed as "agents" for decision-making (DM) in interactive and dynamic environments. Yet, since they were not originally designed for DM, recent studies show that LLMs can struggle even in basic online DM problems, failing to achieve low regret or an effective exploration-exploitation tradeoff. To address this, we introduce Iterative Regret-Minimization Fine-Tuning (Iterative RMFT), a post-training procedure that repeatedly distills low-regret decision trajectories back into the base model. At each iteration, the model rolls out multiple decision trajectories, selects the k-lowest regret ones, and fine-tunes itself on them. Unlike prior methods that (a) distill action sequences from known DM algorithms or (b) rely on manually crafted chain-of-thought templates, our approach leverages the regret metric to elicit the model's own DM ability and reasoning rationales. This reliance on model-generated reasoning avoids rigid output engineering and provides more flexible, natural-language training signals. Empirical results show that Iterative RMFT improves LLMs' DM performance across diverse models - from Transformers with numerical input/output, to open-weight LLMs, and advanced closed-weight models like GPT-4o mini. Its flexibility in output and reasoning formats enables generalization across tasks with varying horizons, action spaces, reward processes, and natural-language contexts. Finally, we provide theoretical insight showing that a single-layer Transformer under this paradigm can act as a no-regret learner in a simplified setting. Overall, Iterative RMFT offers a principled and general post-training framework for enhancing LLMs' decision-making capabilities.
STITCH 2.0: Extending Augmented Suturing with EKF Needle Estimation and Thread Management
Oct 29, 2025Surgical suturing is a high-precision task that impacts patient healing and scarring. Suturing skill varies widely between surgeons, highlighting the need for robot assistance. Previous robot suturing works, such as STITCH 1.0 [1], struggle to fully close wounds due to inaccurate needle tracking and poor thread management. To address these challenges, we present STITCH 2.0, an elevated augmented dexterity pipeline with seven improvements including: improved EKF needle pose estimation, new thread untangling methods, and an automated 3D suture alignment algorithm. Experimental results over 15 trials find that STITCH 2.0 on average achieves 74.4% wound closure with 4.87 sutures per trial, representing 66% more sutures in 38% less time compared to the previous baseline. When two human interventions are allowed, STITCH 2.0 averages six sutures with 100% wound closure rate. Project website: https://stitch-2.github.io/
LiteLong: Resource-Efficient Long-Context Data Synthesis for LLMs
Sep 19, 2025
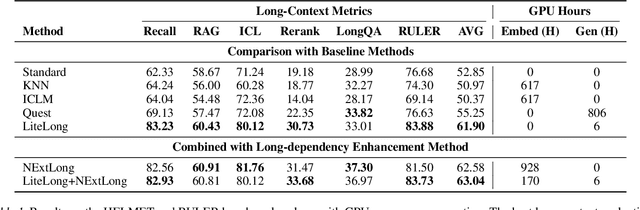


High-quality long-context data is essential for training large language models (LLMs) capable of processing extensive documents, yet existing synthesis approaches using relevance-based aggregation face challenges of computational efficiency. We present LiteLong, a resource-efficient method for synthesizing long-context data through structured topic organization and multi-agent debate. Our approach leverages the BISAC book classification system to provide a comprehensive hierarchical topic organization, and then employs a debate mechanism with multiple LLMs to generate diverse, high-quality topics within this structure. For each topic, we use lightweight BM25 retrieval to obtain relevant documents and concatenate them into 128K-token training samples. Experiments on HELMET and Ruler benchmarks demonstrate that LiteLong achieves competitive long-context performance and can seamlessly integrate with other long-dependency enhancement methods. LiteLong makes high-quality long-context data synthesis more accessible by reducing both computational and data engineering costs, facilitating further research in long-context language training.
Unified Start, Personalized End: Progressive Pruning for Efficient 3D Medical Image Segmentation
Sep 11, 20253D medical image segmentation often faces heavy resource and time consumption, limiting its scalability and rapid deployment in clinical environments. Existing efficient segmentation models are typically static and manually designed prior to training, which restricts their adaptability across diverse tasks and makes it difficult to balance performance with resource efficiency. In this paper, we propose PSP-Seg, a progressive pruning framework that enables dynamic and efficient 3D segmentation. PSP-Seg begins with a redundant model and iteratively prunes redundant modules through a combination of block-wise pruning and a functional decoupling loss. We evaluate PSP-Seg on five public datasets, benchmarking it against seven state-of-the-art models and six efficient segmentation models. Results demonstrate that the lightweight variant, PSP-Seg-S, achieves performance on par with nnU-Net while reducing GPU memory usage by 42-45%, training time by 29-48%, and parameter number by 83-87% across all datasets. These findings underscore PSP-Seg's potential as a cost-effective yet high-performing alternative for widespread clinical application.
Sparse Transformer for Ultra-sparse Sampled Video Compressive Sensing
Sep 10, 2025Digital cameras consume ~0.1 microjoule per pixel to capture and encode video, resulting in a power usage of ~20W for a 4K sensor operating at 30 fps. Imagining gigapixel cameras operating at 100-1000 fps, the current processing model is unsustainable. To address this, physical layer compressive measurement has been proposed to reduce power consumption per pixel by 10-100X. Video Snapshot Compressive Imaging (SCI) introduces high frequency modulation in the optical sensor layer to increase effective frame rate. A commonly used sampling strategy of video SCI is Random Sampling (RS) where each mask element value is randomly set to be 0 or 1. Similarly, image inpainting (I2P) has demonstrated that images can be recovered from a fraction of the image pixels. Inspired by I2P, we propose Ultra-Sparse Sampling (USS) regime, where at each spatial location, only one sub-frame is set to 1 and all others are set to 0. We then build a Digital Micro-mirror Device (DMD) encoding system to verify the effectiveness of our USS strategy. Ideally, we can decompose the USS measurement into sub-measurements for which we can utilize I2P algorithms to recover high-speed frames. However, due to the mismatch between the DMD and CCD, the USS measurement cannot be perfectly decomposed. To this end, we propose BSTFormer, a sparse TransFormer that utilizes local Block attention, global Sparse attention, and global Temporal attention to exploit the sparsity of the USS measurement. Extensive results on both simulated and real-world data show that our method significantly outperforms all previous state-of-the-art algorithms. Additionally, an essential advantage of the USS strategy is its higher dynamic range than that of the RS strategy. Finally, from the application perspective, the USS strategy is a good choice to implement a complete video SCI system on chip due to its fixed exposure time.