 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpace Object Detection using Multi-frame Temporal Trajectory Completion Method
Oct 22, 2025Space objects in Geostationary Earth Orbit (GEO) present significant detection challenges in optical imaging due to weak signals, complex stellar backgrounds, and environmental interference. In this paper, we enhance high-frequency features of GEO targets while suppressing background noise at the single-frame level through wavelet transform. Building on this, we propose a multi-frame temporal trajectory completion scheme centered on the Hungarian algorithm for globally optimal cross-frame matching. To effectively mitigate missing and false detections, a series of key steps including temporal matching and interpolation completion, temporal-consistency-based noise filtering, and progressive trajectory refinement are designed in the post-processing pipeline. Experimental results on the public SpotGEO dataset demonstrate the effectiveness of the proposed method, achieving an F_1 score of 90.14%.
DocShaDiffusion: Diffusion Model in Latent Space for Document Image Shadow Removal
Jul 02, 2025



Document shadow removal is a crucial task in the field of document image enhancement. However, existing methods tend to remove shadows with constant color background and ignore color shadows. In this paper, we first design a diffusion model in latent space for document image shadow removal, called DocShaDiffusion. It translates shadow images from pixel space to latent space, enabling the model to more easily capture essential features. To address the issue of color shadows, we design a shadow soft-mask generation module (SSGM). It is able to produce accurate shadow mask and add noise into shadow regions specially. Guided by the shadow mask, a shadow mask-aware guided diffusion module (SMGDM) is proposed to remove shadows from document images by supervising the diffusion and denoising process. We also propose a shadow-robust perceptual feature loss to preserve details and structures in document images. Moreover, we develop a large-scale synthetic document color shadow removal dataset (SDCSRD). It simulates the distribution of realistic color shadows and provides powerful supports for the training of models. Experiments on three public datasets validate the proposed method's superiority over state-of-the-art. Our code and dataset will be publicly available.
10K is Enough: An Ultra-Lightweight Binarized Network for Infrared Small-Target Detection
Mar 04, 2025

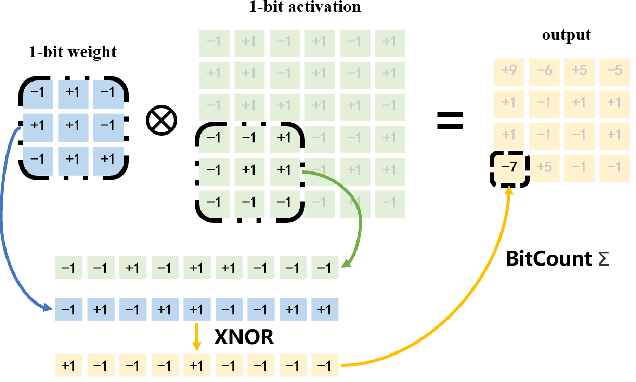
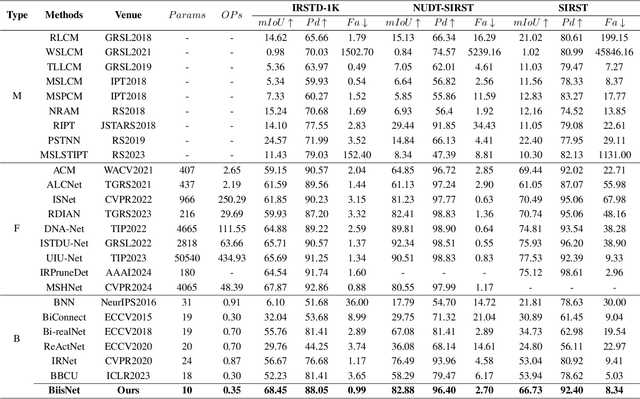
The widespread deployment of InfRared Small-Target Detection(IRSTD) algorithms on edge devices necessitates the exploration of model compression techniques. Binary neural networks (BNNs) are distinguished by their exceptional efficiency in model compression. However, the small size of infrared targets introduces stringent precision requirements for the IRSTD task, while the inherent precision loss during binarization presents a significant challenge. To address this, we propose the Binarized Infrared Small-Target Detection Network (BiisNet), which preserves the core operations of binarized convolutions while integrating full-precision features into the network's information flow. Specifically, we propose the Dot-Binary Convolution, which retains fine-grained semantic information in feature maps while still leveraging the binarized convolution operations. In addition, we introduce a smooth and adaptive Dynamic Softsign function, which provides more comprehensive and progressively finer gradient during back-propagation, enhancing model stability and promoting an optimal weight distribution.Experimental results demonstrate that BiisNet not only significantly outperforms other binary architectures but also demonstrates strong competitiveness among state-of-the-art full-precision models.
Hadamard Attention Recurrent Transformer: A Strong Baseline for Stereo Matching Transformer
Jan 02, 2025In light of the advancements in transformer technology, extant research posits the construction of stereo transformers as a potential solution to the binocular stereo matching challenge. However, constrained by the low-rank bottleneck and quadratic complexity of attention mechanisms, stereo transformers still fail to demonstrate sufficient nonlinear expressiveness within a reasonable inference time. The lack of focus on key homonymous points renders the representations of such methods vulnerable to challenging conditions, including reflections and weak textures. Furthermore, a slow computing speed is not conducive to the application. To overcome these difficulties, we present the \textbf{H}adamard \textbf{A}ttention \textbf{R}ecurrent Stereo \textbf{T}ransformer (HART) that incorporates the following components: 1) For faster inference, we present a Hadamard product paradigm for the attention mechanism, achieving linear computational complexity. 2) We designed a Dense Attention Kernel (DAK) to amplify the differences between relevant and irrelevant feature responses. This allows HART to focus on important details. DAK also converts zero elements to non-zero elements to mitigate the reduced expressiveness caused by the low-rank bottleneck. 3) To compensate for the spatial and channel interaction missing in the Hadamard product, we propose MKOI to capture both global and local information through the interleaving of large and small kernel convolutions. Experimental results demonstrate the effectiveness of our HART. In reflective area, HART ranked \textbf{1st} on the KITTI 2012 benchmark among all published methods at the time of submission. Code is available at \url{https://github.com/ZYangChen/HART}.
Look Inside for More: Internal Spatial Modality Perception for 3D Anomaly Detection
Dec 18, 2024



3D anomaly detection has recently become a significant focus in computer vision. Several advanced methods have achieved satisfying anomaly detection performance. However, they typically concentrate on the external structure of 3D samples and struggle to leverage the internal information embedded within samples. Inspired by the basic intuition of why not look inside for more, we introduce a straightforward method named Internal Spatial Modality Perception (ISMP) to explore the feature representation from internal views fully. Specifically, our proposed ISMP consists of a critical perception module, Spatial Insight Engine (SIE), which abstracts complex internal information of point clouds into essential global features. Besides, to better align structural information with point data, we propose an enhanced key point feature extraction module for amplifying spatial structure feature representation. Simultaneously, a novel feature filtering module is incorporated to reduce noise and redundant features for further aligning precise spatial structure. Extensive experiments validate the effectiveness of our proposed method, achieving object-level and pixel-level AUROC improvements of 4.2% and 13.1%, respectively, on the Real3D-AD benchmarks. Note that the strong generalization ability of SIE has been theoretically proven and is verified in both classification and segmentation tasks.
Motif Channel Opened in a White-Box: Stereo Matching via Motif Correlation Graph
Nov 19, 2024



Real-world applications of stereo matching, such as autonomous driving, place stringent demands on both safety and accuracy. However, learning-based stereo matching methods inherently suffer from the loss of geometric structures in certain feature channels, creating a bottleneck in achieving precise detail matching. Additionally, these methods lack interpretability due to the black-box nature of deep learning. In this paper, we propose MoCha-V2, a novel learning-based paradigm for stereo matching. MoCha-V2 introduces the Motif Correlation Graph (MCG) to capture recurring textures, which are referred to as ``motifs" within feature channels. These motifs reconstruct geometric structures and are learned in a more interpretable way. Subsequently, we integrate features from multiple frequency domains through wavelet inverse transformation. The resulting motif features are utilized to restore geometric structures in the stereo matching process. Experimental results demonstrate the effectiveness of MoCha-V2. MoCha-V2 achieved 1st place on the Middlebury benchmark at the time of its release. Code is available at https://github.com/ZYangChen/MoCha-Stereo.
MoCha-Stereo: Motif Channel Attention Network for Stereo Matching
Apr 11, 2024Learning-based stereo matching techniques have made significant progress. However, existing methods inevitably lose geometrical structure information during the feature channel generation process, resulting in edge detail mismatches. In this paper, the Motif Cha}nnel Attention Stereo Matching Network (MoCha-Stereo) is designed to address this problem. We provide the Motif Channel Correlation Volume (MCCV) to determine more accurate edge matching costs. MCCV is achieved by projecting motif channels, which capture common geometric structures in feature channels, onto feature maps and cost volumes. In addition, edge variations in %potential feature channels of the reconstruction error map also affect details matching, we propose the Reconstruction Error Motif Penalty (REMP) module to further refine the full-resolution disparity estimation. REMP integrates the frequency information of typical channel features from the reconstruction error. MoCha-Stereo ranks 1st on the KITTI-2015 and KITTI-2012 Reflective leaderboards. Our structure also shows excellent performance in Multi-View Stereo. Code is avaliable at https://github.com/ZYangChen/MoCha-Stereo.
* Accepted to CVPR 2024
SpirDet: Towards Efficient, Accurate and Lightweight Infrared Small Target Detector
Feb 08, 2024In recent years, the detection of infrared small targets using deep learning methods has garnered substantial attention due to notable advancements. To improve the detection capability of small targets, these methods commonly maintain a pathway that preserves high-resolution features of sparse and tiny targets. However, it can result in redundant and expensive computations. To tackle this challenge, we propose SpirDet, a novel approach for efficient detection of infrared small targets. Specifically, to cope with the computational redundancy issue, we employ a new dual-branch sparse decoder to restore the feature map. Firstly, the fast branch directly predicts a sparse map indicating potential small target locations (occupying only 0.5\% area of the map). Secondly, the slow branch conducts fine-grained adjustments at the positions indicated by the sparse map. Additionally, we design an lightweight DO-RepEncoder based on reparameterization with the Downsampling Orthogonality, which can effectively reduce memory consumption and inference latency. Extensive experiments show that the proposed SpirDet significantly outperforms state-of-the-art models while achieving faster inference speed and fewer parameters. For example, on the IRSTD-1K dataset, SpirDet improves $MIoU$ by 4.7 and has a $7\times$ $FPS$ acceleration compared to the previous state-of-the-art model. The code will be open to the public.
A Survey on Masked Facial Detection Methods and Datasets for Fighting Against COVID-19
Jan 13, 2022

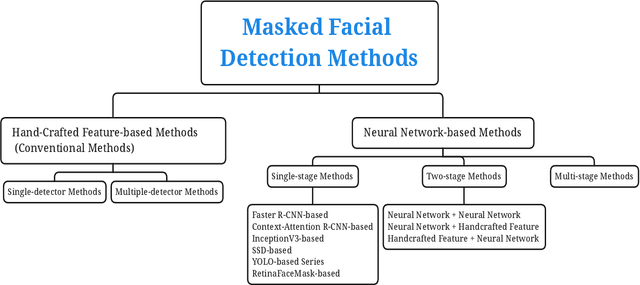

Coronavirus disease 2019 (COVID-19) continues to pose a great challenge to the world since its outbreak. To fight against the disease, a series of artificial intelligence (AI) techniques are developed and applied to real-world scenarios such as safety monitoring, disease diagnosis, infection risk assessment, lesion segmentation of COVID-19 CT scans,etc. The coronavirus epidemics have forced people wear masks to counteract the transmission of virus, which also brings difficulties to monitor large groups of people wearing masks. In this paper, we primarily focus on the AI techniques of masked facial detection and related datasets. We survey the recent advances, beginning with the descriptions of masked facial detection datasets. Thirteen available datasets are described and discussed in details. Then, the methods are roughly categorized into two classes: conventional methods and neural network-based methods. Conventional methods are usually trained by boosting algorithms with hand-crafted features, which accounts for a small proportion. Neural network-based methods are further classified as three parts according to the number of processing stages. Representative algorithms are described in detail, coupled with some typical techniques that are described briefly. Finally, we summarize the recent benchmarking results, give the discussions on the limitations of datasets and methods, and expand future research directions. To our knowledge, this is the first survey about masked facial detection methods and datasets. Hopefully our survey could provide some help to fight against epidemics.