 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesis4AD: Synthetic Anomalies are All You Need for 3D Anomaly Detection
Apr 06, 2026Industrial 3D anomaly detection performance is fundamentally constrained by the scarcity and long-tailed distribution of abnormal samples. To address this challenge, we propose Synthesis4AD, an end-to-end paradigm that leverages large-scale, high-fidelity synthetic anomalies to learn more discriminative representations for 3D anomaly detection. At the core of Synthesis4AD is 3D-DefectStudio, a software platform built upon the controllable synthesis engine MPAS, which injects geometrically realistic defects guided by higher-dimensional support primitives while simultaneously generating accurate point-wise anomaly masks. Furthermore, Synthesis4AD incorporates a multimodal large language model (MLLM) to interpret product design information and automatically translate it into executable anomaly synthesis instructions, enabling scalable and knowledge-driven anomalous data generation. To improve the robustness and generalization of the downstream detector on unstructured point clouds, Synthesis4AD further introduces a training pipeline based on spatial-distribution normalization and geometry-faithful data augmentations, which alleviates the sensitivity of Point Transformer architectures to absolute coordinates and improves feature learning under realistic data variations. Extensive experiments demonstrate state-of-the-art performance on Real3D-AD, MulSen-AD, and a real-world industrial parts dataset. The proposed synthesis method MPAS and the interactive system 3D-DefectStudio will be publicly released at https://github.com/hustCYQ/Synthesis4AD.
Towards an Incremental Unified Multimodal Anomaly Detection: Augmenting Multimodal Denoising From an Information Bottleneck Perspective
Mar 03, 2026The quest for incremental unified multimodal anomaly detection seeks to empower a single model with the ability to systematically detect anomalies across all categories and support incremental learning to accommodate emerging objects/categories. Central to this pursuit is resolving the catastrophic forgetting dilemma, which involves acquiring new knowledge while preserving prior learned knowledge. Despite some efforts to address this dilemma, a key oversight persists: ignoring the potential impact of spurious and redundant features on catastrophic forgetting. In this paper, we delve into the negative effect of spurious and redundant features on this dilemma in incremental unified frameworks, and reveal that under similar conditions, the multimodal framework developed by naive aggregation of unimodal architectures is more prone to forgetting. To address this issue, we introduce a novel denoising framework called IB-IUMAD, which exploits the complementary benefits of the Mamba decoder and information bottleneck fusion module: the former dedicated to disentangle inter-object feature coupling, preventing spurious feature interference between objects; the latter serves to filter out redundant features from the fused features, thus explicitly preserving discriminative information. A series of theoretical analyses and experiments on MVTec 3D-AD and Eyecandies datasets demonstrates the effectiveness and competitive performance of IB-IUMAD.
ASBench: Image Anomalies Synthesis Benchmark for Anomaly Detection
Oct 09, 2025Anomaly detection plays a pivotal role in manufacturing quality control, yet its application is constrained by limited abnormal samples and high manual annotation costs. While anomaly synthesis offers a promising solution, existing studies predominantly treat anomaly synthesis as an auxiliary component within anomaly detection frameworks, lacking systematic evaluation of anomaly synthesis algorithms. Current research also overlook crucial factors specific to anomaly synthesis, such as decoupling its impact from detection, quantitative analysis of synthetic data and adaptability across different scenarios. To address these limitations, we propose ASBench, the first comprehensive benchmarking framework dedicated to evaluating anomaly synthesis methods. Our framework introduces four critical evaluation dimensions: (i) the generalization performance across different datasets and pipelines (ii) the ratio of synthetic to real data (iii) the correlation between intrinsic metrics of synthesis images and anomaly detection performance metrics , and (iv) strategies for hybrid anomaly synthesis methods. Through extensive experiments, ASBench not only reveals limitations in current anomaly synthesis methods but also provides actionable insights for future research directions in anomaly synthesis
Trade-offs in Image Generation: How Do Different Dimensions Interact?
Jul 29, 2025Model performance in text-to-image (T2I) and image-to-image (I2I) generation often depends on multiple aspects, including quality, alignment, diversity, and robustness. However, models' complex trade-offs among these dimensions have rarely been explored due to (1) the lack of datasets that allow fine-grained quantification of these trade-offs, and (2) the use of a single metric for multiple dimensions. To bridge this gap, we introduce TRIG-Bench (Trade-offs in Image Generation), which spans 10 dimensions (Realism, Originality, Aesthetics, Content, Relation, Style, Knowledge, Ambiguity, Toxicity, and Bias), contains 40,200 samples, and covers 132 pairwise dimensional subsets. Furthermore, we develop TRIGScore, a VLM-as-judge metric that automatically adapts to various dimensions. Based on TRIG-Bench and TRIGScore, we evaluate 14 models across T2I and I2I tasks. In addition, we propose the Relation Recognition System to generate the Dimension Trade-off Map (DTM) that visualizes the trade-offs among model-specific capabilities. Our experiments demonstrate that DTM consistently provides a comprehensive understanding of the trade-offs between dimensions for each type of generative model. Notably, we show that the model's dimension-specific weaknesses can be mitigated through fine-tuning on DTM to enhance overall performance. Code is available at: https://github.com/fesvhtr/TRIG
Learning from Loss Landscape: Generalizable Mixed-Precision Quantization via Adaptive Sharpness-Aware Gradient Aligning
May 08, 2025Mixed Precision Quantization (MPQ) has become an essential technique for optimizing neural network by determining the optimal bitwidth per layer. Existing MPQ methods, however, face a major hurdle: they require a computationally expensive search for quantization policies on large-scale datasets. To resolve this issue, we introduce a novel approach that first searches for quantization policies on small datasets and then generalizes them to large-scale datasets. This approach simplifies the process, eliminating the need for large-scale quantization fine-tuning and only necessitating model weight adjustment. Our method is characterized by three key techniques: sharpness-aware minimization for enhanced quantization generalization, implicit gradient direction alignment to handle gradient conflicts among different optimization objectives, and an adaptive perturbation radius to accelerate optimization. Both theoretical analysis and experimental results validate our approach. Using the CIFAR10 dataset (just 0.5\% the size of ImageNet training data) for MPQ policy search, we achieved equivalent accuracy on ImageNet with a significantly lower computational cost, while improving efficiency by up to 150% over the baselines.
A Survey on Industrial Anomalies Synthesis
Feb 23, 2025This paper comprehensively reviews anomaly synthesis methodologies. Existing surveys focus on limited techniques, missing an overall field view and understanding method interconnections. In contrast, our study offers a unified review, covering about 40 representative methods across Hand-crafted, Distribution-hypothesis-based, Generative models (GM)-based, and Vision-language models (VLM)-based synthesis. We introduce the first industrial anomaly synthesis (IAS) taxonomy. Prior works lack formal classification or use simplistic taxonomies, hampering structured comparisons and trend identification. Our taxonomy provides a fine-grained framework reflecting methodological progress and practical implications, grounding future research. Furthermore, we explore cross-modality synthesis and large-scale VLM. Previous surveys overlooked multimodal data and VLM in anomaly synthesis, limiting insights into their advantages. Our survey analyzes their integration, benefits, challenges, and prospects, offering a roadmap to boost IAS with multimodal learning. More resources are available at https://github.com/M-3LAB/awesome-anomaly-synthesis.
Revisiting Multimodal Fusion for 3D Anomaly Detection from an Architectural Perspective
Dec 23, 2024Existing efforts to boost multimodal fusion of 3D anomaly detection (3D-AD) primarily concentrate on devising more effective multimodal fusion strategies. However, little attention was devoted to analyzing the role of multimodal fusion architecture (topology) design in contributing to 3D-AD. In this paper, we aim to bridge this gap and present a systematic study on the impact of multimodal fusion architecture design on 3D-AD. This work considers the multimodal fusion architecture design at the intra-module fusion level, i.e., independent modality-specific modules, involving early, middle or late multimodal features with specific fusion operations, and also at the inter-module fusion level, i.e., the strategies to fuse those modules. In both cases, we first derive insights through theoretically and experimentally exploring how architectural designs influence 3D-AD. Then, we extend SOTA neural architecture search (NAS) paradigm and propose 3D-ADNAS to simultaneously search across multimodal fusion strategies and modality-specific modules for the first time.Extensive experiments show that 3D-ADNAS obtains consistent improvements in 3D-AD across various model capacities in terms of accuracy, frame rate, and memory usage, and it exhibits great potential in dealing with few-shot 3D-AD tasks.
Look Inside for More: Internal Spatial Modality Perception for 3D Anomaly Detection
Dec 18, 2024



3D anomaly detection has recently become a significant focus in computer vision. Several advanced methods have achieved satisfying anomaly detection performance. However, they typically concentrate on the external structure of 3D samples and struggle to leverage the internal information embedded within samples. Inspired by the basic intuition of why not look inside for more, we introduce a straightforward method named Internal Spatial Modality Perception (ISMP) to explore the feature representation from internal views fully. Specifically, our proposed ISMP consists of a critical perception module, Spatial Insight Engine (SIE), which abstracts complex internal information of point clouds into essential global features. Besides, to better align structural information with point data, we propose an enhanced key point feature extraction module for amplifying spatial structure feature representation. Simultaneously, a novel feature filtering module is incorporated to reduce noise and redundant features for further aligning precise spatial structure. Extensive experiments validate the effectiveness of our proposed method, achieving object-level and pixel-level AUROC improvements of 4.2% and 13.1%, respectively, on the Real3D-AD benchmarks. Note that the strong generalization ability of SIE has been theoretically proven and is verified in both classification and segmentation tasks.
Towards High-resolution 3D Anomaly Detection via Group-Level Feature Contrastive Learning
Aug 08, 2024
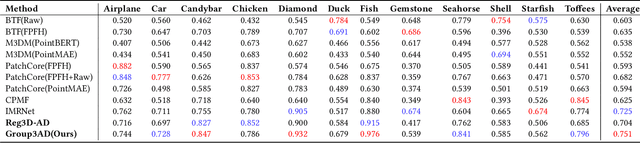
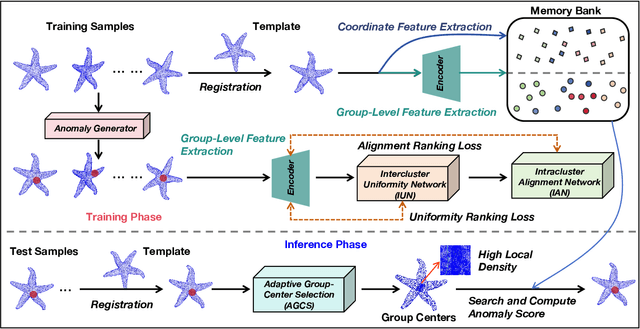

High-resolution point clouds~(HRPCD) anomaly detection~(AD) plays a critical role in precision machining and high-end equipment manufacturing. Despite considerable 3D-AD methods that have been proposed recently, they still cannot meet the requirements of the HRPCD-AD task. There are several challenges: i) It is difficult to directly capture HRPCD information due to large amounts of points at the sample level; ii) The advanced transformer-based methods usually obtain anisotropic features, leading to degradation of the representation; iii) The proportion of abnormal areas is very small, which makes it difficult to characterize. To address these challenges, we propose a novel group-level feature-based network, called Group3AD, which has a significantly efficient representation ability. First, we design an Intercluster Uniformity Network~(IUN) to present the mapping of different groups in the feature space as several clusters, and obtain a more uniform distribution between clusters representing different parts of the point clouds in the feature space. Then, an Intracluster Alignment Network~(IAN) is designed to encourage groups within the cluster to be distributed tightly in the feature space. In addition, we propose an Adaptive Group-Center Selection~(AGCS) based on geometric information to improve the pixel density of potential anomalous regions during inference. The experimental results verify the effectiveness of our proposed Group3AD, which surpasses Reg3D-AD by the margin of 5\% in terms of object-level AUROC on Real3D-AD. We provide the code and supplementary information on our website: https://github.com/M-3LAB/Group3AD.
Rethinking Unsupervised Outlier Detection via Multiple Thresholding
Jul 07, 2024



In the realm of unsupervised image outlier detection, assigning outlier scores holds greater significance than its subsequent task: thresholding for predicting labels. This is because determining the optimal threshold on non-separable outlier score functions is an ill-posed problem. However, the lack of predicted labels not only hiders some real applications of current outlier detectors but also causes these methods not to be enhanced by leveraging the dataset's self-supervision. To advance existing scoring methods, we propose a multiple thresholding (Multi-T) module. It generates two thresholds that isolate inliers and outliers from the unlabelled target dataset, whereas outliers are employed to obtain better feature representation while inliers provide an uncontaminated manifold. Extensive experiments verify that Multi-T can significantly improve proposed outlier scoring methods. Moreover, Multi-T contributes to a naive distance-based method being state-of-the-art.