 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Few-shot Demonstrations Affect Prompt-based Defenses Against LLM Jailbreak Attacks
Feb 04, 2026Large Language Models (LLMs) face increasing threats from jailbreak attacks that bypass safety alignment. While prompt-based defenses such as Role-Oriented Prompts (RoP) and Task-Oriented Prompts (ToP) have shown effectiveness, the role of few-shot demonstrations in these defense strategies remains unclear. Prior work suggests that few-shot examples may compromise safety, but lacks investigation into how few-shot interacts with different system prompt strategies. In this paper, we conduct a comprehensive evaluation on multiple mainstream LLMs across four safety benchmarks (AdvBench, HarmBench, SG-Bench, XSTest) using six jailbreak attack methods. Our key finding reveals that few-shot demonstrations produce opposite effects on RoP and ToP: few-shot enhances RoP's safety rate by up to 4.5% through reinforcing role identity, while it degrades ToP's effectiveness by up to 21.2% through distracting attention from task instructions. Based on these findings, we provide practical recommendations for deploying prompt-based defenses in real-world LLM applications.
Establishing Stochastic Object Models from Noisy Data via Ambient Measurement-Integrated Diffusion
Dec 16, 2025Task-based measures of image quality (IQ) are critical for evaluating medical imaging systems, which must account for randomness including anatomical variability. Stochastic object models (SOMs) provide a statistical description of such variability, but conventional mathematical SOMs fail to capture realistic anatomy, while data-driven approaches typically require clean data rarely available in clinical tasks. To address this challenge, we propose AMID, an unsupervised Ambient Measurement-Integrated Diffusion with noise decoupling, which establishes clean SOMs directly from noisy measurements. AMID introduces a measurement-integrated strategy aligning measurement noise with the diffusion trajectory, and explicitly models coupling between measurement and diffusion noise across steps, an ambient loss is thus designed base on it to learn clean SOMs. Experiments on real CT and mammography datasets show that AMID outperforms existing methods in generation fidelity and yields more reliable task-based IQ evaluation, demonstrating its potential for unsupervised medical imaging analysis.
A Survey on Industrial Anomalies Synthesis
Feb 23, 2025This paper comprehensively reviews anomaly synthesis methodologies. Existing surveys focus on limited techniques, missing an overall field view and understanding method interconnections. In contrast, our study offers a unified review, covering about 40 representative methods across Hand-crafted, Distribution-hypothesis-based, Generative models (GM)-based, and Vision-language models (VLM)-based synthesis. We introduce the first industrial anomaly synthesis (IAS) taxonomy. Prior works lack formal classification or use simplistic taxonomies, hampering structured comparisons and trend identification. Our taxonomy provides a fine-grained framework reflecting methodological progress and practical implications, grounding future research. Furthermore, we explore cross-modality synthesis and large-scale VLM. Previous surveys overlooked multimodal data and VLM in anomaly synthesis, limiting insights into their advantages. Our survey analyzes their integration, benefits, challenges, and prospects, offering a roadmap to boost IAS with multimodal learning. More resources are available at https://github.com/M-3LAB/awesome-anomaly-synthesis.
Art and Science of Quantizing Large-Scale Models: A Comprehensive Overview
Sep 18, 2024
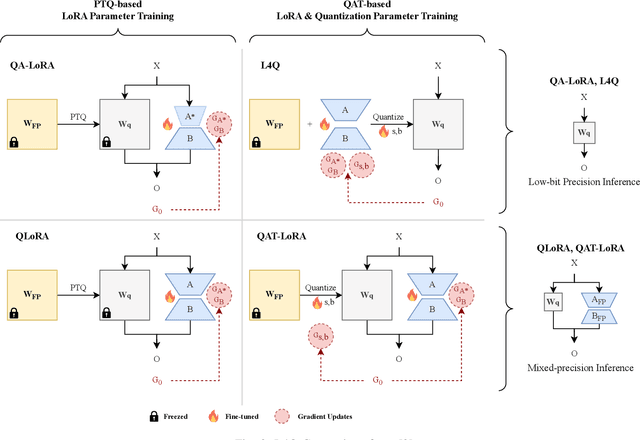


This paper provides a comprehensive overview of the principles, challenges, and methodologies associated with quantizing large-scale neural network models. As neural networks have evolved towards larger and more complex architectures to address increasingly sophisticated tasks, the computational and energy costs have escalated significantly. We explore the necessity and impact of model size growth, highlighting the performance benefits as well as the computational challenges and environmental considerations. The core focus is on model quantization as a fundamental approach to mitigate these challenges by reducing model size and improving efficiency without substantially compromising accuracy. We delve into various quantization techniques, including both post-training quantization (PTQ) and quantization-aware training (QAT), and analyze several state-of-the-art algorithms such as LLM-QAT, PEQA(L4Q), ZeroQuant, SmoothQuant, and others. Through comparative analysis, we examine how these methods address issues like outliers, importance weighting, and activation quantization, ultimately contributing to more sustainable and accessible deployment of large-scale models.
HERA: High-efficiency Matrix Compression via Element Replacement
Jul 04, 2024



Large Language Models (LLMs) have significantly advanced natural language processing tasks such as machine translation, text generation, and sentiment analysis. However, their large size, often consisting of billions of parameters, poses challenges for storage, computation, and deployment, particularly in resource-constrained environments like mobile devices and edge computing platforms. Additionally, the key-value (k-v) cache used to speed up query processing requires substantial memory and storage, exacerbating these challenges. Vector databases have emerged as a crucial technology to efficiently manage and retrieve the high-dimensional vectors produced by LLMs, facilitating faster data access and reducing computational demands. Effective compression and quantization techniques are essential to address these challenges, as they reduce the memory footprint and computational requirements without significantly compromising performance. Traditional methods that uniformly map parameters to compressed spaces often fail to account for the uneven distribution of parameters, leading to considerable accuracy loss. Therefore, innovative approaches are needed to achieve better compression ratios while preserving model performance. In this work, we propose HERA, a novel algorithm that employs heuristic Element Replacement for compressing matrix. HERA systematically replaces elements within the model using heuristic methods, which simplifies the structure of the model and makes subsequent compression more effective. By hierarchically segmenting, compressing, and reorganizing the matrix dataset, our method can effectively reduce the quantization error to 12.3% of the original at the same compression ratio.
Athena: Efficient Block-Wise Post-Training Quantization for Large Language Models Using Second-Order Matrix Derivative Information
May 24, 2024Large Language Models (LLMs) have significantly advanced natural language processing tasks such as machine translation, text generation, and sentiment analysis. However, their large size, often consisting of billions of parameters, poses challenges for storage, computation, and deployment, particularly in resource-constrained environments like mobile devices and edge computing platforms. Effective compression and quantization techniques are crucial for addressing these issues, reducing memory footprint and computational requirements without significantly compromising performance. Traditional methods that uniformly map parameters to compressed spaces fail to account for the uneven distribution of parameters, leading to substantial accuracy loss. In this work, we propose Athena, a novel algorithm for efficient block-wise post-training quantization of LLMs. Athena leverages Second-Order Matrix Derivative Information to guide the quantization process using the curvature information of the loss landscape. By grouping parameters by columns or rows and iteratively optimizing the quantization process, Athena updates the model parameters and Hessian matrix to achieve significant compression while maintaining high accuracy. This makes Athena a practical solution for deploying LLMs in various settings.