 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArt and Science of Quantizing Large-Scale Models: A Comprehensive Overview
Paper and Code
Sep 18, 2024
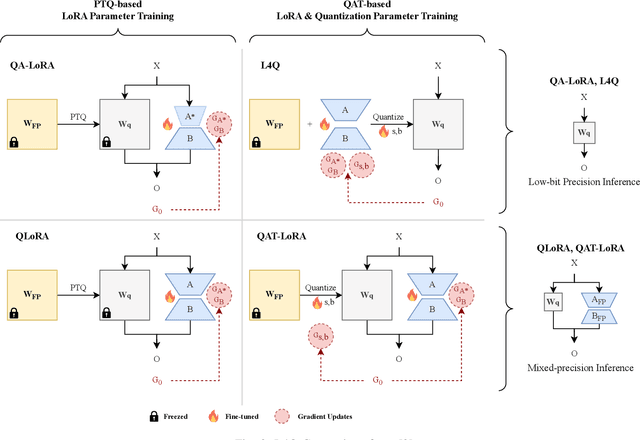


This paper provides a comprehensive overview of the principles, challenges, and methodologies associated with quantizing large-scale neural network models. As neural networks have evolved towards larger and more complex architectures to address increasingly sophisticated tasks, the computational and energy costs have escalated significantly. We explore the necessity and impact of model size growth, highlighting the performance benefits as well as the computational challenges and environmental considerations. The core focus is on model quantization as a fundamental approach to mitigate these challenges by reducing model size and improving efficiency without substantially compromising accuracy. We delve into various quantization techniques, including both post-training quantization (PTQ) and quantization-aware training (QAT), and analyze several state-of-the-art algorithms such as LLM-QAT, PEQA(L4Q), ZeroQuant, SmoothQuant, and others. Through comparative analysis, we examine how these methods address issues like outliers, importance weighting, and activation quantization, ultimately contributing to more sustainable and accessible deployment of large-scale models.