 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Physical Degradation Models to Task-Aware All-in-One Image Restoration
Jan 15, 2026All-in-one image restoration aims to adaptively handle multiple restoration tasks with a single trained model. Although existing methods achieve promising results by introducing prompt information or leveraging large models, the added learning modules increase system complexity and hinder real-time applicability. In this paper, we adopt a physical degradation modeling perspective and predict a task-aware inverse degradation operator for efficient all-in-one image restoration. The framework consists of two stages. In the first stage, the predicted inverse operator produces an initial restored image together with an uncertainty perception map that highlights regions difficult to reconstruct, ensuring restoration reliability. In the second stage, the restoration is further refined under the guidance of this uncertainty map. The same inverse operator prediction network is used in both stages, with task-aware parameters introduced after operator prediction to adapt to different degradation tasks. Moreover, by accelerating the convolution of the inverse operator, the proposed method achieves efficient all-in-one image restoration. The resulting tightly integrated architecture, termed OPIR, is extensively validated through experiments, demonstrating superior all-in-one restoration performance while remaining highly competitive on task-aligned restoration.
Establishing Stochastic Object Models from Noisy Data via Ambient Measurement-Integrated Diffusion
Dec 16, 2025Task-based measures of image quality (IQ) are critical for evaluating medical imaging systems, which must account for randomness including anatomical variability. Stochastic object models (SOMs) provide a statistical description of such variability, but conventional mathematical SOMs fail to capture realistic anatomy, while data-driven approaches typically require clean data rarely available in clinical tasks. To address this challenge, we propose AMID, an unsupervised Ambient Measurement-Integrated Diffusion with noise decoupling, which establishes clean SOMs directly from noisy measurements. AMID introduces a measurement-integrated strategy aligning measurement noise with the diffusion trajectory, and explicitly models coupling between measurement and diffusion noise across steps, an ambient loss is thus designed base on it to learn clean SOMs. Experiments on real CT and mammography datasets show that AMID outperforms existing methods in generation fidelity and yields more reliable task-based IQ evaluation, demonstrating its potential for unsupervised medical imaging analysis.
Physically Interpretable Multi-Degradation Image Restoration via Deep Unfolding and Explainable Convolution
Nov 13, 2025


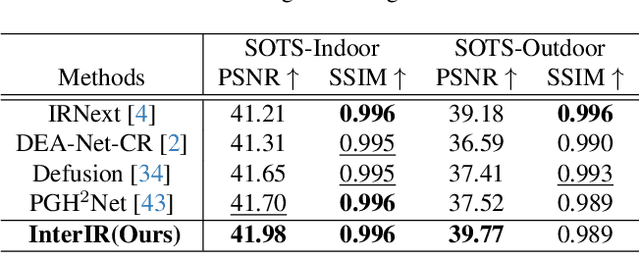
Although image restoration has advanced significantly, most existing methods target only a single type of degradation. In real-world scenarios, images often contain multiple degradations simultaneously, such as rain, noise, and haze, requiring models capable of handling diverse degradation types. Moreover, methods that improve performance through module stacking often suffer from limited interpretability. In this paper, we propose a novel interpretability-driven approach for multi-degradation image restoration, built upon a deep unfolding network that maps the iterative process of a mathematical optimization algorithm into a learnable network structure. Specifically, we employ an improved second-order semi-smooth Newton algorithm to ensure that each module maintains clear physical interpretability. To further enhance interpretability and adaptability, we design an explainable convolution module inspired by the human brain's flexible information processing and the intrinsic characteristics of images, allowing the network to flexibly leverage learned knowledge and autonomously adjust parameters for different input. The resulting tightly integrated architecture, named InterIR, demonstrates excellent performance in multi-degradation restoration while remaining highly competitive on single-degradation tasks.
Learning to Restore Multi-Degraded Images via Ingredient Decoupling and Task-Aware Path Adaptation
Nov 07, 2025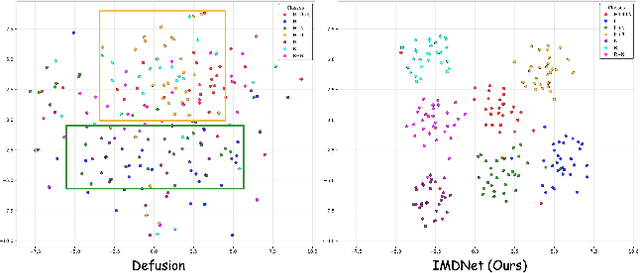
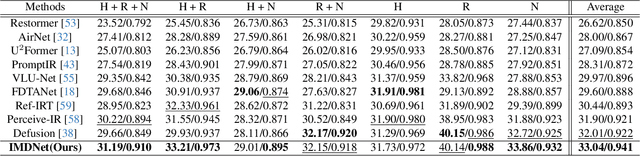
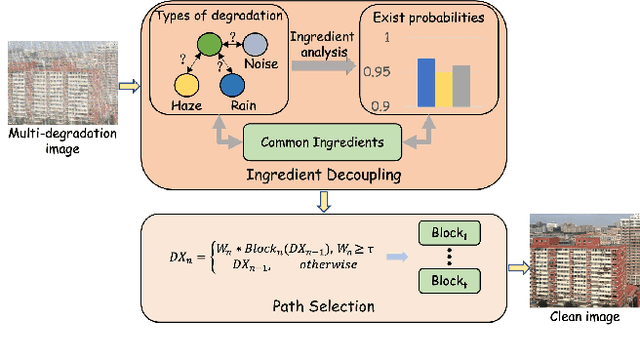
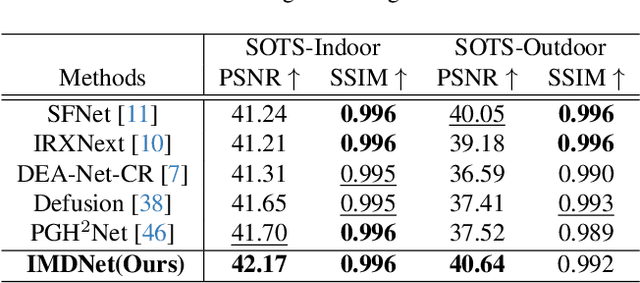
Image restoration (IR) aims to recover clean images from degraded observations. Despite remarkable progress, most existing methods focus on a single degradation type, whereas real-world images often suffer from multiple coexisting degradations, such as rain, noise, and haze coexisting in a single image, which limits their practical effectiveness. In this paper, we propose an adaptive multi-degradation image restoration network that reconstructs images by leveraging decoupled representations of degradation ingredients to guide path selection. Specifically, we design a degradation ingredient decoupling block (DIDBlock) in the encoder to separate degradation ingredients statistically by integrating spatial and frequency domain information, enhancing the recognition of multiple degradation types and making their feature representations independent. In addition, we present fusion block (FBlock) to integrate degradation information across all levels using learnable matrices. In the decoder, we further introduce a task adaptation block (TABlock) that dynamically activates or fuses functional branches based on the multi-degradation representation, flexibly selecting optimal restoration paths under diverse degradation conditions. The resulting tightly integrated architecture, termed IMDNet, is extensively validated through experiments, showing superior performance on multi-degradation restoration while maintaining strong competitiveness on single-degradation tasks.
ASBench: Image Anomalies Synthesis Benchmark for Anomaly Detection
Oct 09, 2025Anomaly detection plays a pivotal role in manufacturing quality control, yet its application is constrained by limited abnormal samples and high manual annotation costs. While anomaly synthesis offers a promising solution, existing studies predominantly treat anomaly synthesis as an auxiliary component within anomaly detection frameworks, lacking systematic evaluation of anomaly synthesis algorithms. Current research also overlook crucial factors specific to anomaly synthesis, such as decoupling its impact from detection, quantitative analysis of synthetic data and adaptability across different scenarios. To address these limitations, we propose ASBench, the first comprehensive benchmarking framework dedicated to evaluating anomaly synthesis methods. Our framework introduces four critical evaluation dimensions: (i) the generalization performance across different datasets and pipelines (ii) the ratio of synthetic to real data (iii) the correlation between intrinsic metrics of synthesis images and anomaly detection performance metrics , and (iv) strategies for hybrid anomaly synthesis methods. Through extensive experiments, ASBench not only reveals limitations in current anomaly synthesis methods but also provides actionable insights for future research directions in anomaly synthesis
A Survey on Industrial Anomalies Synthesis
Feb 23, 2025This paper comprehensively reviews anomaly synthesis methodologies. Existing surveys focus on limited techniques, missing an overall field view and understanding method interconnections. In contrast, our study offers a unified review, covering about 40 representative methods across Hand-crafted, Distribution-hypothesis-based, Generative models (GM)-based, and Vision-language models (VLM)-based synthesis. We introduce the first industrial anomaly synthesis (IAS) taxonomy. Prior works lack formal classification or use simplistic taxonomies, hampering structured comparisons and trend identification. Our taxonomy provides a fine-grained framework reflecting methodological progress and practical implications, grounding future research. Furthermore, we explore cross-modality synthesis and large-scale VLM. Previous surveys overlooked multimodal data and VLM in anomaly synthesis, limiting insights into their advantages. Our survey analyzes their integration, benefits, challenges, and prospects, offering a roadmap to boost IAS with multimodal learning. More resources are available at https://github.com/M-3LAB/awesome-anomaly-synthesis.
Semantic Data Augmentation for End-to-End Mandarin Speech Recognition
Apr 26, 2021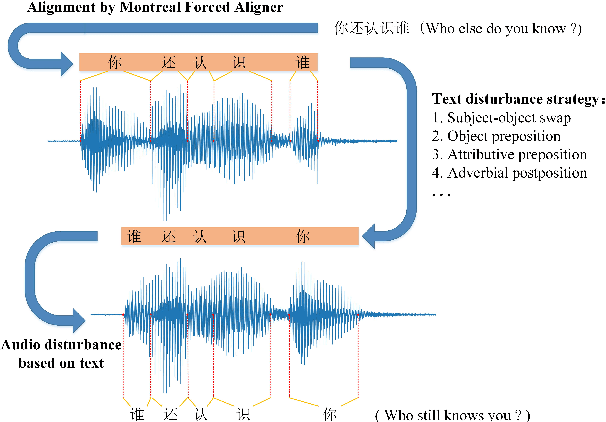


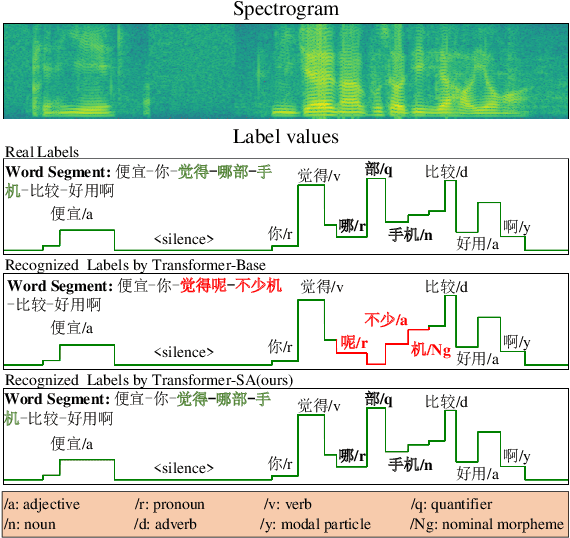
End-to-end models have gradually become the preferred option for automatic speech recognition (ASR) applications. During the training of end-to-end ASR, data augmentation is a quite effective technique for regularizing the neural networks. This paper proposes a novel data augmentation technique based on semantic transposition of the transcriptions via syntax rules for end-to-end Mandarin ASR. Specifically, we first segment the transcriptions based on part-of-speech tags. Then transposition strategies, such as placing the object in front of the subject or swapping the subject and the object, are applied on the segmented sentences. Finally, the acoustic features corresponding to the transposed transcription are reassembled based on the audio-to-text forced-alignment produced by a pre-trained ASR system. The combination of original data and augmented one is used for training a new ASR system. The experiments are conducted on the Transformer[2] and Conformer[3] based ASR. The results show that the proposed method can give consistent performance gain to the system. Augmentation related issues, such as comparison of different strategies and ratios for data combination are also investigated.
Improving Transformer-based Speech Recognition Using Unsupervised Pre-training
Oct 31, 2019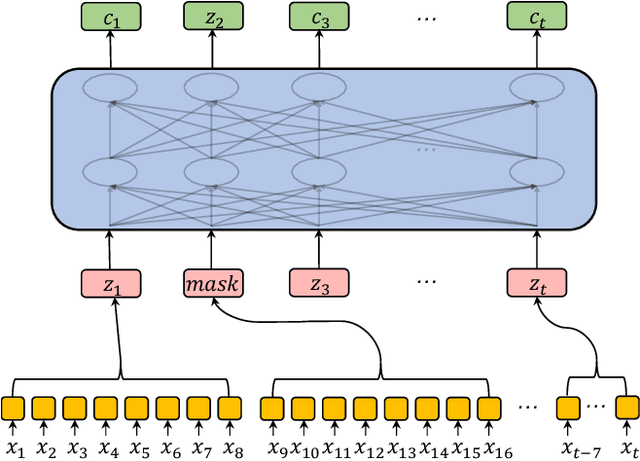
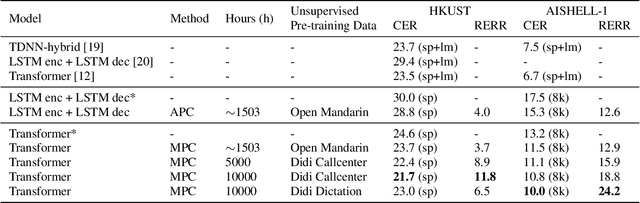
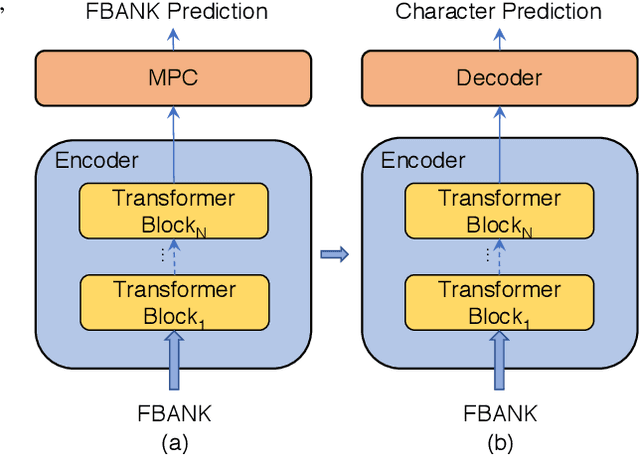
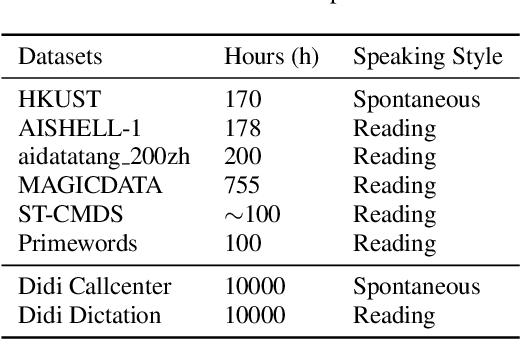
Speech recognition technologies are gaining enormous popularity in various industrial applications. However, building a good speech recognition system usually requires large amounts of transcribed data, which is expensive to collect. To tackle this problem, an unsupervised pre-training method called Masked Predictive Coding is proposed, which can be applied for unsupervised pre-training with Transformer based model. Experiments on HKUST show that using the same training data, we can achieve CER 23.3%, exceeding the best end-to-end model by over 0.2% absolute CER. With more pre-training data, we can further reduce the CER to 21.0%, or a 11.8% relative CER reduction over baseline.