 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArbor: Tree Search as a Cognition Layer for Autonomous Agents
Jun 10, 2026Arbor is a multi-agent framework that introduces structured tree search as a cognition layer for autonomous agents operating in large, stateful action spaces. Prior autonomous optimization systems operate on isolated targets with stateless evaluation. Arbor instead maintains an explicit search tree of scored hypotheses that serves as the shared working memory across agents, evolving with every measurement, treating failures as diagnostic signal that reshapes subsequent exploration, and expanding as prior successes shift the bottleneck distribution. We validate Arbor on full-stack LLM inference optimization, a domain where achieving peak performance has historically required coordinated effort from engineering teams across the application, framework, compiler, kernel, and hardware stack. Arbor pairs an Orchestrator agent, which drives optimization by delegating to Domain Specialists across the inference stack, with a Critic agent that safeguards stability through root-cause analysis, introspection, and measurement validation -- a checks-and-balances architecture where neither agent can unilaterally drive the system. Agent capabilities are decomposed into hard skills (domain expertise) and soft skills (coordination protocols that determine how contributions compose), enabling fully autonomous multi-day campaigns. Arbor achieves up to 193% inference throughput-latency Pareto improvement over vendor-optimized baselines, while a single agent without the harness plateaus at +33% throughput improvement and crashes irrecoverably within hours. Arbor generalizes to multiple generations of hardware platform, and run-to-run variance is within 2 percentage points demonstrating that the method is hardware-agnostic and reproducible.
KD-CVG: A Knowledge-Driven Approach for Creative Video Generation
Apr 23, 2026Creative Generation (CG) leverages generative models to automatically produce advertising content that highlights product features, and it has been a significant focus of recent research. However, while CG has advanced considerably, most efforts have concentrated on generating advertising text and images, leaving Creative Video Generation (CVG) relatively underexplored. This gap is largely due to two major challenges faced by Text-to-Video (T2V) models: (a) \textbf{ambiguous semantic alignment}, where models struggle to accurately correlate product selling points with creative video content, and (b) \textbf{inadequate motion adaptability}, resulting in unrealistic movements and distortions. To address these challenges, we develop a comprehensive Advertising Creative Knowledge Base (ACKB) as a foundational resource and propose a knowledge-driven approach (KD-CVG) to overcome the knowledge limitations of existing models. KD-CVG consists of two primary modules: Semantic-Aware Retrieval (SAR) and Multimodal Knowledge Reference (MKR). SAR utilizes the semantic awareness of graph attention networks and reinforcement learning feedback to enhance the model's comprehension of the connections between selling points and creative videos. Building on this, MKR incorporates semantic and motion priors into the T2V model to address existing knowledge gaps. Extensive experiments have demonstrated KD-CVG's superior performance in achieving semantic alignment and motion adaptability, validating its effectiveness over other state-of-the-art methods. The code and dataset will be open source at https://kdcvg.github.io/KDCVG/.
GTSR: Subsurface Scattering Awared 3D Gaussians for Translucent Surface Reconstruction
Mar 23, 2026Reconstructing translucent objects from multi-view images is a difficult problem. Previously, researchers have used differentiable path tracing and the neural implicit field, which require relatively large computational costs. Recently, many works have achieved good reconstruction results for opaque objects based on a 3DGS pipeline with much higher efficiency. However, such methods have difficulty dealing with translucent objects, because they do not consider the optical properties of translucent objects. In this paper, we propose a novel 3DGS-based pipeline (GTSR) to reconstruct the surface geometry of translucent objects. GTSR combines two sets of Gaussians, surface and interior Gaussians, which are used to model the surface and scattering color when lights pass translucent objects. To render the appearance of translucent objects, we introduce a method that uses the Fresnel term to blend two sets of Gaussians. Furthermore, to improve the reconstructed details of non-contour areas, we introduce the Disney BSDF model with deferred rendering to enhance constraints of the normal and depth. Experimental results demonstrate that our method outperforms baseline reconstruction methods on the NeuralTO Syn dataset while showing great real-time rendering performance. We also extend the dataset with new translucent objects of varying material properties and demonstrate our method can adapt to different translucent materials.
GEM: A Native Graph-based Index for Multi-Vector Retrieval
Mar 20, 2026In multi-vector retrieval, both queries and data are represented as sets of high-dimensional vectors, enabling finer-grained semantic matching and improving retrieval quality over single-vector approaches. However, its practical adoption is held back by the lack of effective indexing algorithms. Existing work, attempting to reuse standard single-vector indexes, often fails to preserve multi-vector semantics or remains slow. In this work, we present GEM, a native indexing framework for multi-vector representations. The core idea is to construct a proximity graph directly over vector sets, preserving their fine-grained semantics while enabling efficient navigation. First, GEM designs a set-level clustering scheme. It associates each vector set with only its most informative clusters, effectively reducing redundancy without hurting semantic coverage. Then, it builds local proximity graphs within clusters and bridges them into a globally navigable structure. To handle the non-metric nature of multi-vector similarity, GEM decouples the graph construction metric from the final relevance score and injects semantic shortcuts to guide efficient navigation toward relevant regions. At query time, GEM launches beam search from multiple entry points and prunes paths early using cluster cues. To further enhance efficiency, a quantized distance estimation technique is used for both indexing and search. Across in-domain, out-of-domain, and multi-modal benchmarks, GEM achieves up to 16x speedup over state-of-the-art methods while matching or improving accuracy.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Reasoning Palette: Modulating Reasoning via Latent Contextualization for Controllable Exploration for (V)LMs
Dec 19, 2025



Exploration capacity shapes both inference-time performance and reinforcement learning (RL) training for large (vision-) language models, as stochastic sampling often yields redundant reasoning paths with little high-level diversity. This paper proposes Reasoning Palette, a novel latent-modulation framework that endows the model with a stochastic latent variable for strategic contextualization, guiding its internal planning prior to token generation. This latent context is inferred from the mean-pooled embedding of a question-answer pair via a variational autoencoder (VAE), where each sampled latent potentially encodes a distinct reasoning context. During inference, a sampled latent is decoded into learnable token prefixes and prepended to the input prompt, modulating the model's internal reasoning trajectory. In this way, the model performs internal sampling over reasoning strategies prior to output generation, which shapes the style and structure of the entire response sequence. A brief supervised fine-tuning (SFT) warm-up phase allows the model to adapt to this latent conditioning. Within RL optimization, Reasoning Palette facilitates structured exploration by enabling on-demand injection for diverse reasoning modes, significantly enhancing exploration efficiency and sustained learning capability. Experiments across multiple reasoning benchmarks demonstrate that our method enables interpretable and controllable control over the (vision-) language model's strategic behavior, thereby achieving consistent performance gains over standard RL methods.
Beyond Training: Enabling Self-Evolution of Agents with MOBIMEM
Dec 15, 2025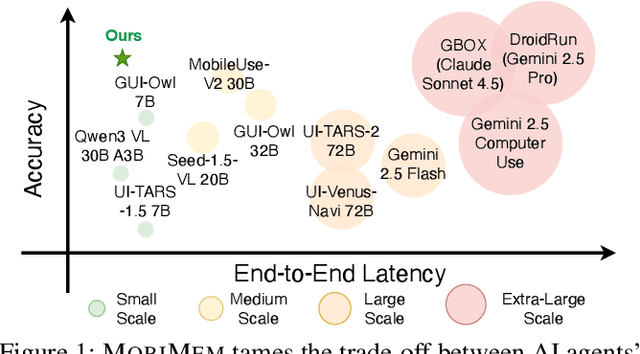
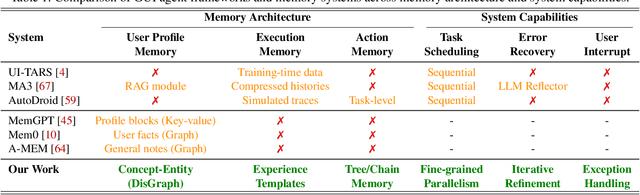
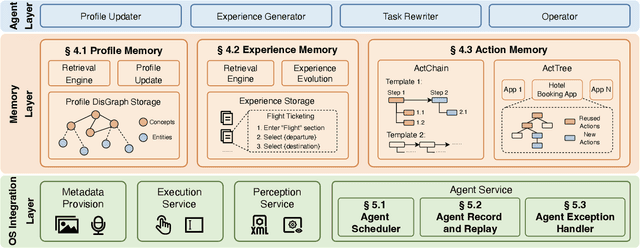
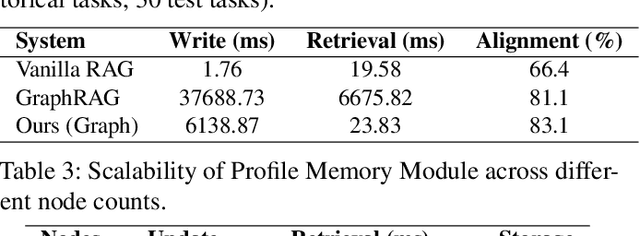
Large Language Model (LLM) agents are increasingly deployed to automate complex workflows in mobile and desktop environments. However, current model-centric agent architectures struggle to self-evolve post-deployment: improving personalization, capability, and efficiency typically requires continuous model retraining/fine-tuning, which incurs prohibitive computational overheads and suffers from an inherent trade-off between model accuracy and inference efficiency. To enable iterative self-evolution without model retraining, we propose MOBIMEM, a memory-centric agent system. MOBIMEM first introduces three specialized memory primitives to decouple agent evolution from model weights: (1) Profile Memory uses a lightweight distance-graph (DisGraph) structure to align with user preferences, resolving the accuracy-latency trade-off in user profile retrieval; (2) Experience Memory employs multi-level templates to instantiate execution logic for new tasks, ensuring capability generalization; and (3) Action Memory records fine-grained interaction sequences, reducing the reliance on expensive model inference. Building upon this memory architecture, MOBIMEM further integrates a suite of OS-inspired services to orchestrate execution: a scheduler that coordinates parallel sub-task execution and memory operations; an agent record-and-replay (AgentRR) mechanism that enables safe and efficient action reuse; and a context-aware exception handling that ensures graceful recovery from user interruptions and runtime errors. Evaluation on AndroidWorld and top-50 apps shows that MOBIMEM achieves 83.1% profile alignment with 23.83 ms retrieval time (280x faster than GraphRAG baselines), improves task success rates by up to 50.3%, and reduces end-to-end latency by up to 9x on mobile devices.
Bridging BCI and Communications: A MIMO Framework for EEG-to-ECoG Wireless Channel Modeling
May 16, 2025As a method to connect human brain and external devices, Brain-computer interfaces (BCIs) are receiving extensive research attention. Recently, the integration of communication theory with BCI has emerged as a popular trend, offering potential to enhance system performance and shape next-generation communications. A key challenge in this field is modeling the brain wireless communication channel between intracranial electrocorticography (ECoG) emitting neurons and extracranial electroencephalography (EEG) receiving electrodes. However, the complex physiology of brain challenges the application of traditional channel modeling methods, leaving relevant research in its infancy. To address this gap, we propose a frequency-division multiple-input multiple-output (MIMO) estimation framework leveraging simultaneous macaque EEG and ECoG recordings, while employing neurophysiology-informed regularization to suppress noise interference. This approach reveals profound similarities between neural signal propagation and multi-antenna communication systems. Experimental results show improved estimation accuracy over conventional methods while highlighting a trade-off between frequency resolution and temporal stability determined by signal duration. This work establish a conceptual bridge between neural interfacing and communication theory, accelerating synergistic developments in both fields.
PBR3DGen: A VLM-guided Mesh Generation with High-quality PBR Texture
Mar 14, 2025Generating high-quality physically based rendering (PBR) materials is important to achieve realistic rendering in the downstream tasks, yet it remains challenging due to the intertwined effects of materials and lighting. While existing methods have made breakthroughs by incorporating material decomposition in the 3D generation pipeline, they tend to bake highlights into albedo and ignore spatially varying properties of metallicity and roughness. In this work, we present PBR3DGen, a two-stage mesh generation method with high-quality PBR materials that integrates the novel multi-view PBR material estimation model and a 3D PBR mesh reconstruction model. Specifically, PBR3DGen leverages vision language models (VLM) to guide multi-view diffusion, precisely capturing the spatial distribution and inherent attributes of reflective-metalness material. Additionally, we incorporate view-dependent illumination-aware conditions as pixel-aware priors to enhance spatially varying material properties. Furthermore, our reconstruction model reconstructs high-quality mesh with PBR materials. Experimental results demonstrate that PBR3DGen significantly outperforms existing methods, achieving new state-of-the-art results for PBR estimation and mesh generation. More results and visualization can be found on our project page: https://pbr3dgen1218.github.io/.
Exploring the Meaningfulness of Nearest Neighbor Search in High-Dimensional Space
Oct 08, 2024Dense high dimensional vectors are becoming increasingly vital in fields such as computer vision, machine learning, and large language models (LLMs), serving as standard representations for multimodal data. Now the dimensionality of these vector can exceed several thousands easily. Despite the nearest neighbor search (NNS) over these dense high dimensional vectors have been widely used for retrieval augmented generation (RAG) and many other applications, the effectiveness of NNS in such a high-dimensional space remains uncertain, given the possible challenge caused by the "curse of dimensionality." To address above question, in this paper, we conduct extensive NNS studies with different distance functions, such as $L_1$ distance, $L_2$ distance and angular-distance, across diverse embedding datasets, of varied types, dimensionality and modality. Our aim is to investigate factors influencing the meaningfulness of NNS. Our experiments reveal that high-dimensional text embeddings exhibit increased resilience as dimensionality rises to higher levels when compared to random vectors. This resilience suggests that text embeddings are less affected to the "curse of dimensionality," resulting in more meaningful NNS outcomes for practical use. Additionally, the choice of distance function has minimal impact on the relevance of NNS. Our study shows the effectiveness of the embedding-based data representation method and can offer opportunity for further optimization of dense vector-related applications.