 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Online 3D Bin Packing with Lookahead Parcels Using Monte Carlo Tree Search
Jan 06, 2026Online 3D Bin Packing (3D-BP) with robotic arms is crucial for reducing transportation and labor costs in modern logistics. While Deep Reinforcement Learning (DRL) has shown strong performance, it often fails to adapt to real-world short-term distribution shifts, which arise as different batches of goods arrive sequentially, causing performance drops. We argue that the short-term lookahead information available in modern logistics systems is key to mitigating this issue, especially during distribution shifts. We formulate online 3D-BP with lookahead parcels as a Model Predictive Control (MPC) problem and adapt the Monte Carlo Tree Search (MCTS) framework to solve it. Our framework employs a dynamic exploration prior that automatically balances a learned RL policy and a robust random policy based on the lookahead characteristics. Additionally, we design an auxiliary reward to penalize long-term spatial waste from individual placements. Extensive experiments on real-world datasets show that our method consistently outperforms state-of-the-art baselines, achieving over 10\% gains under distributional shifts, 4\% average improvement in online deployment, and up to more than 8\% in the best case--demonstrating the effectiveness of our framework.
VHU-Net: Variational Hadamard U-Net for Body MRI Bias Field Correction
Jun 23, 2025Bias field artifacts in magnetic resonance imaging (MRI) scans introduce spatially smooth intensity inhomogeneities that degrade image quality and hinder downstream analysis. To address this challenge, we propose a novel variational Hadamard U-Net (VHU-Net) for effective body MRI bias field correction. The encoder comprises multiple convolutional Hadamard transform blocks (ConvHTBlocks), each integrating convolutional layers with a Hadamard transform (HT) layer. Specifically, the HT layer performs channel-wise frequency decomposition to isolate low-frequency components, while a subsequent scaling layer and semi-soft thresholding mechanism suppress redundant high-frequency noise. To compensate for the HT layer's inability to model inter-channel dependencies, the decoder incorporates an inverse HT-reconstructed transformer block, enabling global, frequency-aware attention for the recovery of spatially consistent bias fields. The stacked decoder ConvHTBlocks further enhance the capacity to reconstruct the underlying ground-truth bias field. Building on the principles of variational inference, we formulate a new evidence lower bound (ELBO) as the training objective, promoting sparsity in the latent space while ensuring accurate bias field estimation. Comprehensive experiments on abdominal and prostate MRI datasets demonstrate the superiority of VHU-Net over existing state-of-the-art methods in terms of intensity uniformity, signal fidelity, and tissue contrast. Moreover, the corrected images yield substantial downstream improvements in segmentation accuracy. Our framework offers computational efficiency, interpretability, and robust performance across multi-center datasets, making it suitable for clinical deployment.
Edge-Fog Computing-Enabled EEG Data Compression via Asymmetrical Variational Discrete Cosine Transform Network
Mar 13, 2025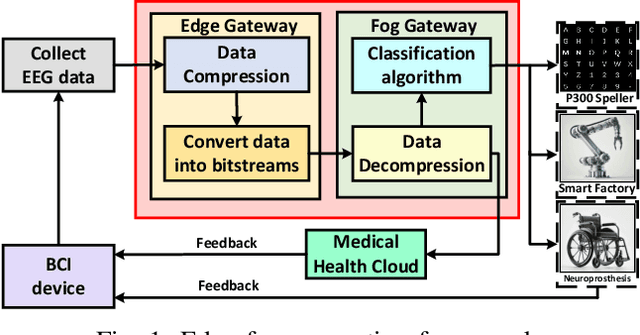
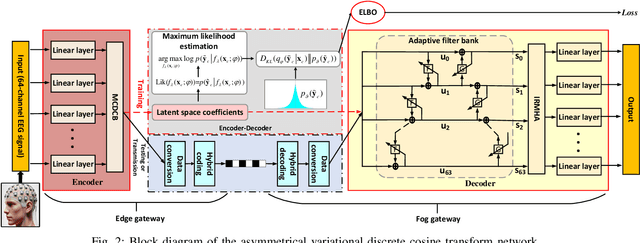
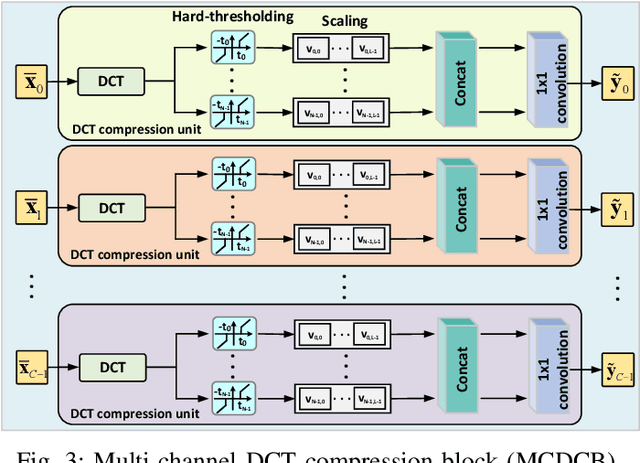
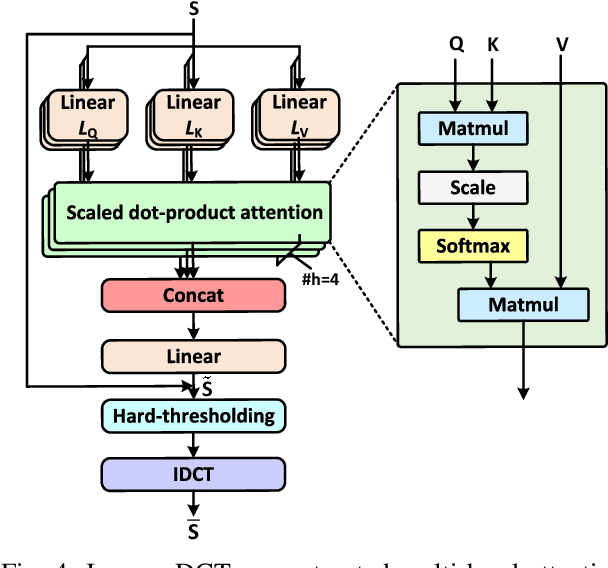
The large volume of electroencephalograph (EEG) data produced by brain-computer interface (BCI) systems presents challenges for rapid transmission over bandwidth-limited channels in Internet of Things (IoT) networks. To address the issue, we propose a novel multi-channel asymmetrical variational discrete cosine transform (DCT) network for EEG data compression within an edge-fog computing framework. At the edge level, low-complexity DCT compression units are designed using parallel trainable hard-thresholding and scaling operators to remove redundant data and extract the effective latent space representation. At the fog level, an adaptive filter bank is applied to merge important features from adjacent channels into each individual channel by leveraging inter-channel correlations. Then, the inverse DCT reconstructed multi-head attention is developed to capture both local and global dependencies and reconstruct the original signals. Furthermore, by applying the principles of variational inference, a new evidence lower bound is formulated as the loss function, driving the model to balance compression efficiency and reconstruction accuracy. Experimental results on two public datasets demonstrate that the proposed method achieves superior compression performance without sacrificing any useful information for BCI detection compared with state-of-the-art techniques, indicating a feasible solution for EEG data compression.
Efficient Bearing Sensor Data Compression via an Asymmetrical Autoencoder with a Lifting Wavelet Transform Layer
Jan 20, 2025Bearing data compression is vital to manage the large volumes of data generated during condition monitoring. In this paper, a novel asymmetrical autoencoder with a lifting wavelet transform (LWT) layer is developed to compress bearing sensor data. The encoder part of the network consists of a convolutional layer followed by a wavelet filterbank layer. Specifically, a dual-channel convolutional block with diverse convolutional kernel sizes and varying processing depths is integrated into the wavelet filterbank layer to enable comprehensive feature extraction from the wavelet domain. Additionally, the adaptive hard-thresholding nonlinearity is applied to remove redundant components while denoising the primary wavelet coefficients. On the decoder side, inverse LWT, along with multiple linear layers and activation functions, is employed to reconstruct the original signals. Furthermore, to enhance compression efficiency, a sparsity constraint is introduced during training to impose sparsity on the latent representations. The experimental results demonstrate that the proposed approach achieves superior data compression performance compared to state-of-the-art methods.
Towards Reliable Advertising Image Generation Using Human Feedback
Aug 01, 2024



In the e-commerce realm, compelling advertising images are pivotal for attracting customer attention. While generative models automate image generation, they often produce substandard images that may mislead customers and require significant labor costs to inspect. This paper delves into increasing the rate of available generated images. We first introduce a multi-modal Reliable Feedback Network (RFNet) to automatically inspect the generated images. Combining the RFNet into a recurrent process, Recurrent Generation, results in a higher number of available advertising images. To further enhance production efficiency, we fine-tune diffusion models with an innovative Consistent Condition regularization utilizing the feedback from RFNet (RFFT). This results in a remarkable increase in the available rate of generated images, reducing the number of attempts in Recurrent Generation, and providing a highly efficient production process without sacrificing visual appeal. We also construct a Reliable Feedback 1 Million (RF1M) dataset which comprises over one million generated advertising images annotated by human, which helps to train RFNet to accurately assess the availability of generated images and faithfully reflect the human feedback. Generally speaking, our approach offers a reliable solution for advertising image generation.
DCT-Based Decorrelated Attention for Vision Transformers
May 22, 2024



Central to the Transformer architectures' effectiveness is the self-attention mechanism, a function that maps queries, keys, and values into a high-dimensional vector space. However, training the attention weights of queries, keys, and values is non-trivial from a state of random initialization. In this paper, we propose two methods. (i) We first address the initialization problem of Vision Transformers by introducing a simple, yet highly innovative, initialization approach utilizing Discrete Cosine Transform (DCT) coefficients. Our proposed DCT-based attention initialization marks a significant gain compared to traditional initialization strategies; offering a robust foundation for the attention mechanism. Our experiments reveal that the DCT-based initialization enhances the accuracy of Vision Transformers in classification tasks. (ii) We also recognize that since DCT effectively decorrelates image information in the frequency domain, this decorrelation is useful for compression because it allows the quantization step to discard many of the higher-frequency components. Based on this observation, we propose a novel DCT-based compression technique for the attention function of Vision Transformers. Since high-frequency DCT coefficients usually correspond to noise, we truncate the high-frequency DCT components of the input patches. Our DCT-based compression reduces the size of weight matrices for queries, keys, and values. While maintaining the same level of accuracy, our DCT compressed Swin Transformers obtain a considerable decrease in the computational overhead.
A Probabilistic Hadamard U-Net for MRI Bias Field Correction
Mar 08, 2024Magnetic field inhomogeneity correction remains a challenging task in MRI analysis. Most established techniques are designed for brain MRI by supposing that image intensities in the identical tissue follow a uniform distribution. Such an assumption cannot be easily applied to other organs, especially those that are small in size and heterogeneous in texture (large variations in intensity), such as the prostate. To address this problem, this paper proposes a probabilistic Hadamard U-Net (PHU-Net) for prostate MRI bias field correction. First, a novel Hadamard U-Net (HU-Net) is introduced to extract the low-frequency scalar field, multiplied by the original input to obtain the prototypical corrected image. HU-Net converts the input image from the time domain into the frequency domain via Hadamard transform. In the frequency domain, high-frequency components are eliminated using the trainable filter (scaling layer), hard-thresholding layer, and sparsity penalty. Next, a conditional variational autoencoder is used to encode possible bias field-corrected variants into a low-dimensional latent space. Random samples drawn from latent space are then incorporated with a prototypical corrected image to generate multiple plausible images. Experimental results demonstrate the effectiveness of PHU-Net in correcting bias-field in prostate MRI with a fast inference speed. It has also been shown that prostate MRI segmentation accuracy improves with the high-quality corrected images from PHU-Net. The code will be available in the final version of this manuscript.
Generate E-commerce Product Background by Integrating Category Commonality and Personalized Style
Dec 20, 2023The state-of-the-art methods for e-commerce product background generation suffer from the inefficiency of designing product-wise prompts when scaling up the production, as well as the ineffectiveness of describing fine-grained styles when customizing personalized backgrounds for some specific brands. To address these obstacles, we integrate the category commonality and personalized style into diffusion models. Concretely, we propose a Category-Wise Generator to enable large-scale background generation for the first time. A unique identifier in the prompt is assigned to each category, whose attention is located on the background by a mask-guided cross attention layer to learn the category-wise style. Furthermore, for products with specific and fine-grained requirements in layout, elements, etc, a Personality-Wise Generator is devised to learn such personalized style directly from a reference image to resolve textual ambiguities, and is trained in a self-supervised manner for more efficient training data usage. To advance research in this field, the first large-scale e-commerce product background generation dataset BG60k is constructed, which covers more than 60k product images from over 2k categories. Experiments demonstrate that our method could generate high-quality backgrounds for different categories, and maintain the personalized background style of reference images. The link to BG60k and codes will be available soon.
Planning and Rendering: Towards End-to-End Product Poster Generation
Dec 14, 2023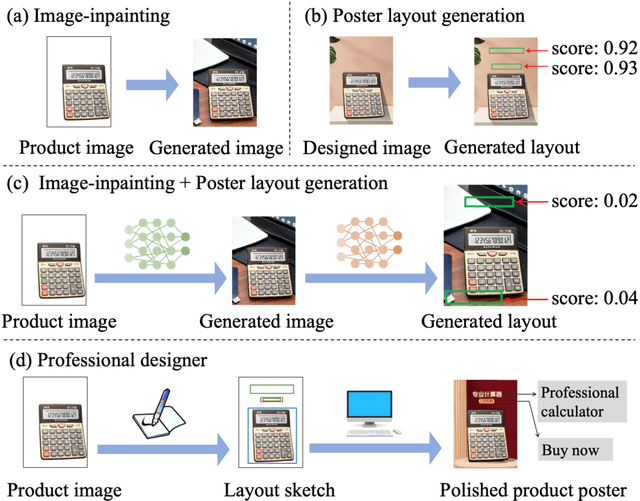
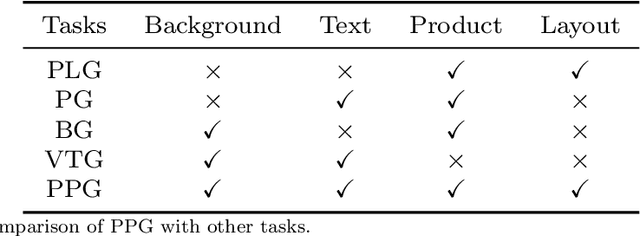
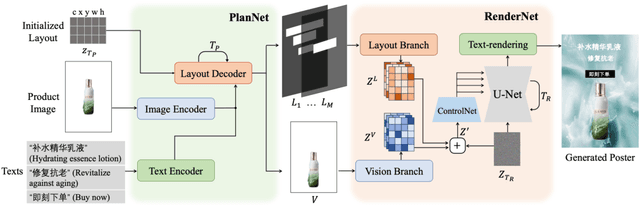
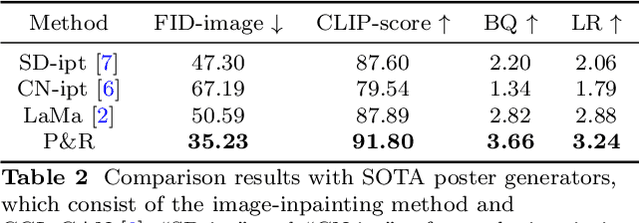
End-to-end product poster generation significantly optimizes design efficiency and reduces production costs. Prevailing methods predominantly rely on image-inpainting methods to generate clean background images for given products. Subsequently, poster layout generation methods are employed to produce corresponding layout results. However, the background images may not be suitable for accommodating textual content due to their complexity, and the fixed location of products limits the diversity of layout results. To alleviate these issues, we propose a novel product poster generation framework named P\&R. The P\&R draws inspiration from the workflow of designers in creating posters, which consists of two stages: Planning and Rendering. At the planning stage, we propose a PlanNet to generate the layout of the product and other visual components considering both the appearance features of the product and semantic features of the text, which improves the diversity and rationality of the layouts. At the rendering stage, we propose a RenderNet to generate the background for the product while considering the generated layout, where a spatial fusion module is introduced to fuse the layout of different visual components. To foster the advancement of this field, we propose the first end-to-end product poster generation dataset PPG30k, comprising 30k exquisite product poster images along with comprehensive image and text annotations. Our method outperforms the state-of-the-art product poster generation methods on PPG30k. The PPG30k will be released soon.
A novel asymmetrical autoencoder with a sparsifying discrete cosine Stockwell transform layer for gearbox sensor data compression
Oct 04, 2023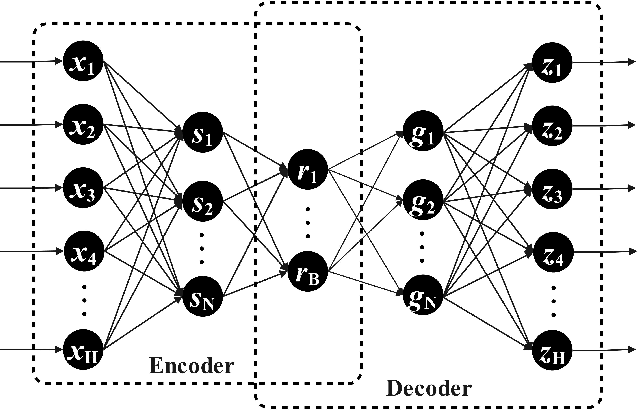


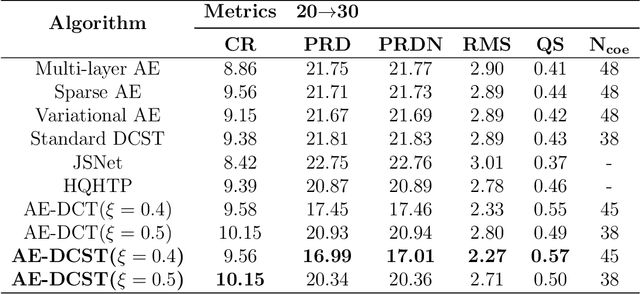
The lack of an efficient compression model remains a challenge for the wireless transmission of gearbox data in non-contact gear fault diagnosis problems. In this paper, we present a signal-adaptive asymmetrical autoencoder with a transform domain layer to compress sensor signals. First, a new discrete cosine Stockwell transform (DCST) layer is introduced to replace linear layers in a multi-layer autoencoder. A trainable filter is implemented in the DCST domain by utilizing the multiplication property of the convolution. A trainable hard-thresholding layer is applied to reduce redundant data in the DCST layer to make the feature map sparse. In comparison to the linear layer, the DCST layer reduces the number of trainable parameters and improves the accuracy of data reconstruction. Second, training the autoencoder with a sparsifying DCST layer only requires a small number of datasets. The proposed method is superior to other autoencoder-based methods on the University of Connecticut (UoC) and Southeast University (SEU) gearbox datasets, as the average quality score is improved by 2.00% at the lowest and 32.35% at the highest with a limited number of training samples