 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning and Rendering: Towards End-to-End Product Poster Generation
Dec 14, 2023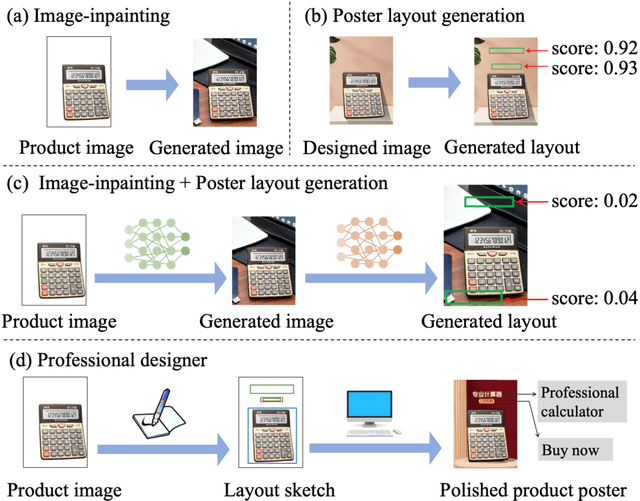
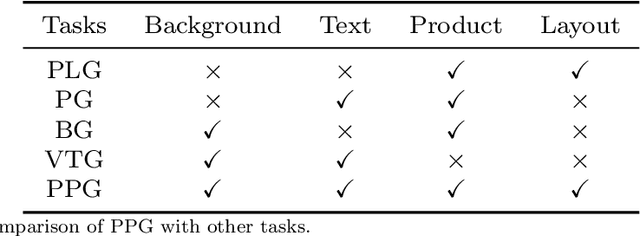
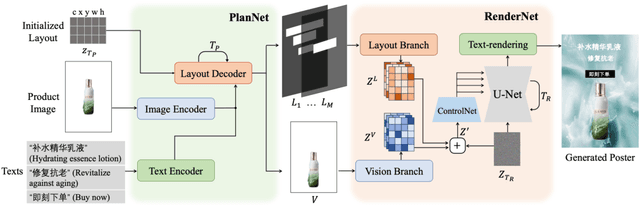
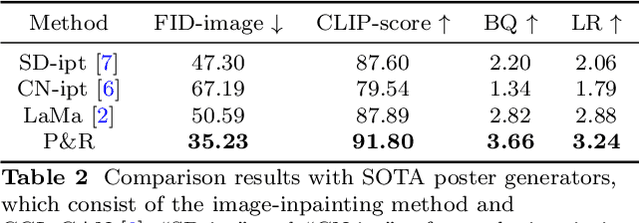
End-to-end product poster generation significantly optimizes design efficiency and reduces production costs. Prevailing methods predominantly rely on image-inpainting methods to generate clean background images for given products. Subsequently, poster layout generation methods are employed to produce corresponding layout results. However, the background images may not be suitable for accommodating textual content due to their complexity, and the fixed location of products limits the diversity of layout results. To alleviate these issues, we propose a novel product poster generation framework named P\&R. The P\&R draws inspiration from the workflow of designers in creating posters, which consists of two stages: Planning and Rendering. At the planning stage, we propose a PlanNet to generate the layout of the product and other visual components considering both the appearance features of the product and semantic features of the text, which improves the diversity and rationality of the layouts. At the rendering stage, we propose a RenderNet to generate the background for the product while considering the generated layout, where a spatial fusion module is introduced to fuse the layout of different visual components. To foster the advancement of this field, we propose the first end-to-end product poster generation dataset PPG30k, comprising 30k exquisite product poster images along with comprehensive image and text annotations. Our method outperforms the state-of-the-art product poster generation methods on PPG30k. The PPG30k will be released soon.
Relation-Aware Diffusion Model for Controllable Poster Layout Generation
Jun 15, 2023Poster layout is a crucial aspect of poster design. Prior methods primarily focus on the correlation between visual content and graphic elements. However, a pleasant layout should also consider the relationship between visual and textual contents and the relationship between elements. In this study, we introduce a relation-aware diffusion model for poster layout generation that incorporates these two relationships in the generation process. Firstly, we devise a visual-textual relation-aware module that aligns the visual and textual representations across modalities, thereby enhancing the layout's efficacy in conveying textual information. Subsequently, we propose a geometry relation-aware module that learns the geometry relationship between elements by comprehensively considering contextual information. Additionally, the proposed method can generate diverse layouts based on user constraints. To advance research in this field, we have constructed a poster layout dataset named CGL-Dataset V2. Our proposed method outperforms state-of-the-art methods on CGL-Dataset V2. The data and code will be available at https://github.com/liuan0803/RADM.
Physical Model Guided Deep Image Deraining
Mar 30, 2020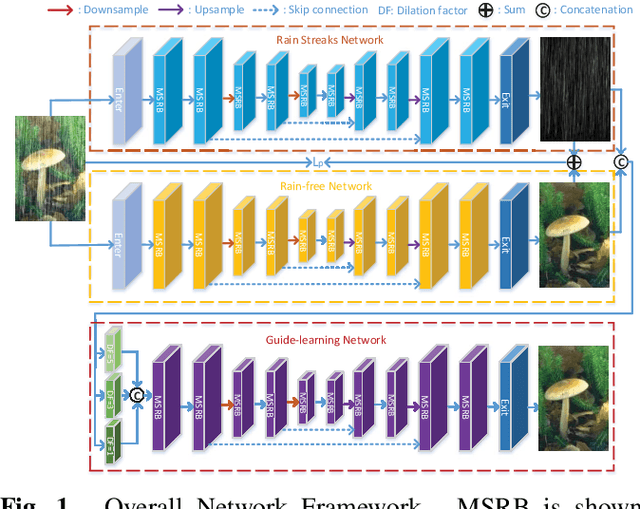
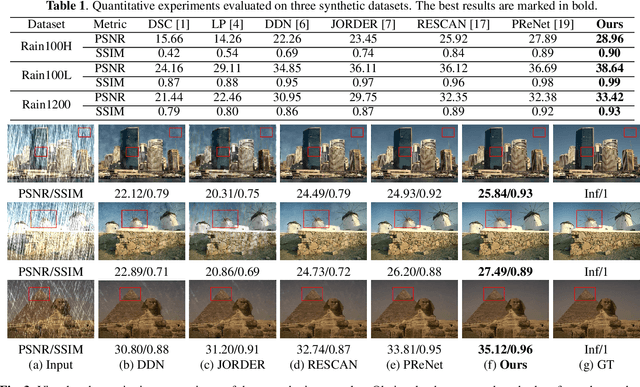
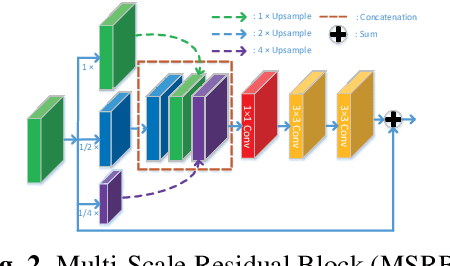
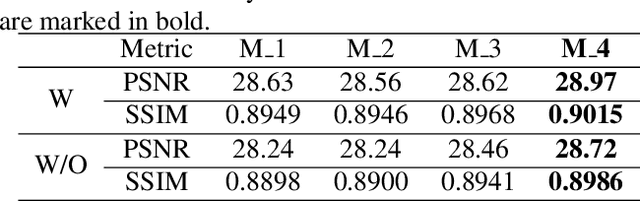
Single image deraining is an urgent task because the degraded rainy image makes many computer vision systems fail to work, such as video surveillance and autonomous driving. So, deraining becomes important and an effective deraining algorithm is needed. In this paper, we propose a novel network based on physical model guided learning for single image deraining, which consists of three sub-networks: rain streaks network, rain-free network, and guide-learning network. The concatenation of rain streaks and rain-free image that are estimated by rain streaks network, rain-free network, respectively, is input to the guide-learning network to guide further learning and the direct sum of the two estimated images is constrained with the input rainy image based on the physical model of rainy image. Moreover, we further develop the Multi-Scale Residual Block (MSRB) to better utilize multi-scale information and it is proved to boost the deraining performance. Quantitative and qualitative experimental results demonstrate that the proposed method outperforms the state-of-the-art deraining methods. The source code will be available at \url{https://supercong94.wixsite.com/supercong94}.