 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Large VLMs with Iterative and Manual Instructions for Generative Low-light Enhancement
Jul 24, 2025Most existing low-light image enhancement (LLIE) methods rely on pre-trained model priors, low-light inputs, or both, while neglecting the semantic guidance available from normal-light images. This limitation hinders their effectiveness in complex lighting conditions. In this paper, we propose VLM-IMI, a novel framework that leverages large vision-language models (VLMs) with iterative and manual instructions (IMIs) for LLIE. VLM-IMI incorporates textual descriptions of the desired normal-light content as enhancement cues, enabling semantically informed restoration. To effectively integrate cross-modal priors, we introduce an instruction prior fusion module, which dynamically aligns and fuses image and text features, promoting the generation of detailed and semantically coherent outputs. During inference, we adopt an iterative and manual instruction strategy to refine textual instructions, progressively improving visual quality. This refinement enhances structural fidelity, semantic alignment, and the recovery of fine details under extremely low-light conditions. Extensive experiments across diverse scenarios demonstrate that VLM-IMI outperforms state-of-the-art methods in both quantitative metrics and perceptual quality. The source code is available at https://github.com/sunxiaoran01/VLM-IMI.
Deep Learning-Driven Ultra-High-Definition Image Restoration: A Survey
May 22, 2025Ultra-high-definition (UHD) image restoration aims to specifically solve the problem of quality degradation in ultra-high-resolution images. Recent advancements in this field are predominantly driven by deep learning-based innovations, including enhancements in dataset construction, network architecture, sampling strategies, prior knowledge integration, and loss functions. In this paper, we systematically review recent progress in UHD image restoration, covering various aspects ranging from dataset construction to algorithm design. This serves as a valuable resource for understanding state-of-the-art developments in the field. We begin by summarizing degradation models for various image restoration subproblems, such as super-resolution, low-light enhancement, deblurring, dehazing, deraining, and desnowing, and emphasizing the unique challenges of their application to UHD image restoration. We then highlight existing UHD benchmark datasets and organize the literature according to degradation types and dataset construction methods. Following this, we showcase major milestones in deep learning-driven UHD image restoration, reviewing the progression of restoration tasks, technological developments, and evaluations of existing methods. We further propose a classification framework based on network architectures and sampling strategies, helping to clearly organize existing methods. Finally, we share insights into the current research landscape and propose directions for further advancements. A related repository is available at https://github.com/wlydlut/UHD-Image-Restoration-Survey.
Noise Calibration: Plug-and-play Content-Preserving Video Enhancement using Pre-trained Video Diffusion Models
Jul 14, 2024



In order to improve the quality of synthesized videos, currently, one predominant method involves retraining an expert diffusion model and then implementing a noising-denoising process for refinement. Despite the significant training costs, maintaining consistency of content between the original and enhanced videos remains a major challenge. To tackle this challenge, we propose a novel formulation that considers both visual quality and consistency of content. Consistency of content is ensured by a proposed loss function that maintains the structure of the input, while visual quality is improved by utilizing the denoising process of pretrained diffusion models. To address the formulated optimization problem, we have developed a plug-and-play noise optimization strategy, referred to as Noise Calibration. By refining the initial random noise through a few iterations, the content of original video can be largely preserved, and the enhancement effect demonstrates a notable improvement. Extensive experiments have demonstrated the effectiveness of the proposed method.
Ultra-High-Definition Restoration: New Benchmarks and A Dual Interaction Prior-Driven Solution
Jun 19, 2024Ultra-High-Definition (UHD) image restoration has acquired remarkable attention due to its practical demand. In this paper, we construct UHD snow and rain benchmarks, named UHD-Snow and UHD-Rain, to remedy the deficiency in this field. The UHD-Snow/UHD-Rain is established by simulating the physics process of rain/snow into consideration and each benchmark contains 3200 degraded/clear image pairs of 4K resolution. Furthermore, we propose an effective UHD image restoration solution by considering gradient and normal priors in model design thanks to these priors' spatial and detail contributions. Specifically, our method contains two branches: (a) feature fusion and reconstruction branch in high-resolution space and (b) prior feature interaction branch in low-resolution space. The former learns high-resolution features and fuses prior-guided low-resolution features to reconstruct clear images, while the latter utilizes normal and gradient priors to mine useful spatial features and detail features to guide high-resolution recovery better. To better utilize these priors, we introduce single prior feature interaction and dual prior feature interaction, where the former respectively fuses normal and gradient priors with high-resolution features to enhance prior ones, while the latter calculates the similarity between enhanced prior ones and further exploits dual guided filtering to boost the feature interaction of dual priors. We conduct experiments on both new and existing public datasets and demonstrate the state-of-the-art performance of our method on UHD image low-light enhancement, UHD image desonwing, and UHD image deraining. The source codes and benchmarks are available at \url{https://github.com/wlydlut/UHDDIP}.
LoLiSRFlow: Joint Single Image Low-light Enhancement and Super-resolution via Cross-scale Transformer-based Conditional Flow
Feb 29, 2024



The visibility of real-world images is often limited by both low-light and low-resolution, however, these issues are only addressed in the literature through Low-Light Enhancement (LLE) and Super- Resolution (SR) methods. Admittedly, a simple cascade of these approaches cannot work harmoniously to cope well with the highly ill-posed problem for simultaneously enhancing visibility and resolution. In this paper, we propose a normalizing flow network, dubbed LoLiSRFLow, specifically designed to consider the degradation mechanism inherent in joint LLE and SR. To break the bonds of the one-to-many mapping for low-light low-resolution images to normal-light high-resolution images, LoLiSRFLow directly learns the conditional probability distribution over a variety of feasible solutions for high-resolution well-exposed images. Specifically, a multi-resolution parallel transformer acts as a conditional encoder that extracts the Retinex-induced resolution-and-illumination invariant map as the previous one. And the invertible network maps the distribution of usually exposed high-resolution images to a latent distribution. The backward inference is equivalent to introducing an additional constrained loss for the normal training route, thus enabling the manifold of the natural exposure of the high-resolution image to be immaculately depicted. We also propose a synthetic dataset modeling the realistic low-light low-resolution degradation, named DFSR-LLE, containing 7100 low-resolution dark-light/high-resolution normal sharp pairs. Quantitative and qualitative experimental results demonstrate the effectiveness of our method on both the proposed synthetic and real datasets.
Learning A Coarse-to-Fine Diffusion Transformer for Image Restoration
Aug 29, 2023Recent years have witnessed the remarkable performance of diffusion models in various vision tasks. However, for image restoration that aims to recover clear images with sharper details from given degraded observations, diffusion-based methods may fail to recover promising results due to inaccurate noise estimation. Moreover, simple constraining noises cannot effectively learn complex degradation information, which subsequently hinders the model capacity. To solve the above problems, we propose a coarse-to-fine diffusion Transformer (C2F-DFT) for image restoration. Specifically, our C2F-DFT contains diffusion self-attention (DFSA) and diffusion feed-forward network (DFN) within a new coarse-to-fine training scheme. The DFSA and DFN respectively capture the long-range diffusion dependencies and learn hierarchy diffusion representation to facilitate better restoration. In the coarse training stage, our C2F-DFT estimates noises and then generates the final clean image by a sampling algorithm. To further improve the restoration quality, we propose a simple yet effective fine training scheme. It first exploits the coarse-trained diffusion model with fixed steps to generate restoration results, which then would be constrained with corresponding ground-truth ones to optimize the models to remedy the unsatisfactory results affected by inaccurate noise estimation. Extensive experiments show that C2F-DFT significantly outperforms diffusion-based restoration method IR-SDE and achieves competitive performance compared with Transformer-based state-of-the-art methods on $3$ tasks, including deraining, deblurring, and real denoising. The code is available at https://github.com/wlydlut/C2F-DFT.
Real-World Denoising via Diffusion Model
May 08, 2023Real-world image denoising is an extremely important image processing problem, which aims to recover clean images from noisy images captured in natural environments. In recent years, diffusion models have achieved very promising results in the field of image generation, outperforming previous generation models. However, it has not been widely used in the field of image denoising because it is difficult to control the appropriate position of the added noise. Inspired by diffusion models, this paper proposes a novel general denoising diffusion model that can be used for real-world image denoising. We introduce a diffusion process with linear interpolation, and the intermediate noisy image is interpolated from the original clean image and the corresponding real-world noisy image, so that this diffusion model can handle the level of added noise. In particular, we also introduce two sampling algorithms for this diffusion model. The first one is a simple sampling procedure defined according to the diffusion process, and the second one targets the problem of the first one and makes a number of improvements. Our experimental results show that our proposed method with a simple CNNs Unet achieves comparable results compared to the Transformer architecture. Both quantitative and qualitative evaluations on real-world denoising benchmarks show that the proposed general diffusion model performs almost as well as against the state-of-the-art methods.
Joint Self-Attention and Scale-Aggregation for Self-Calibrated Deraining Network
Aug 06, 2020



In the field of multimedia, single image deraining is a basic pre-processing work, which can greatly improve the visual effect of subsequent high-level tasks in rainy conditions. In this paper, we propose an effective algorithm, called JDNet, to solve the single image deraining problem and conduct the segmentation and detection task for applications. Specifically, considering the important information on multi-scale features, we propose a Scale-Aggregation module to learn the features with different scales. Simultaneously, Self-Attention module is introduced to match or outperform their convolutional counterparts, which allows the feature aggregation to adapt to each channel. Furthermore, to improve the basic convolutional feature transformation process of Convolutional Neural Networks (CNNs), Self-Calibrated convolution is applied to build long-range spatial and inter-channel dependencies around each spatial location that explicitly expand fields-of-view of each convolutional layer through internal communications and hence enriches the output features. By designing the Scale-Aggregation and Self-Attention modules with Self-Calibrated convolution skillfully, the proposed model has better deraining results both on real-world and synthetic datasets. Extensive experiments are conducted to demonstrate the superiority of our method compared with state-of-the-art methods. The source code will be available at \url{https://supercong94.wixsite.com/supercong94}.
DCSFN: Deep Cross-scale Fusion Network for Single Image Rain Removal
Aug 03, 2020


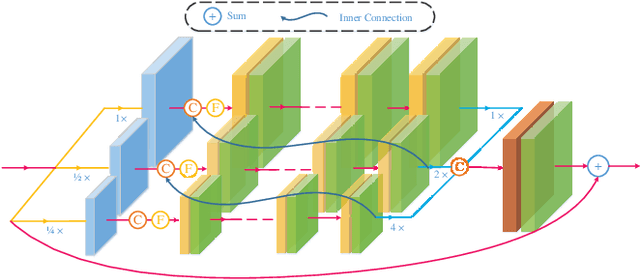
Rain removal is an important but challenging computer vision task as rain streaks can severely degrade the visibility of images that may make other visions or multimedia tasks fail to work. Previous works mainly focused on feature extraction and processing or neural network structure, while the current rain removal methods can already achieve remarkable results, training based on single network structure without considering the cross-scale relationship may cause information drop-out. In this paper, we explore the cross-scale manner between networks and inner-scale fusion operation to solve the image rain removal task. Specifically, to learn features with different scales, we propose a multi-sub-networks structure, where these sub-networks are fused via a crossscale manner by Gate Recurrent Unit to inner-learn and make full use of information at different scales in these sub-networks. Further, we design an inner-scale connection block to utilize the multi-scale information and features fusion way between different scales to improve rain representation ability and we introduce the dense block with skip connection to inner-connect these blocks. Experimental results on both synthetic and real-world datasets have demonstrated the superiority of our proposed method, which outperforms over the state-of-the-art methods. The source code will be available at https://supercong94.wixsite.com/supercong94.
Physical Model Guided Deep Image Deraining
Mar 30, 2020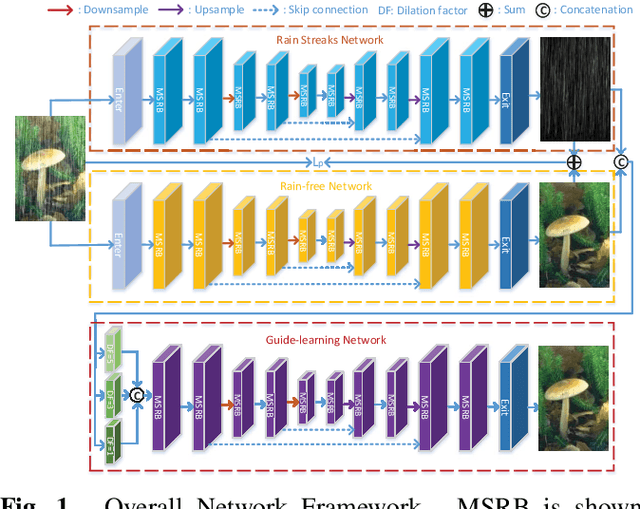
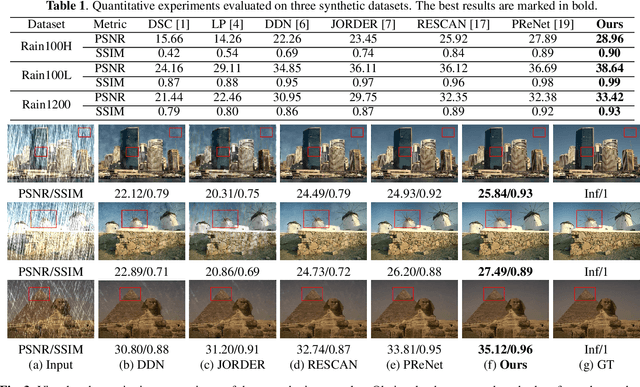
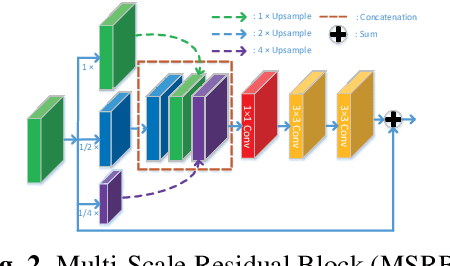
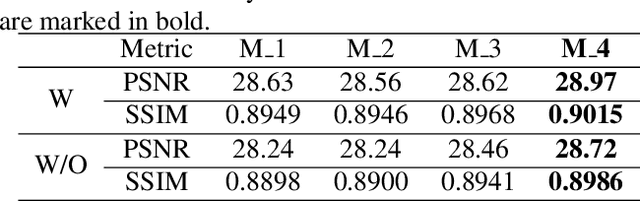
Single image deraining is an urgent task because the degraded rainy image makes many computer vision systems fail to work, such as video surveillance and autonomous driving. So, deraining becomes important and an effective deraining algorithm is needed. In this paper, we propose a novel network based on physical model guided learning for single image deraining, which consists of three sub-networks: rain streaks network, rain-free network, and guide-learning network. The concatenation of rain streaks and rain-free image that are estimated by rain streaks network, rain-free network, respectively, is input to the guide-learning network to guide further learning and the direct sum of the two estimated images is constrained with the input rainy image based on the physical model of rainy image. Moreover, we further develop the Multi-Scale Residual Block (MSRB) to better utilize multi-scale information and it is proved to boost the deraining performance. Quantitative and qualitative experimental results demonstrate that the proposed method outperforms the state-of-the-art deraining methods. The source code will be available at \url{https://supercong94.wixsite.com/supercong94}.