 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lossless Intra Reference Block Recompression Scheme for Bandwidth Reduction in HEVC-IBC
Apr 05, 2021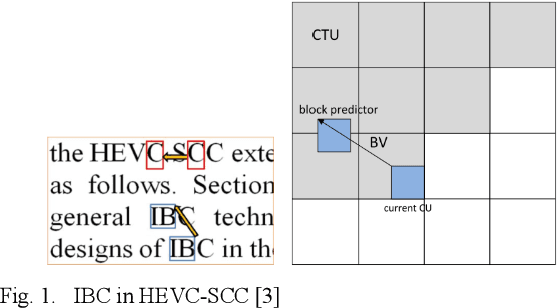
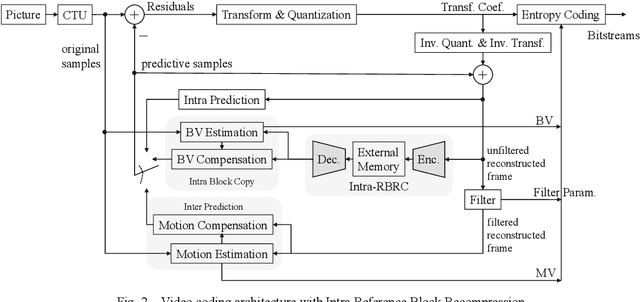
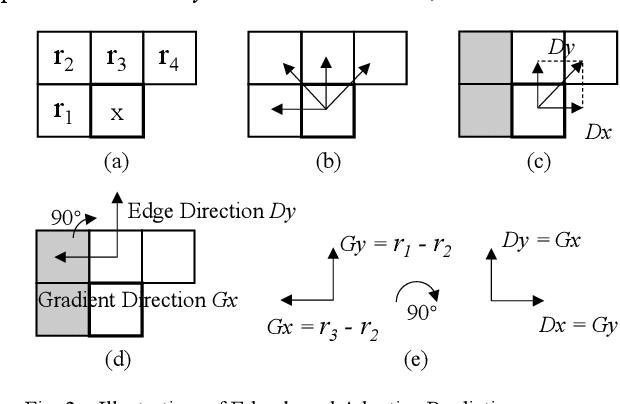
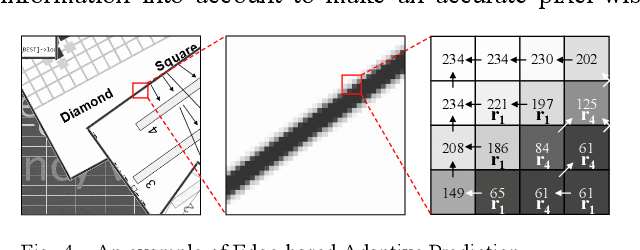
The reference frame memory accesses in inter prediction result in high DRAM bandwidth requirement and power consumption. This problem is more intensive by the adoption of intra block copy (IBC), a new coding tool in the screen content coding (SCC) extension to High Efficiency Video Coding (HEVC). In this paper, we propose a lossless recompression scheme that compresses the reference blocks in intra prediction, i.e., intra block copy, before storing them into DRAM to alleviate this problem. The proposal performs pixel-wise texture analysis with an edge-based adaptive prediction method yet no signaling for direction in bitstreams, thus achieves a high gain for compression. Experimental results demonstrate that the proposed scheme shows a 72% data reduction rate on average, which solves the memory bandwidth problem.
Switchable Temporal Propagation Network
May 04, 2018



Videos contain highly redundant information between frames. Such redundancy has been extensively studied in video compression and encoding, but is less explored for more advanced video processing. In this paper, we propose a learnable unified framework for propagating a variety of visual properties of video images, including but not limited to color, high dynamic range (HDR), and segmentation information, where the properties are available for only a few key-frames. Our approach is based on a temporal propagation network (TPN), which models the transition-related affinity between a pair of frames in a purely data-driven manner. We theoretically prove two essential factors for TPN: (a) by regularizing the global transformation matrix as orthogonal, the "style energy" of the property can be well preserved during propagation; (b) such regularization can be achieved by the proposed switchable TPN with bi-directional training on pairs of frames. We apply the switchable TPN to three tasks: colorizing a gray-scale video based on a few color key-frames, generating an HDR video from a low dynamic range (LDR) video and a few HDR frames, and propagating a segmentation mask from the first frame in videos. Experimental results show that our approach is significantly more accurate and efficient than the state-of-the-art methods.
Learning Video-Story Composition via Recurrent Neural Network
Jan 31, 2018
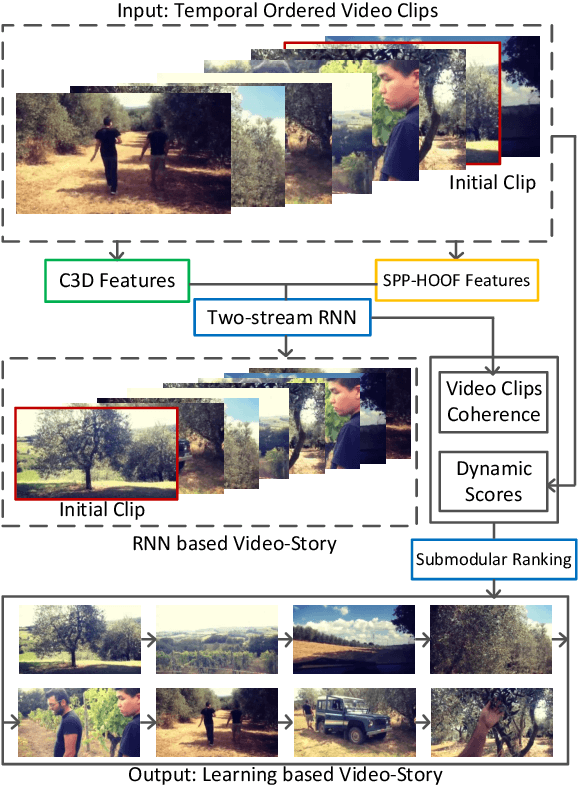
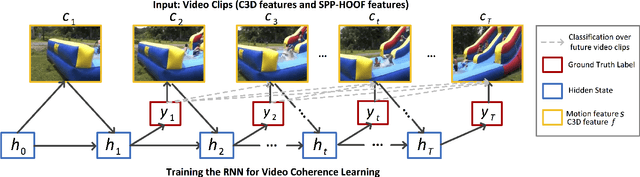

In this paper, we propose a learning-based method to compose a video-story from a group of video clips that describe an activity or experience. We learn the coherence between video clips from real videos via the Recurrent Neural Network (RNN) that jointly incorporates the spatial-temporal semantics and motion dynamics to generate smooth and relevant compositions. We further rearrange the results generated by the RNN to make the overall video-story compatible with the storyline structure via a submodular ranking optimization process. Experimental results on the video-story dataset show that the proposed algorithm outperforms the state-of-the-art approach.
Learning Affinity via Spatial Propagation Networks
Oct 03, 2017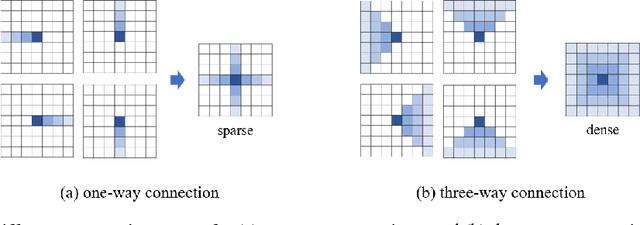
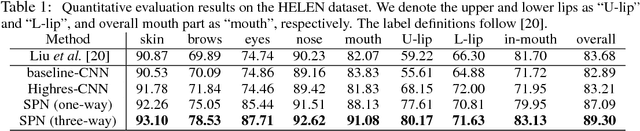
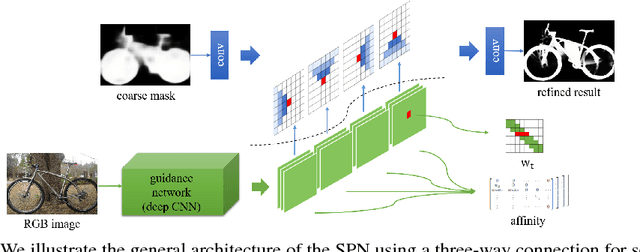

In this paper, we propose spatial propagation networks for learning the affinity matrix for vision tasks. We show that by constructing a row/column linear propagation model, the spatially varying transformation matrix exactly constitutes an affinity matrix that models dense, global pairwise relationships of an image. Specifically, we develop a three-way connection for the linear propagation model, which (a) formulates a sparse transformation matrix, where all elements can be the output from a deep CNN, but (b) results in a dense affinity matrix that effectively models any task-specific pairwise similarity matrix. Instead of designing the similarity kernels according to image features of two points, we can directly output all the similarities in a purely data-driven manner. The spatial propagation network is a generic framework that can be applied to many affinity-related tasks, including but not limited to image matting, segmentation and colorization, to name a few. Essentially, the model can learn semantically-aware affinity values for high-level vision tasks due to the powerful learning capability of the deep neural network classifier. We validate the framework on the task of refinement for image segmentation boundaries. Experiments on the HELEN face parsing and PASCAL VOC-2012 semantic segmentation tasks show that the spatial propagation network provides a general, effective and efficient solution for generating high-quality segmentation results.
Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos
Aug 07, 2017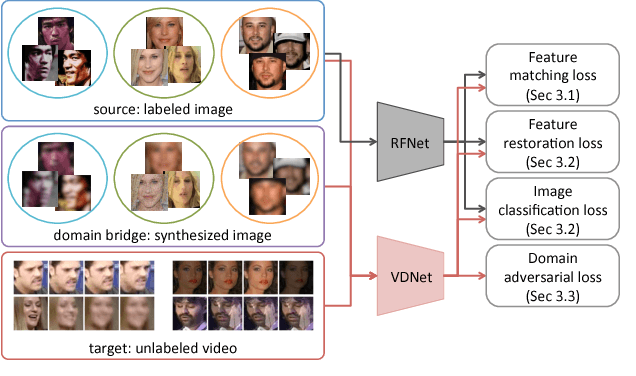
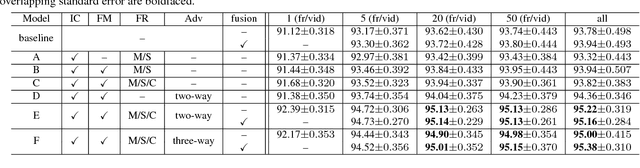
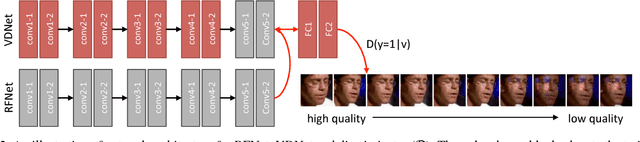
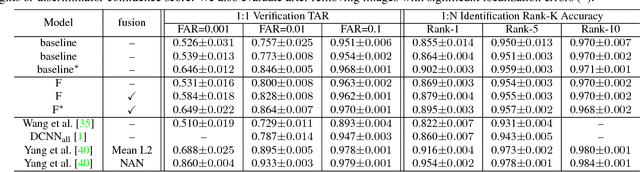
Despite rapid advances in face recognition, there remains a clear gap between the performance of still image-based face recognition and video-based face recognition, due to the vast difference in visual quality between the domains and the difficulty of curating diverse large-scale video datasets. This paper addresses both of those challenges, through an image to video feature-level domain adaptation approach, to learn discriminative video frame representations. The framework utilizes large-scale unlabeled video data to reduce the gap between different domains while transferring discriminative knowledge from large-scale labeled still images. Given a face recognition network that is pretrained in the image domain, the adaptation is achieved by (i) distilling knowledge from the network to a video adaptation network through feature matching, (ii) performing feature restoration through synthetic data augmentation and (iii) learning a domain-invariant feature through a domain adversarial discriminator. We further improve performance through a discriminator-guided feature fusion that boosts high-quality frames while eliminating those degraded by video domain-specific factors. Experiments on the YouTube Faces and IJB-A datasets demonstrate that each module contributes to our feature-level domain adaptation framework and substantially improves video face recognition performance to achieve state-of-the-art accuracy. We demonstrate qualitatively that the network learns to suppress diverse artifacts in videos such as pose, illumination or occlusion without being explicitly trained for them.