 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Sparse Pairwise Loss for Object Re-Identification
Mar 31, 2023



Object re-identification (ReID) aims to find instances with the same identity as the given probe from a large gallery. Pairwise losses play an important role in training a strong ReID network. Existing pairwise losses densely exploit each instance as an anchor and sample its triplets in a mini-batch. This dense sampling mechanism inevitably introduces positive pairs that share few visual similarities, which can be harmful to the training. To address this problem, we propose a novel loss paradigm termed Sparse Pairwise (SP) loss that only leverages few appropriate pairs for each class in a mini-batch, and empirically demonstrate that it is sufficient for the ReID tasks. Based on the proposed loss framework, we propose an adaptive positive mining strategy that can dynamically adapt to diverse intra-class variations. Extensive experiments show that SP loss and its adaptive variant AdaSP loss outperform other pairwise losses, and achieve state-of-the-art performance across several ReID benchmarks. Code is available at https://github.com/Astaxanthin/AdaSP.
DiP: Learning Discriminative Implicit Parts for Person Re-Identification
Dec 24, 2022



In person re-identification (ReID) tasks, many works explore the learning of part features to improve the performance over global image features. Existing methods extract part features in an explicit manner, by either using a hand-designed image division or keypoints obtained with external visual systems. In this work, we propose to learn Discriminative implicit Parts (DiPs) which are decoupled from explicit body parts. Therefore, DiPs can learn to extract any discriminative features that can benefit in distinguishing identities, which is beyond predefined body parts (such as accessories). Moreover, we propose a novel implicit position to give a geometric interpretation for each DiP. The implicit position can also serve as a learning signal to encourage DiPs to be more position-equivariant with the identity in the image. Lastly, a set of attributes and auxiliary losses are introduced to further improve the learning of DiPs. Extensive experiments show that the proposed method achieves state-of-the-art performance on multiple person ReID benchmarks.
Multiple Object Tracking Challenge Technical Report for Team MT_IoT
Dec 07, 2022This is a brief technical report of our proposed method for Multiple-Object Tracking (MOT) Challenge in Complex Environments. In this paper, we treat the MOT task as a two-stage task including human detection and trajectory matching. Specifically, we designed an improved human detector and associated most of detection to guarantee the integrity of the motion trajectory. We also propose a location-wise matching matrix to obtain more accurate trace matching. Without any model merging, our method achieves 66.672 HOTA and 93.971 MOTA on the DanceTrack challenge dataset.
SoccerNet 2022 Challenges Results
Oct 05, 2022



The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
Video Temporal Relationship Mining for Data-Efficient Person Re-identification
Oct 01, 2021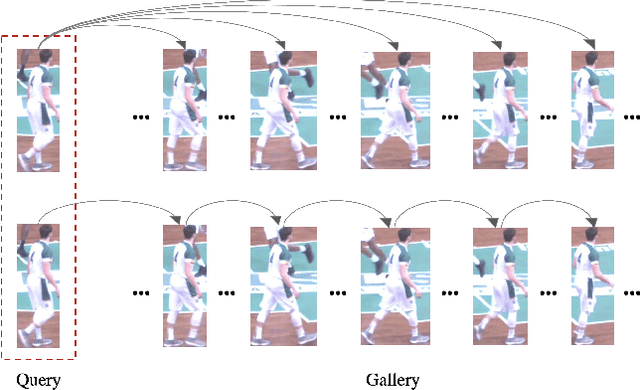
This paper is a technical report to our submission to the ICCV 2021 VIPriors Re-identification Challenge. In order to make full use of the visual inductive priors of the data, we treat the query and gallery images of the same identity as continuous frames in a video sequence. And we propose one novel post-processing strategy for video temporal relationship mining, which not only calculates the distance matrix between query and gallery images, but also the matrix between gallery images. The initial query image is used to retrieve the most similar image from the gallery, then the retrieved image is treated as a new query to retrieve its most similar image from the gallery. By iteratively searching for the closest image, we can achieve accurate image retrieval and finally obtain a robust retrieval sequence.
Learning Neural Templates for Recommender Dialogue System
Sep 25, 2021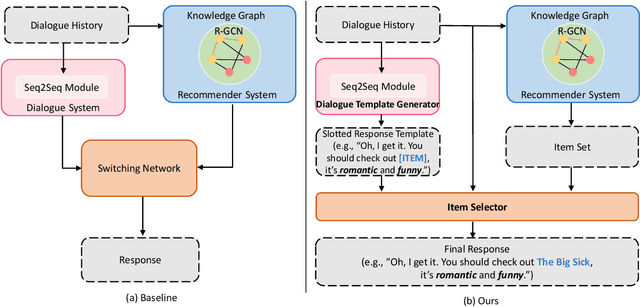

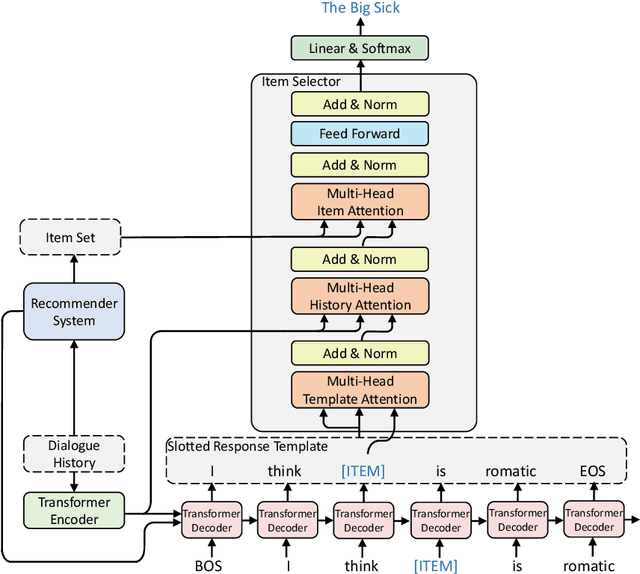

Though recent end-to-end neural models have shown promising progress on Conversational Recommender System (CRS), two key challenges still remain. First, the recommended items cannot be always incorporated into the generated replies precisely and appropriately. Second, only the items mentioned in the training corpus have a chance to be recommended in the conversation. To tackle these challenges, we introduce a novel framework called NTRD for recommender dialogue system that decouples the dialogue generation from the item recommendation. NTRD has two key components, i.e., response template generator and item selector. The former adopts an encoder-decoder model to generate a response template with slot locations tied to target items, while the latter fills in slot locations with the proper items using a sufficient attention mechanism. Our approach combines the strengths of both classical slot filling approaches (that are generally controllable) and modern neural NLG approaches (that are generally more natural and accurate). Extensive experiments on the benchmark ReDial show our NTRD significantly outperforms the previous state-of-the-art methods. Besides, our approach has the unique advantage to produce novel items that do not appear in the training set of dialogue corpus. The code is available at \url{https://github.com/jokieleung/NTRD}.
Maria: A Visual Experience Powered Conversational Agent
May 27, 2021
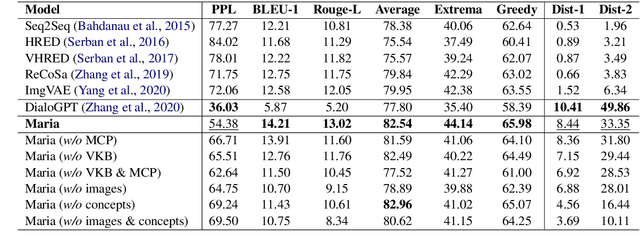
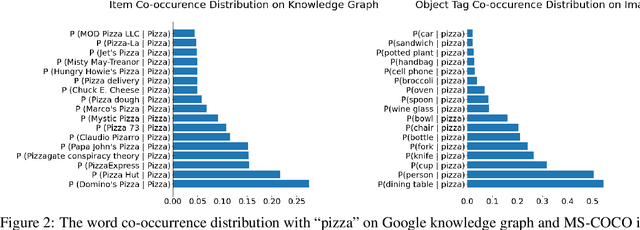
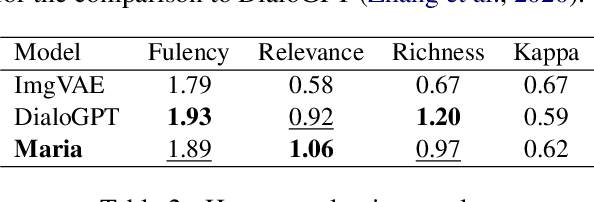
Arguably, the visual perception of conversational agents to the physical world is a key way for them to exhibit the human-like intelligence. Image-grounded conversation is thus proposed to address this challenge. Existing works focus on exploring the multimodal dialog models that ground the conversation on a given image. In this paper, we take a step further to study image-grounded conversation under a fully open-ended setting where no paired dialog and image are assumed available. Specifically, we present Maria, a neural conversation agent powered by the visual world experiences which are retrieved from a large-scale image index. Maria consists of three flexible components, i.e., text-to-image retriever, visual concept detector and visual-knowledge-grounded response generator. The retriever aims to retrieve a correlated image to the dialog from an image index, while the visual concept detector extracts rich visual knowledge from the image. Then, the response generator is grounded on the extracted visual knowledge and dialog context to generate the target response. Extensive experiments demonstrate Maria outperforms previous state-of-the-art methods on automatic metrics and human evaluation, and can generate informative responses that have some visual commonsense of the physical world.
A Lossless Intra Reference Block Recompression Scheme for Bandwidth Reduction in HEVC-IBC
Apr 05, 2021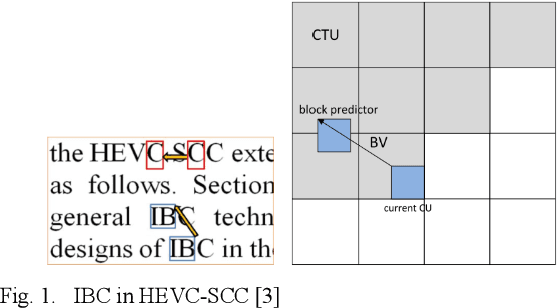
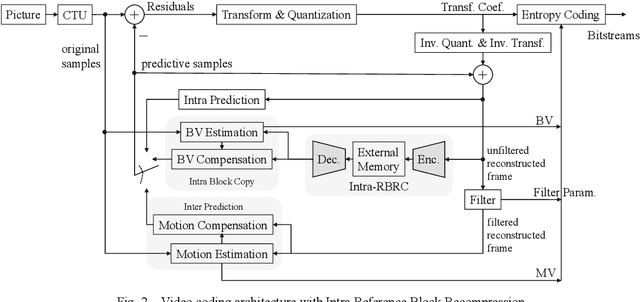
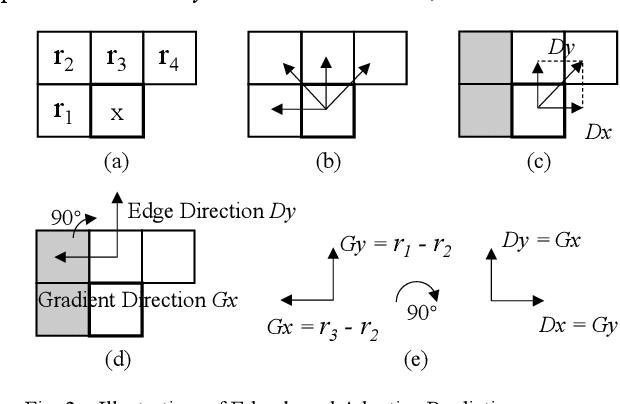
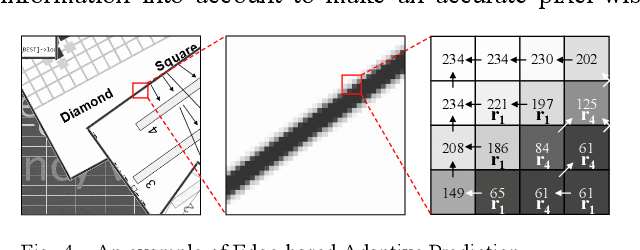
The reference frame memory accesses in inter prediction result in high DRAM bandwidth requirement and power consumption. This problem is more intensive by the adoption of intra block copy (IBC), a new coding tool in the screen content coding (SCC) extension to High Efficiency Video Coding (HEVC). In this paper, we propose a lossless recompression scheme that compresses the reference blocks in intra prediction, i.e., intra block copy, before storing them into DRAM to alleviate this problem. The proposal performs pixel-wise texture analysis with an edge-based adaptive prediction method yet no signaling for direction in bitstreams, thus achieves a high gain for compression. Experimental results demonstrate that the proposed scheme shows a 72% data reduction rate on average, which solves the memory bandwidth problem.