 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStylized Knowledge-Grounded Dialogue Generation via Disentangled Template Rewriting
Apr 12, 2022

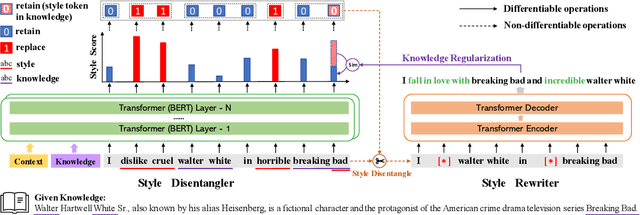
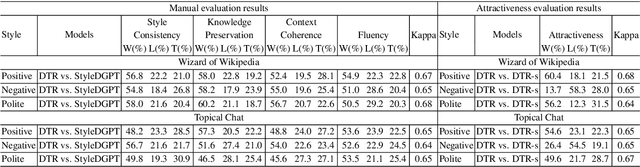
Current Knowledge-Grounded Dialogue Generation (KDG) models specialize in producing rational and factual responses. However, to establish long-term relationships with users, the KDG model needs the capability to generate responses in a desired style or attribute. Thus, we study a new problem: Stylized Knowledge-Grounded Dialogue Generation (SKDG). It presents two challenges: (1) How to train a SKDG model where no <context, knowledge, stylized response> triples are available. (2) How to cohere with context and preserve the knowledge when generating a stylized response. In this paper, we propose a novel disentangled template rewriting (DTR) method which generates responses via combing disentangled style templates (from monolingual stylized corpus) and content templates (from KDG corpus). The entire framework is end-to-end differentiable and learned without supervision. Extensive experiments on two benchmarks indicate that DTR achieves a significant improvement on all evaluation metrics compared with previous state-of-the-art stylized dialogue generation methods. Besides, DTR achieves comparable performance with the state-of-the-art KDG methods in standard KDG evaluation setting.
FORCE: A Framework of Rule-Based Conversational Recommender System
Mar 18, 2022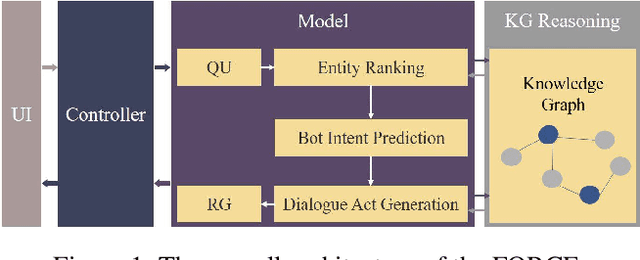
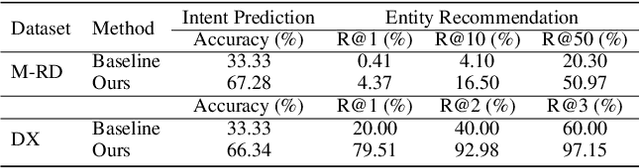
The conversational recommender systems (CRSs) have received extensive attention in recent years. However, most of the existing works focus on various deep learning models, which are largely limited by the requirement of large-scale human-annotated datasets. Such methods are not able to deal with the cold-start scenarios in industrial products. To alleviate the problem, we propose FORCE, a Framework Of Rule-based Conversational Recommender system that helps developers to quickly build CRS bots by simple configuration. We conduct experiments on two datasets in different languages and domains to verify its effectiveness and usability.
PromDA: Prompt-based Data Augmentation for Low-Resource NLU Tasks
Mar 17, 2022
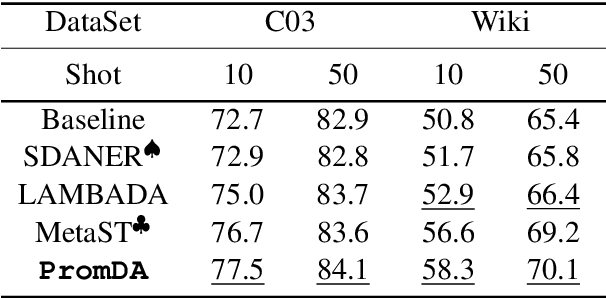


This paper focuses on the Data Augmentation for low-resource Natural Language Understanding (NLU) tasks. We propose Prompt-based D}ata Augmentation model (PromDA) which only trains small-scale Soft Prompt (i.e., a set of trainable vectors) in the frozen Pre-trained Language Models (PLMs). This avoids human effort in collecting unlabeled in-domain data and maintains the quality of generated synthetic data. In addition, PromDA generates synthetic data via two different views and filters out the low-quality data using NLU models. Experiments on four benchmarks show that synthetic data produced by PromDA successfully boost up the performance of NLU models which consistently outperform several competitive baseline models, including a state-of-the-art semi-supervised model using unlabeled in-domain data. The synthetic data from PromDA are also complementary with unlabeled in-domain data. The NLU models can be further improved when they are combined for training.
TegTok: Augmenting Text Generation via Task-specific and Open-world Knowledge
Mar 16, 2022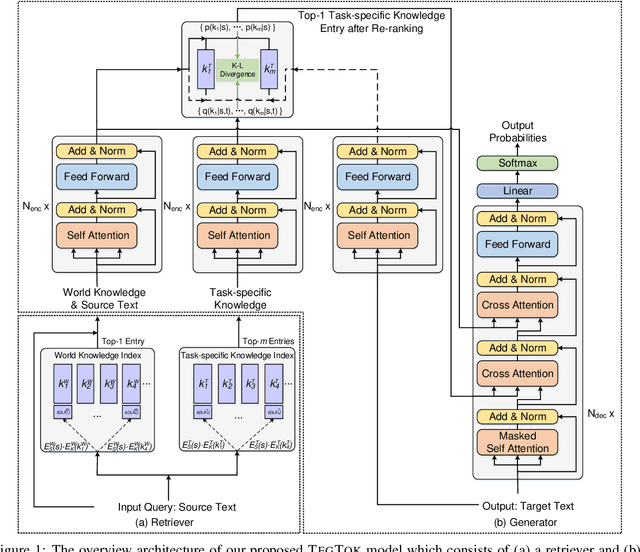
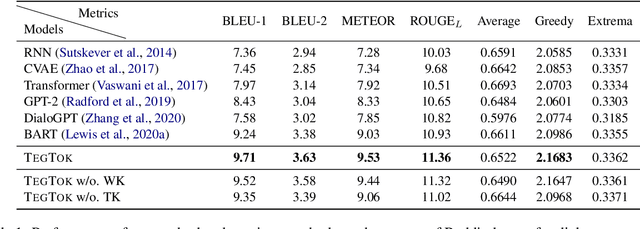
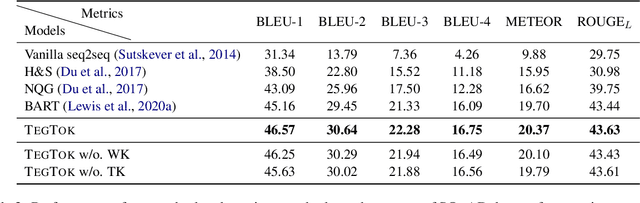
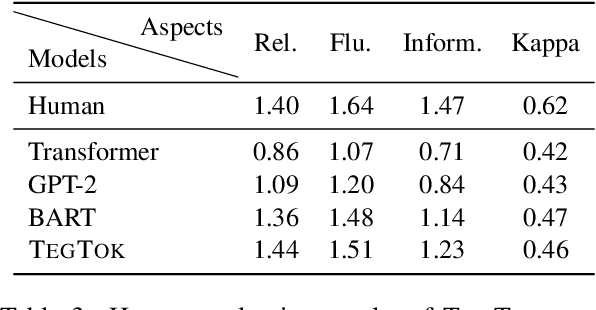
Generating natural and informative texts has been a long-standing problem in NLP. Much effort has been dedicated into incorporating pre-trained language models (PLMs) with various open-world knowledge, such as knowledge graphs or wiki pages. However, their ability to access and manipulate the task-specific knowledge is still limited on downstream tasks, as this type of knowledge is usually not well covered in PLMs and is hard to acquire. To address the problem, we propose augmenting TExt Generation via Task-specific and Open-world Knowledge (TegTok) in a unified framework. Our model selects knowledge entries from two types of knowledge sources through dense retrieval and then injects them into the input encoding and output decoding stages respectively on the basis of PLMs. With the help of these two types of knowledge, our model can learn what and how to generate. Experiments on two text generation tasks of dialogue generation and question generation, and on two datasets show that our method achieves better performance than various baseline models.
HeterMPC: A Heterogeneous Graph Neural Network for Response Generation in Multi-Party Conversations
Mar 16, 2022
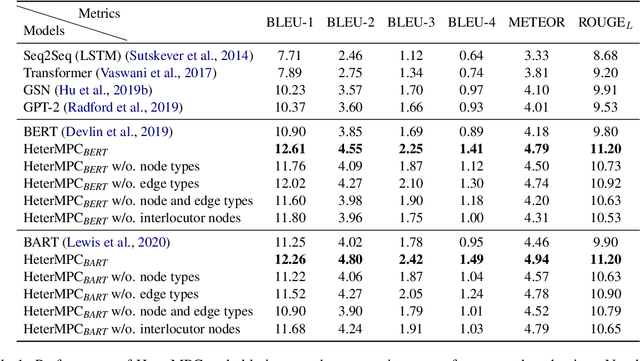
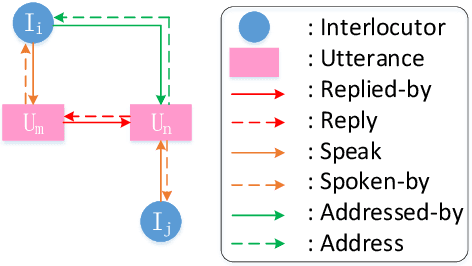
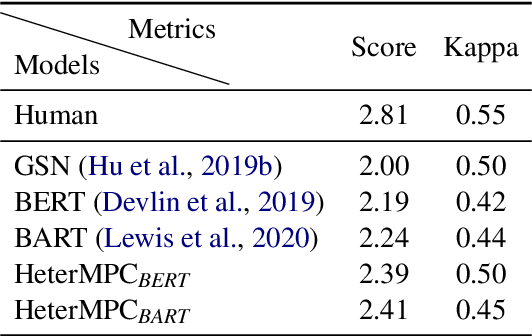
Recently, various response generation models for two-party conversations have achieved impressive improvements, but less effort has been paid to multi-party conversations (MPCs) which are more practical and complicated. Compared with a two-party conversation where a dialogue context is a sequence of utterances, building a response generation model for MPCs is more challenging, since there exist complicated context structures and the generated responses heavily rely on both interlocutors (i.e., speaker and addressee) and history utterances. To address these challenges, we present HeterMPC, a heterogeneous graph-based neural network for response generation in MPCs which models the semantics of utterances and interlocutors simultaneously with two types of nodes in a graph. Besides, we also design six types of meta relations with node-edge-type-dependent parameters to characterize the heterogeneous interactions within the graph. Through multi-hop updating, HeterMPC can adequately utilize the structural knowledge of conversations for response generation. Experimental results on the Ubuntu Internet Relay Chat (IRC) channel benchmark show that HeterMPC outperforms various baseline models for response generation in MPCs.
Small Changes Make Big Differences: Improving Multi-turn Response Selection in Dialogue Systems via Fine-Grained Contrastive Learning
Nov 25, 2021
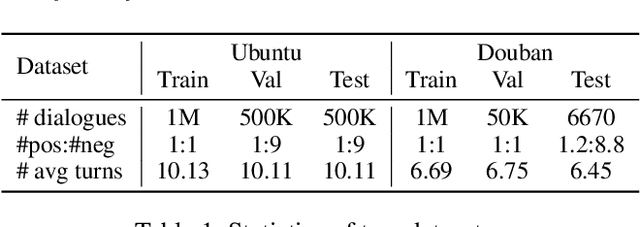
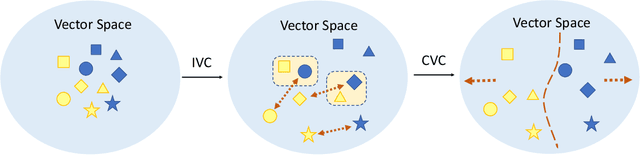
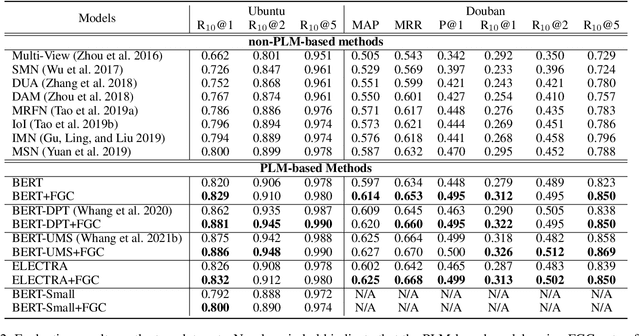
Retrieve-based dialogue response selection aims to find a proper response from a candidate set given a multi-turn context. Pre-trained language models (PLMs) based methods have yielded significant improvements on this task. The sequence representation plays a key role in the learning of matching degree between the dialogue context and the response. However, we observe that different context-response pairs sharing the same context always have a greater similarity in the sequence representations calculated by PLMs, which makes it hard to distinguish positive responses from negative ones. Motivated by this, we propose a novel \textbf{F}ine-\textbf{G}rained \textbf{C}ontrastive (FGC) learning method for the response selection task based on PLMs. This FGC learning strategy helps PLMs to generate more distinguishable matching representations of each dialogue at fine grains, and further make better predictions on choosing positive responses. Empirical studies on two benchmark datasets demonstrate that the proposed FGC learning method can generally and significantly improve the model performance of existing PLM-based matching models.
Multimodal Dialogue Response Generation
Oct 16, 2021
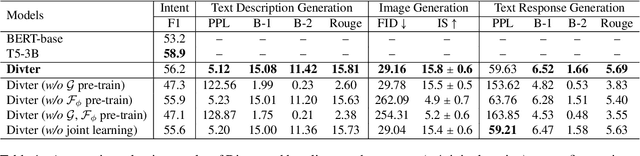
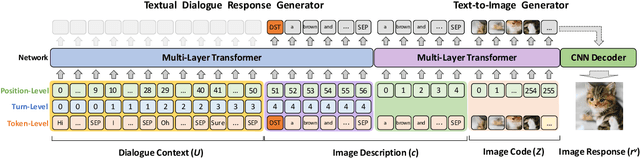
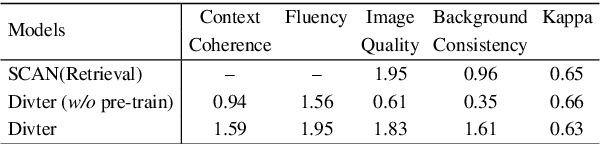
Responsing with image has been recognized as an important capability for an intelligent conversational agent. Yet existing works only focus on exploring the multimodal dialogue models which depend on retrieval-based methods, but neglecting generation methods. To fill in the gaps, we first present a multimodal dialogue generation model, which takes the dialogue history as input, then generates a textual sequence or an image as response. Learning such a model often requires multimodal dialogues containing both texts and images which are difficult to obtain. Motivated by the challenge in practice, we consider multimodal dialogue generation under a natural assumption that only limited training examples are available. In such a low-resource setting, we devise a novel conversational agent, Divter, in order to isolate parameters that depend on multimodal dialogues from the entire generation model. By this means, the major part of the model can be learned from a large number of text-only dialogues and text-image pairs respectively, then the whole parameters can be well fitted using the limited training examples. Extensive experiments demonstrate our method achieves state-of-the-art results in both automatic and human evaluation, and can generate informative text and high-resolution image responses.
Finetuning Large-Scale Pre-trained Language Models for Conversational Recommendation with Knowledge Graph
Oct 14, 2021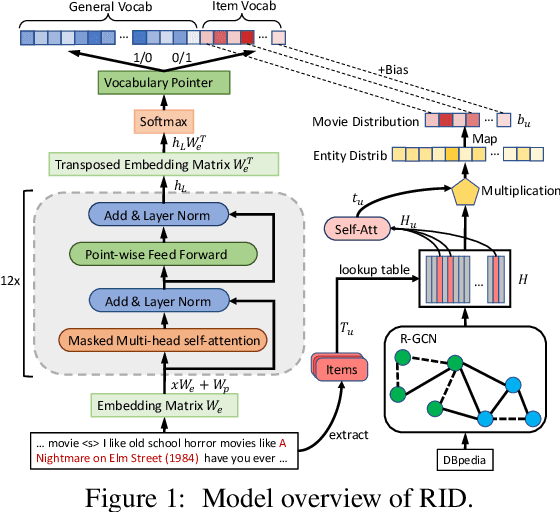

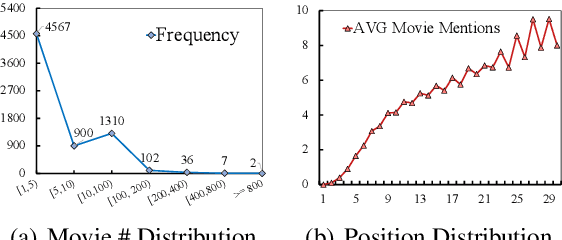

In this paper, we present a pre-trained language model (PLM) based framework called RID for conversational recommender system (CRS). RID finetunes the large-scale PLMs such as DialoGPT, together with a pre-trained Relational Graph Convolutional Network (RGCN) to encode the node representations of an item-oriented knowledge graph. The former aims to generate fluent and diverse dialogue responses based on the strong language generation ability of PLMs, while the latter is to facilitate the item recommendation by learning better node embeddings on the structural knowledge base. To unify two modules of dialogue generation and item recommendation into a PLMs-based framework, we expand the generation vocabulary of PLMs to include an extra item vocabulary, and introduces a vocabulary pointer to control when to recommend target items in the generation process. Extensive experiments on the benchmark dataset ReDial show RID significantly outperforms the state-of-the-art methods on both evaluations of dialogue and recommendation.
Learning Neural Templates for Recommender Dialogue System
Sep 25, 2021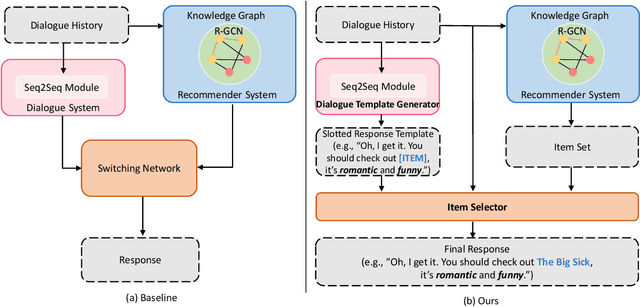

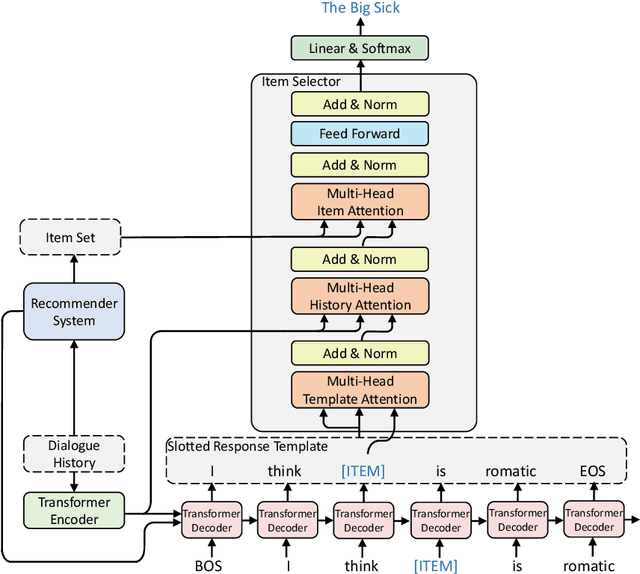

Though recent end-to-end neural models have shown promising progress on Conversational Recommender System (CRS), two key challenges still remain. First, the recommended items cannot be always incorporated into the generated replies precisely and appropriately. Second, only the items mentioned in the training corpus have a chance to be recommended in the conversation. To tackle these challenges, we introduce a novel framework called NTRD for recommender dialogue system that decouples the dialogue generation from the item recommendation. NTRD has two key components, i.e., response template generator and item selector. The former adopts an encoder-decoder model to generate a response template with slot locations tied to target items, while the latter fills in slot locations with the proper items using a sufficient attention mechanism. Our approach combines the strengths of both classical slot filling approaches (that are generally controllable) and modern neural NLG approaches (that are generally more natural and accurate). Extensive experiments on the benchmark ReDial show our NTRD significantly outperforms the previous state-of-the-art methods. Besides, our approach has the unique advantage to produce novel items that do not appear in the training set of dialogue corpus. The code is available at \url{https://github.com/jokieleung/NTRD}.
Contextual Fine-to-Coarse Distillation for Coarse-grained Response Selection in Open-Domain Conversations
Sep 24, 2021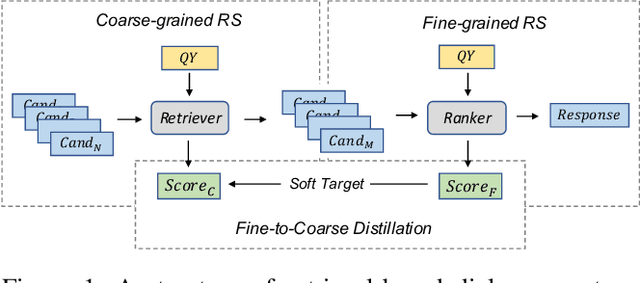

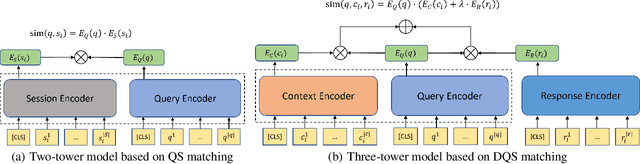

We study the problem of coarse-grained response selection in retrieval-based dialogue systems. The problem is equally important with fine-grained response selection, but is less explored in existing literature. In this paper, we propose a Contextual Fine-to-Coarse (CFC) distilled model for coarse-grained response selection in open-domain conversations. In our CFC model, dense representations of query, candidate response and corresponding context is learned based on the multi-tower architecture, and more expressive knowledge learned from the one-tower architecture (fine-grained) is distilled into the multi-tower architecture (coarse-grained) to enhance the performance of the retriever. To evaluate the performance of our proposed model, we construct two new datasets based on the Reddit comments dump and Twitter corpus. Extensive experimental results on the two datasets show that the proposed methods achieve a significant improvement over all evaluation metrics compared with traditional baseline methods.