 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMAGINE: Integrating Multi-Agent System into One Model for Complex Reasoning and Planning
Oct 16, 2025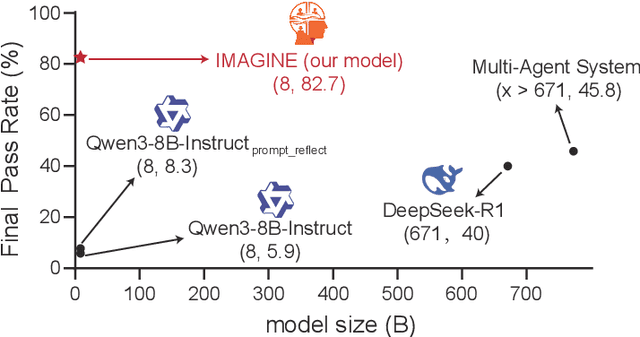
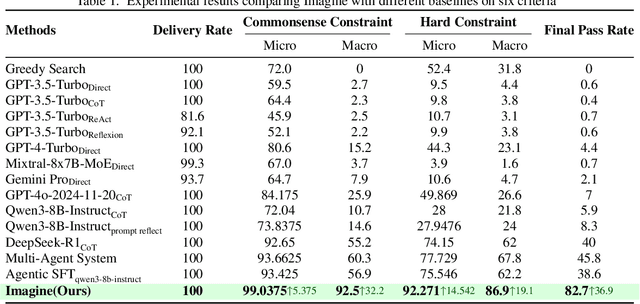
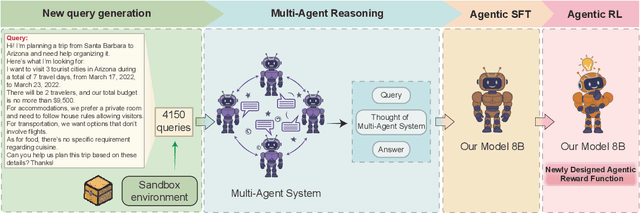

Although large language models (LLMs) have made significant strides across various tasks, they still face significant challenges in complex reasoning and planning. For example, even with carefully designed prompts and prior information explicitly provided, GPT-4o achieves only a 7% Final Pass Rate on the TravelPlanner dataset in the sole-planning mode. Similarly, even in the thinking mode, Qwen3-8B-Instruct and DeepSeek-R1-671B, only achieve Final Pass Rates of 5.9% and 40%, respectively. Although well-organized Multi-Agent Systems (MAS) can offer improved collective reasoning, they often suffer from high reasoning costs due to multi-round internal interactions, long per-response latency, and difficulties in end-to-end training. To address these challenges, we propose a general and scalable framework called IMAGINE, short for Integrating Multi-Agent System into One Model. This framework not only integrates the reasoning and planning capabilities of MAS into a single, compact model, but also significantly surpass the capabilities of the MAS through a simple end-to-end training. Through this pipeline, a single small-scale model is not only able to acquire the structured reasoning and planning capabilities of a well-organized MAS but can also significantly outperform it. Experimental results demonstrate that, when using Qwen3-8B-Instruct as the base model and training it with our method, the model achieves an 82.7% Final Pass Rate on the TravelPlanner benchmark, far exceeding the 40% of DeepSeek-R1-671B, while maintaining a much smaller model size.
Learning Instance-Level Representation for Large-Scale Multi-Modal Pretraining in E-commerce
Apr 06, 2023


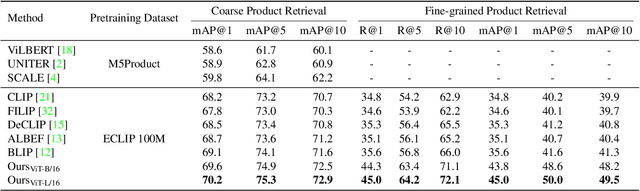
This paper aims to establish a generic multi-modal foundation model that has the scalable capability to massive downstream applications in E-commerce. Recently, large-scale vision-language pretraining approaches have achieved remarkable advances in the general domain. However, due to the significant differences between natural and product images, directly applying these frameworks for modeling image-level representations to E-commerce will be inevitably sub-optimal. To this end, we propose an instance-centric multi-modal pretraining paradigm called ECLIP in this work. In detail, we craft a decoder architecture that introduces a set of learnable instance queries to explicitly aggregate instance-level semantics. Moreover, to enable the model to focus on the desired product instance without reliance on expensive manual annotations, two specially configured pretext tasks are further proposed. Pretrained on the 100 million E-commerce-related data, ECLIP successfully extracts more generic, semantic-rich, and robust representations. Extensive experimental results show that, without further fine-tuning, ECLIP surpasses existing methods by a large margin on a broad range of downstream tasks, demonstrating the strong transferability to real-world E-commerce applications.
Embracing Consistency: A One-Stage Approach for Spatio-Temporal Video Grounding
Sep 27, 2022



Spatio-Temporal video grounding (STVG) focuses on retrieving the spatio-temporal tube of a specific object depicted by a free-form textual expression. Existing approaches mainly treat this complicated task as a parallel frame-grounding problem and thus suffer from two types of inconsistency drawbacks: feature alignment inconsistency and prediction inconsistency. In this paper, we present an end-to-end one-stage framework, termed Spatio-Temporal Consistency-Aware Transformer (STCAT), to alleviate these issues. Specially, we introduce a novel multi-modal template as the global objective to address this task, which explicitly constricts the grounding region and associates the predictions among all video frames. Moreover, to generate the above template under sufficient video-textual perception, an encoder-decoder architecture is proposed for effective global context modeling. Thanks to these critical designs, STCAT enjoys more consistent cross-modal feature alignment and tube prediction without reliance on any pre-trained object detectors. Extensive experiments show that our method outperforms previous state-of-the-arts with clear margins on two challenging video benchmarks (VidSTG and HC-STVG), illustrating the superiority of the proposed framework to better understanding the association between vision and natural language. Code is publicly available at \url{https://github.com/jy0205/STCAT}.
FORCE: A Framework of Rule-Based Conversational Recommender System
Mar 18, 2022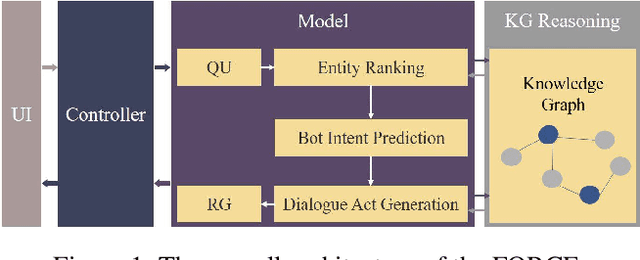
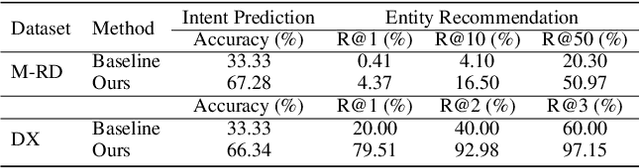
The conversational recommender systems (CRSs) have received extensive attention in recent years. However, most of the existing works focus on various deep learning models, which are largely limited by the requirement of large-scale human-annotated datasets. Such methods are not able to deal with the cold-start scenarios in industrial products. To alleviate the problem, we propose FORCE, a Framework Of Rule-based Conversational Recommender system that helps developers to quickly build CRS bots by simple configuration. We conduct experiments on two datasets in different languages and domains to verify its effectiveness and usability.
Integrating Pre-trained Model into Rule-based Dialogue Management
Feb 17, 2021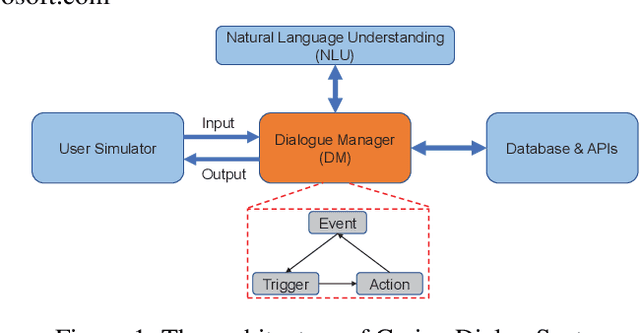
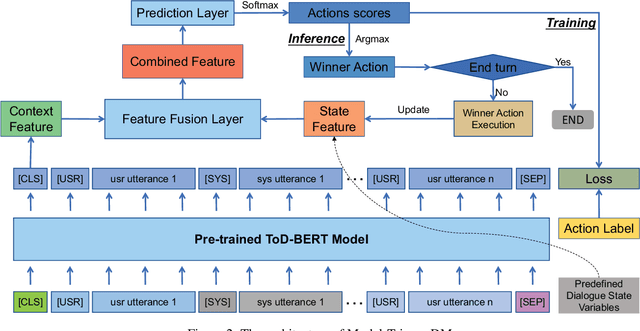
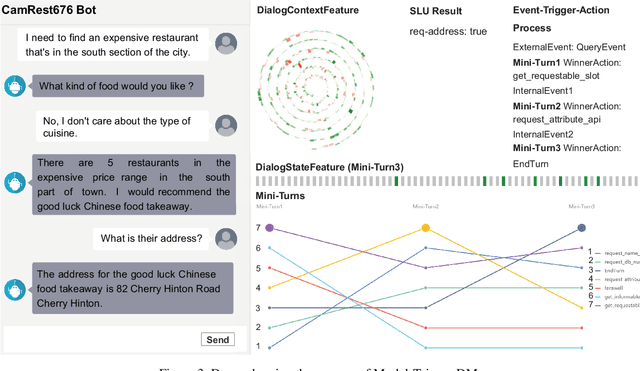
Rule-based dialogue management is still the most popular solution for industrial task-oriented dialogue systems for their interpretablility. However, it is hard for developers to maintain the dialogue logic when the scenarios get more and more complex. On the other hand, data-driven dialogue systems, usually with end-to-end structures, are popular in academic research and easier to deal with complex conversations, but such methods require plenty of training data and the behaviors are less interpretable. In this paper, we propose a method to leverages the strength of both rule-based and data-driven dialogue managers (DM). We firstly introduce the DM of Carina Dialog System (CDS, an advanced industrial dialogue system built by Microsoft). Then we propose the "model-trigger" design to make the DM trainable thus scalable to scenario changes. Furthermore, we integrate pre-trained models and empower the DM with few-shot capability. The experimental results demonstrate the effectiveness and strong few-shot capability of our method.