 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFORCE: A Framework of Rule-Based Conversational Recommender System
Mar 18, 2022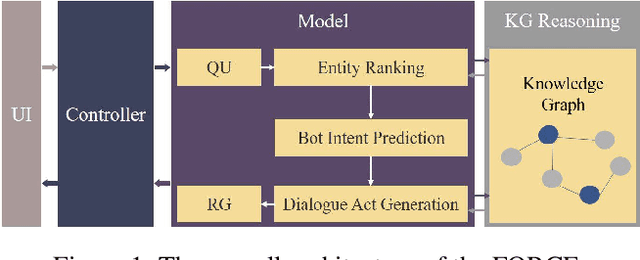
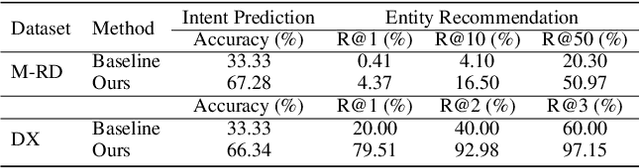
The conversational recommender systems (CRSs) have received extensive attention in recent years. However, most of the existing works focus on various deep learning models, which are largely limited by the requirement of large-scale human-annotated datasets. Such methods are not able to deal with the cold-start scenarios in industrial products. To alleviate the problem, we propose FORCE, a Framework Of Rule-based Conversational Recommender system that helps developers to quickly build CRS bots by simple configuration. We conduct experiments on two datasets in different languages and domains to verify its effectiveness and usability.
Integrating Pre-trained Model into Rule-based Dialogue Management
Feb 17, 2021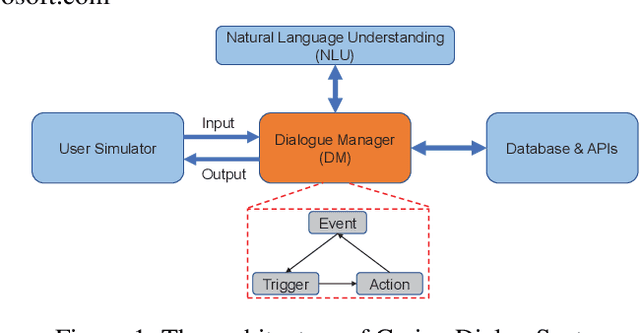
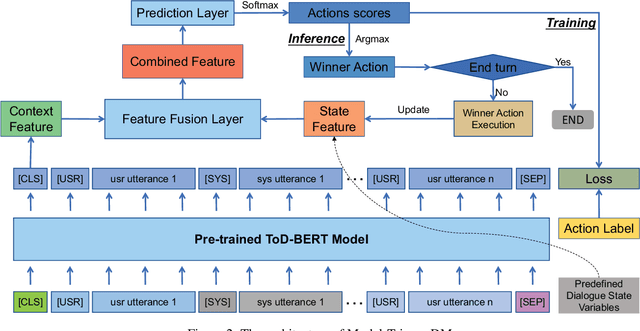
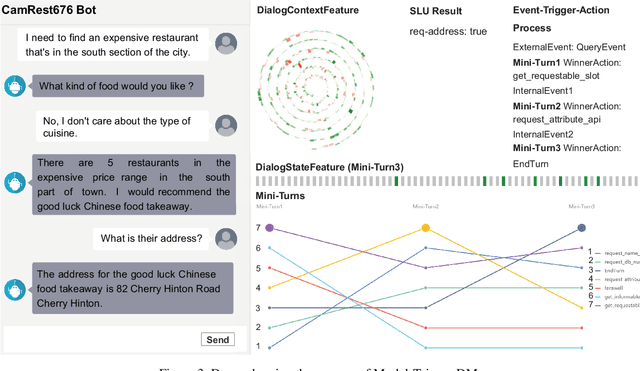
Rule-based dialogue management is still the most popular solution for industrial task-oriented dialogue systems for their interpretablility. However, it is hard for developers to maintain the dialogue logic when the scenarios get more and more complex. On the other hand, data-driven dialogue systems, usually with end-to-end structures, are popular in academic research and easier to deal with complex conversations, but such methods require plenty of training data and the behaviors are less interpretable. In this paper, we propose a method to leverages the strength of both rule-based and data-driven dialogue managers (DM). We firstly introduce the DM of Carina Dialog System (CDS, an advanced industrial dialogue system built by Microsoft). Then we propose the "model-trigger" design to make the DM trainable thus scalable to scenario changes. Furthermore, we integrate pre-trained models and empower the DM with few-shot capability. The experimental results demonstrate the effectiveness and strong few-shot capability of our method.
RiSAWOZ: A Large-Scale Multi-Domain Wizard-of-Oz Dataset with Rich Semantic Annotations for Task-Oriented Dialogue Modeling
Oct 17, 2020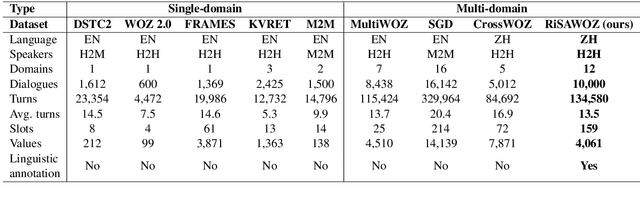
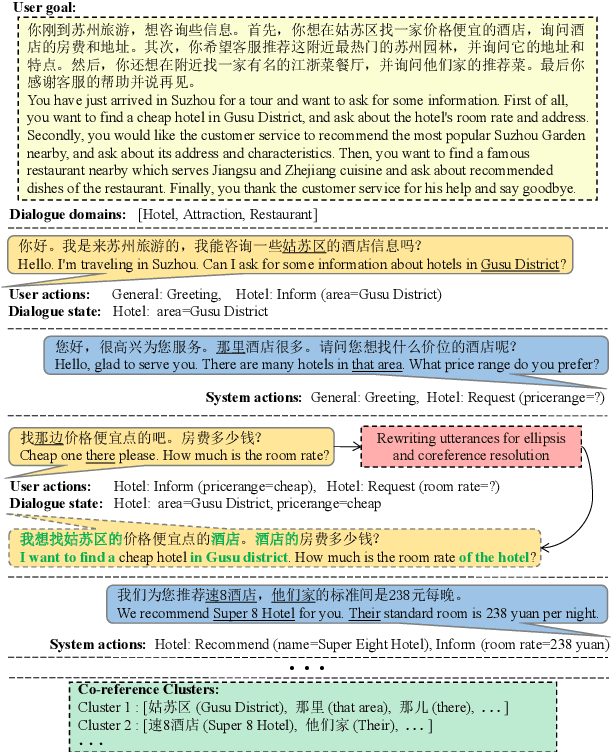
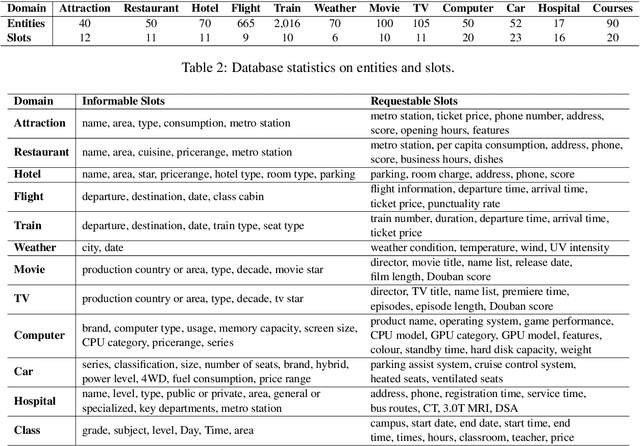

In order to alleviate the shortage of multi-domain data and to capture discourse phenomena for task-oriented dialogue modeling, we propose RiSAWOZ, a large-scale multi-domain Chinese Wizard-of-Oz dataset with Rich Semantic Annotations. RiSAWOZ contains 11.2K human-to-human (H2H) multi-turn semantically annotated dialogues, with more than 150K utterances spanning over 12 domains, which is larger than all previous annotated H2H conversational datasets. Both single- and multi-domain dialogues are constructed, accounting for 65% and 35%, respectively. Each dialogue is labeled with comprehensive dialogue annotations, including dialogue goal in the form of natural language description, domain, dialogue states and acts at both the user and system side. In addition to traditional dialogue annotations, we especially provide linguistic annotations on discourse phenomena, e.g., ellipsis and coreference, in dialogues, which are useful for dialogue coreference and ellipsis resolution tasks. Apart from the fully annotated dataset, we also present a detailed description of the data collection procedure, statistics and analysis of the dataset. A series of benchmark models and results are reported, including natural language understanding (intent detection & slot filling), dialogue state tracking and dialogue context-to-text generation, as well as coreference and ellipsis resolution, which facilitate the baseline comparison for future research on this corpus.
Modeling Long Context for Task-Oriented Dialogue State Generation
Apr 29, 2020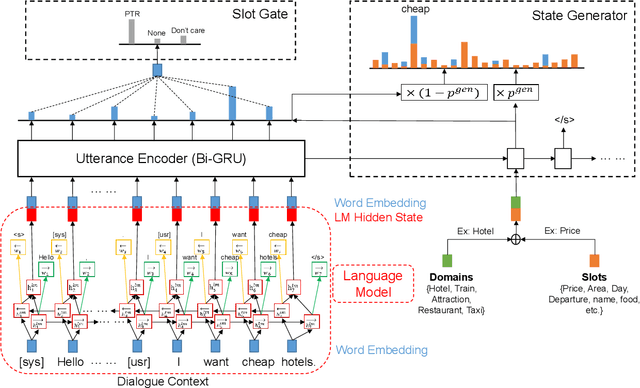
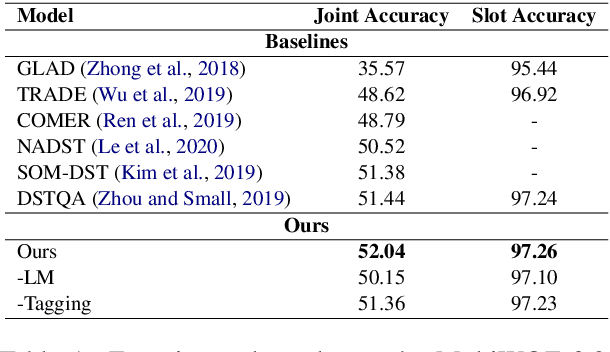
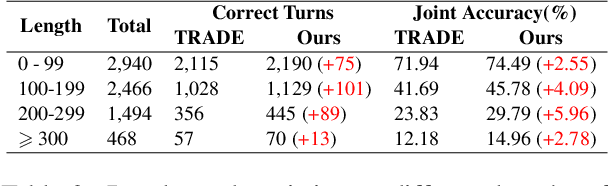
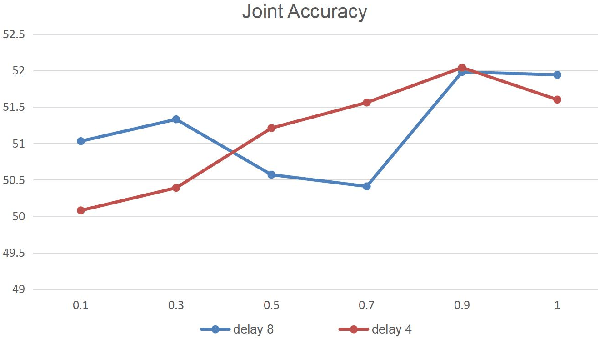
Based on the recently proposed transferable dialogue state generator (TRADE) that predicts dialogue states from utterance-concatenated dialogue context, we propose a multi-task learning model with a simple yet effective utterance tagging technique and a bidirectional language model as an auxiliary task for task-oriented dialogue state generation. By enabling the model to learn a better representation of the long dialogue context, our approaches attempt to solve the problem that the performance of the baseline significantly drops when the input dialogue context sequence is long. In our experiments, our proposed model achieves a 7.03% relative improvement over the baseline, establishing a new state-of-the-art joint goal accuracy of 52.04% on the MultiWOZ 2.0 dataset.
Effective Data Augmentation Approaches to End-to-End Task-Oriented Dialogue
Dec 05, 2019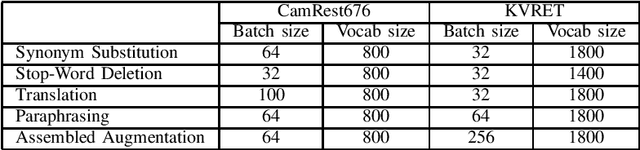


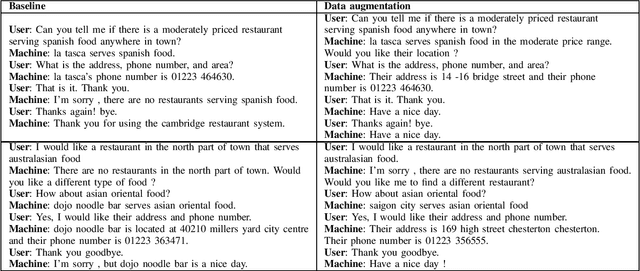
The training of task-oriented dialogue systems is often confronted with the lack of annotated data. In contrast to previous work which augments training data through expensive crowd-sourcing efforts, we propose four different automatic approaches to data augmentation at both the word and sentence level for end-to-end task-oriented dialogue and conduct an empirical study on their impact. Experimental results on the CamRest676 and KVRET datasets demonstrate that each of the four data augmentation approaches is able to obtain a significant improvement over a strong baseline in terms of Success F1 score and that the ensemble of the four approaches achieves the state-of-the-art results in the two datasets. In-depth analyses further confirm that our methods adequately increase the diversity of user utterances, which enables the end-to-end model to learn features robustly.
GECOR: An End-to-End Generative Ellipsis and Co-reference Resolution Model for Task-Oriented Dialogue
Sep 26, 2019
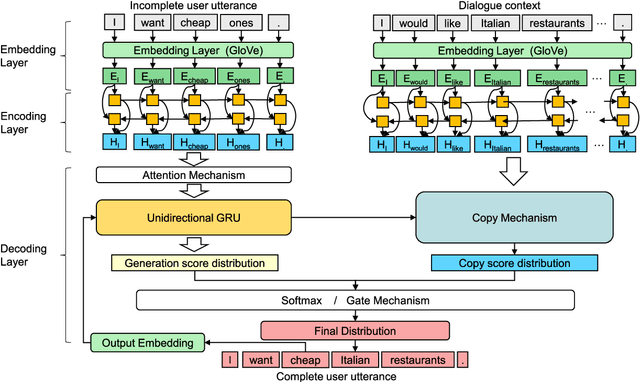
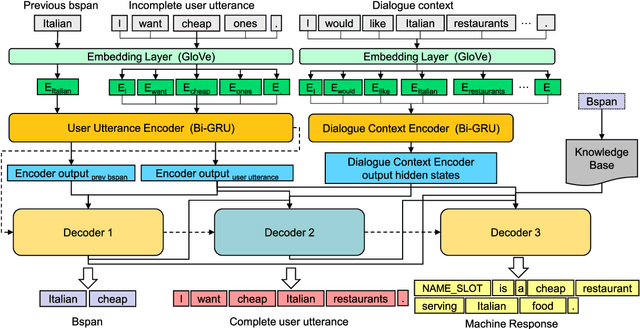

Ellipsis and co-reference are common and ubiquitous especially in multi-turn dialogues. In this paper, we treat the resolution of ellipsis and co-reference in dialogue as a problem of generating omitted or referred expressions from the dialogue context. We therefore propose a unified end-to-end Generative Ellipsis and CO-reference Resolution model (GECOR) in the context of dialogue. The model can generate a new pragmatically complete user utterance by alternating the generation and copy mode for each user utterance. A multi-task learning framework is further proposed to integrate the GECOR into an end-to-end task-oriented dialogue. In order to train both the GECOR and the multi-task learning framework, we manually construct a new dataset on the basis of the public dataset CamRest676 with both ellipsis and co-reference annotation. On this dataset, intrinsic evaluations on the resolution of ellipsis and co-reference show that the GECOR model significantly outperforms the sequence-to-sequence (seq2seq) baseline model in terms of EM, BLEU and F1 while extrinsic evaluations on the downstream dialogue task demonstrate that our multi-task learning framework with GECOR achieves a higher success rate of task completion than TSCP, a state-of-the-art end-to-end task-oriented dialogue model.