 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA flexible and accurate total variation and cascaded denoisers-based image reconstruction algorithm for hyperspectrally compressed ultrafast photography
Sep 06, 2023Hyperspectrally compressed ultrafast photography (HCUP) based on compressed sensing and the time- and spectrum-to-space mappings can simultaneously realize the temporal and spectral imaging of non-repeatable or difficult-to-repeat transient events passively in a single exposure. It possesses an incredibly high frame rate of tens of trillions of frames per second and a sequence depth of several hundred, and plays a revolutionary role in single-shot ultrafast optical imaging. However, due to the ultra-high data compression ratio induced by the extremely large sequence depth as well as the limited fidelities of traditional reconstruction algorithms over the reconstruction process, HCUP suffers from a poor image reconstruction quality and fails to capture fine structures in complex transient scenes. To overcome these restrictions, we propose a flexible image reconstruction algorithm based on the total variation (TV) and cascaded denoisers (CD) for HCUP, named the TV-CD algorithm. It applies the TV denoising model cascaded with several advanced deep learning-based denoising models in the iterative plug-and-play alternating direction method of multipliers framework, which can preserve the image smoothness while utilizing the deep denoising networks to obtain more priori, and thus solving the common sparsity representation problem in local similarity and motion compensation. Both simulation and experimental results show that the proposed TV-CD algorithm can effectively improve the image reconstruction accuracy and quality of HCUP, and further promote the practical applications of HCUP in capturing high-dimensional complex physical, chemical and biological ultrafast optical scenes.
RiSAWOZ: A Large-Scale Multi-Domain Wizard-of-Oz Dataset with Rich Semantic Annotations for Task-Oriented Dialogue Modeling
Oct 17, 2020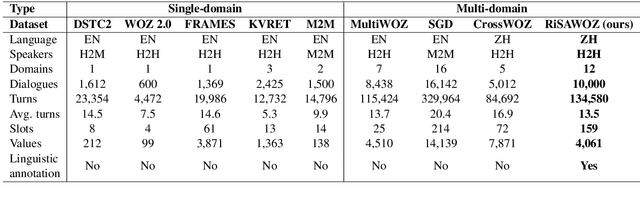
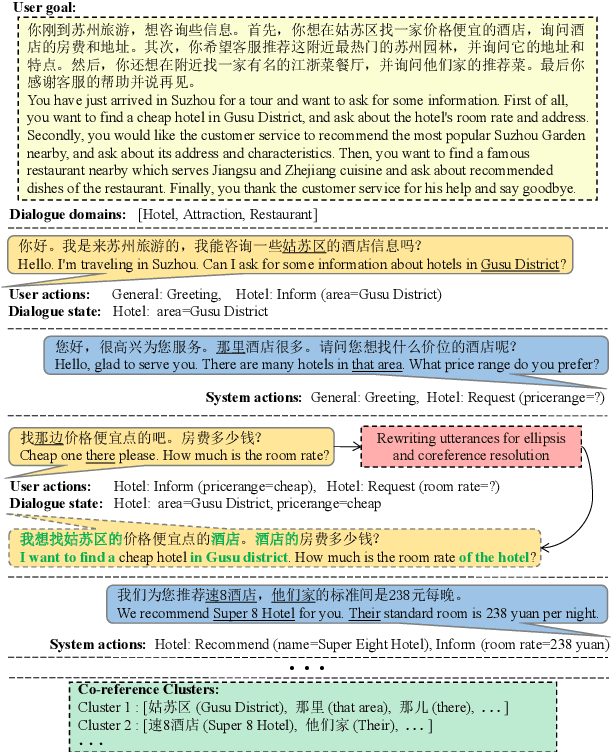
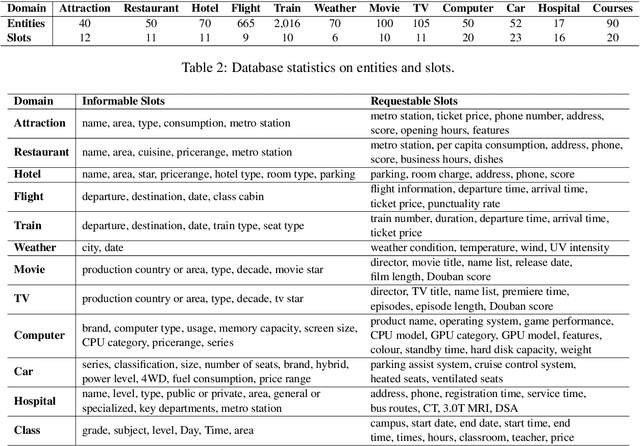

In order to alleviate the shortage of multi-domain data and to capture discourse phenomena for task-oriented dialogue modeling, we propose RiSAWOZ, a large-scale multi-domain Chinese Wizard-of-Oz dataset with Rich Semantic Annotations. RiSAWOZ contains 11.2K human-to-human (H2H) multi-turn semantically annotated dialogues, with more than 150K utterances spanning over 12 domains, which is larger than all previous annotated H2H conversational datasets. Both single- and multi-domain dialogues are constructed, accounting for 65% and 35%, respectively. Each dialogue is labeled with comprehensive dialogue annotations, including dialogue goal in the form of natural language description, domain, dialogue states and acts at both the user and system side. In addition to traditional dialogue annotations, we especially provide linguistic annotations on discourse phenomena, e.g., ellipsis and coreference, in dialogues, which are useful for dialogue coreference and ellipsis resolution tasks. Apart from the fully annotated dataset, we also present a detailed description of the data collection procedure, statistics and analysis of the dataset. A series of benchmark models and results are reported, including natural language understanding (intent detection & slot filling), dialogue state tracking and dialogue context-to-text generation, as well as coreference and ellipsis resolution, which facilitate the baseline comparison for future research on this corpus.