 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMSP: A Plug-and-Play Strategy of Multi-Scale Perception for MLLMs to Perceive Visual Illusions
Mar 24, 2026Recent works have shown that Multimodal Large Language Models (MLLMs) are highly vulnerable to hidden-pattern visual illusions, where the hidden content is imperceptible to models but obvious to humans. This deficiency highlights a perceptual misalignment between current MLLMs and humans, and also introduces potential safety concerns. To systematically investigate this failure, we introduce IlluChar, a comprehensive and challenging illusion dataset, and uncover a key underlying mechanism for the models' failure: high-frequency attention bias, where the models are easily distracted by high-frequency background textures in illusion images, causing them to overlook hidden patterns. To address the issue, we propose the Strategy of Multi-Scale Perception (SMSP), a plug-and-play framework that aligns with human visual perceptual strategies. By suppressing distracting high-frequency backgrounds, SMSP generates images closer to human perception. Our experiments demonstrate that SMSP significantly improves the performance of all evaluated MLLMs on illusion images, for instance, increasing the accuracy of Qwen3-VL-8B-Instruct from 13.0% to 84.0%. Our work provides novel insights into MLLMs' visual perception, and offers a practical and robust solution to enhance it. Our code is publicly available at https://github.com/Tujz2023/SMSP.
Creating manufacturable blueprints for coarse-grained virtual robots
Mar 13, 2026Over the past three decades, countless embodied yet virtual agents have freely evolved inside computer simulations, but vanishingly few were realized as physical robots. This is because evolution was conducted at a level of abstraction that was convenient for freeform body generation (creation, mutation, recombination) but swept away almost all of the physical details of functional body parts. The resulting designs were crude and underdetermined, requiring considerable effort and expertise to convert into a manufacturable format. Here, we automate this mapping from simplified design spaces that are readily evolvable to complete blueprints that can be directly followed by a builder. The pipeline incrementally resolves manufacturing constraints by embedding the structural and functional semantics of motors, electronics, batteries, and wiring into the abstract virtual design. In lieu of evolution, a user-defined or AI-generated ``sketch'' of a body plan can also be fed as input to the pipeline, providing a versatile framework for accelerating the design of novel robots.
Thinking with Geometry: Active Geometry Integration for Spatial Reasoning
Feb 05, 2026Recent progress in spatial reasoning with Multimodal Large Language Models (MLLMs) increasingly leverages geometric priors from 3D encoders. However, most existing integration strategies remain passive: geometry is exposed as a global stream and fused in an indiscriminate manner, which often induces semantic-geometry misalignment and redundant signals. We propose GeoThinker, a framework that shifts the paradigm from passive fusion to active perception. Instead of feature mixing, GeoThinker enables the model to selectively retrieve geometric evidence conditioned on its internal reasoning demands. GeoThinker achieves this through Spatial-Grounded Fusion applied at carefully selected VLM layers, where semantic visual priors selectively query and integrate task-relevant geometry via frame-strict cross-attention, further calibrated by Importance Gating that biases per-frame attention toward task-relevant structures. Comprehensive evaluation results show that GeoThinker sets a new state-of-the-art in spatial intelligence, achieving a peak score of 72.6 on the VSI-Bench. Furthermore, GeoThinker demonstrates robust generalization and significantly improved spatial perception across complex downstream scenarios, including embodied referring and autonomous driving. Our results indicate that the ability to actively integrate spatial structures is essential for next-generation spatial intelligence. Code can be found at https://github.com/Li-Hao-yuan/GeoThinker.
Cracking IoT Security: Can LLMs Outsmart Static Analysis Tools?
Jan 02, 2026Smart home IoT platforms such as openHAB rely on Trigger Action Condition (TAC) rules to automate device behavior, but the interplay among these rules can give rise to interaction threats, unintended or unsafe behaviors emerging from implicit dependencies, conflicting triggers, or overlapping conditions. Identifying these threats requires semantic understanding and structural reasoning that traditionally depend on symbolic, constraint-driven static analysis. This work presents the first comprehensive evaluation of Large Language Models (LLMs) across a multi-category interaction threat taxonomy, assessing their performance on both the original openHAB (oHC/IoTB) dataset and a structurally challenging Mutation dataset designed to test robustness under rule transformations. We benchmark Llama 3.1 8B, Llama 70B, GPT-4o, Gemini-2.5-Pro, and DeepSeek-R1 across zero-, one-, and two-shot settings, comparing their results against oHIT's manually validated ground truth. Our findings show that while LLMs exhibit promising semantic understanding, particularly on action- and condition-related threats, their accuracy degrades significantly for threats requiring cross-rule structural reasoning, especially under mutated rule forms. Model performance varies widely across threat categories and prompt settings, with no model providing consistent reliability. In contrast, the symbolic reasoning baseline maintains stable detection across both datasets, unaffected by rule rewrites or structural perturbations. These results underscore that LLMs alone are not yet dependable for safety critical interaction-threat detection in IoT environments. We discuss the implications for tool design and highlight the potential of hybrid architectures that combine symbolic analysis with LLM-based semantic interpretation to reduce false positives while maintaining structural rigor.
Tactile-based Object Retrieval From Granular Media
Feb 21, 2024



We introduce GEOTACT, a robotic manipulation method capable of retrieving objects buried in granular media. This is a challenging task due to the need to interact with granular media, and doing so based exclusively on tactile feedback, since a buried object can be completely hidden from vision. Tactile feedback is in itself challenging in this context, due to ubiquitous contact with the surrounding media, and the inherent noise level induced by the tactile readings. To address these challenges, we use a learning method trained end-to-end with simulated sensor noise. We show that our problem formulation leads to the natural emergence of learned pushing behaviors that the manipulator uses to reduce uncertainty and funnel the object to a stable grasp despite spurious and noisy tactile readings. We also introduce a training curriculum that enables learning these behaviors in simulation, followed by zero-shot transfer to real hardware. To the best of our knowledge, GEOTACT is the first method to reliably retrieve a number of different objects from a granular environment, doing so on real hardware and with integrated tactile sensing. Videos and additional information can be found at https://jxu.ai/geotact.
A flexible and accurate total variation and cascaded denoisers-based image reconstruction algorithm for hyperspectrally compressed ultrafast photography
Sep 06, 2023Hyperspectrally compressed ultrafast photography (HCUP) based on compressed sensing and the time- and spectrum-to-space mappings can simultaneously realize the temporal and spectral imaging of non-repeatable or difficult-to-repeat transient events passively in a single exposure. It possesses an incredibly high frame rate of tens of trillions of frames per second and a sequence depth of several hundred, and plays a revolutionary role in single-shot ultrafast optical imaging. However, due to the ultra-high data compression ratio induced by the extremely large sequence depth as well as the limited fidelities of traditional reconstruction algorithms over the reconstruction process, HCUP suffers from a poor image reconstruction quality and fails to capture fine structures in complex transient scenes. To overcome these restrictions, we propose a flexible image reconstruction algorithm based on the total variation (TV) and cascaded denoisers (CD) for HCUP, named the TV-CD algorithm. It applies the TV denoising model cascaded with several advanced deep learning-based denoising models in the iterative plug-and-play alternating direction method of multipliers framework, which can preserve the image smoothness while utilizing the deep denoising networks to obtain more priori, and thus solving the common sparsity representation problem in local similarity and motion compensation. Both simulation and experimental results show that the proposed TV-CD algorithm can effectively improve the image reconstruction accuracy and quality of HCUP, and further promote the practical applications of HCUP in capturing high-dimensional complex physical, chemical and biological ultrafast optical scenes.
Rapid grasping of fabric using bionic soft grippers with elastic instability
Jan 26, 2023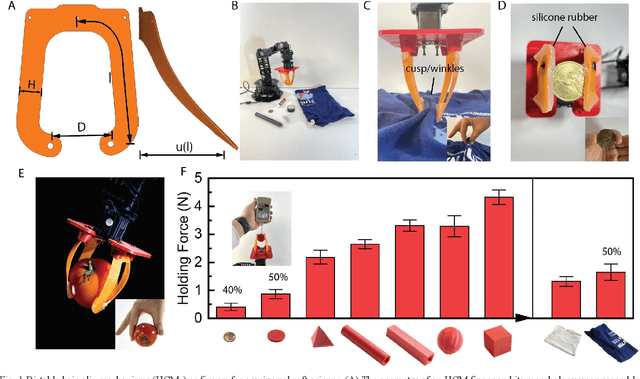
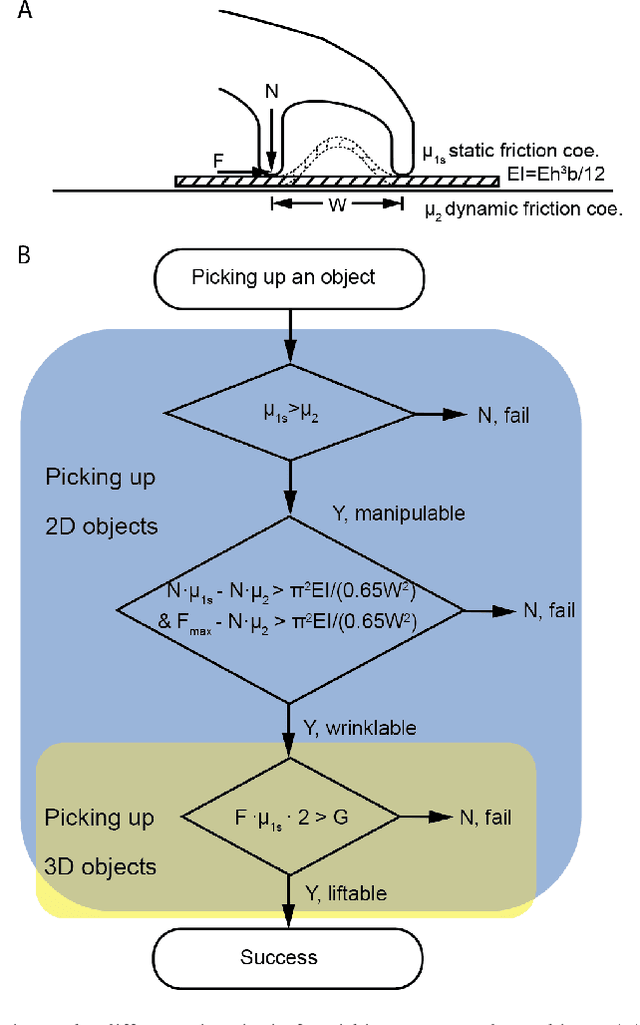
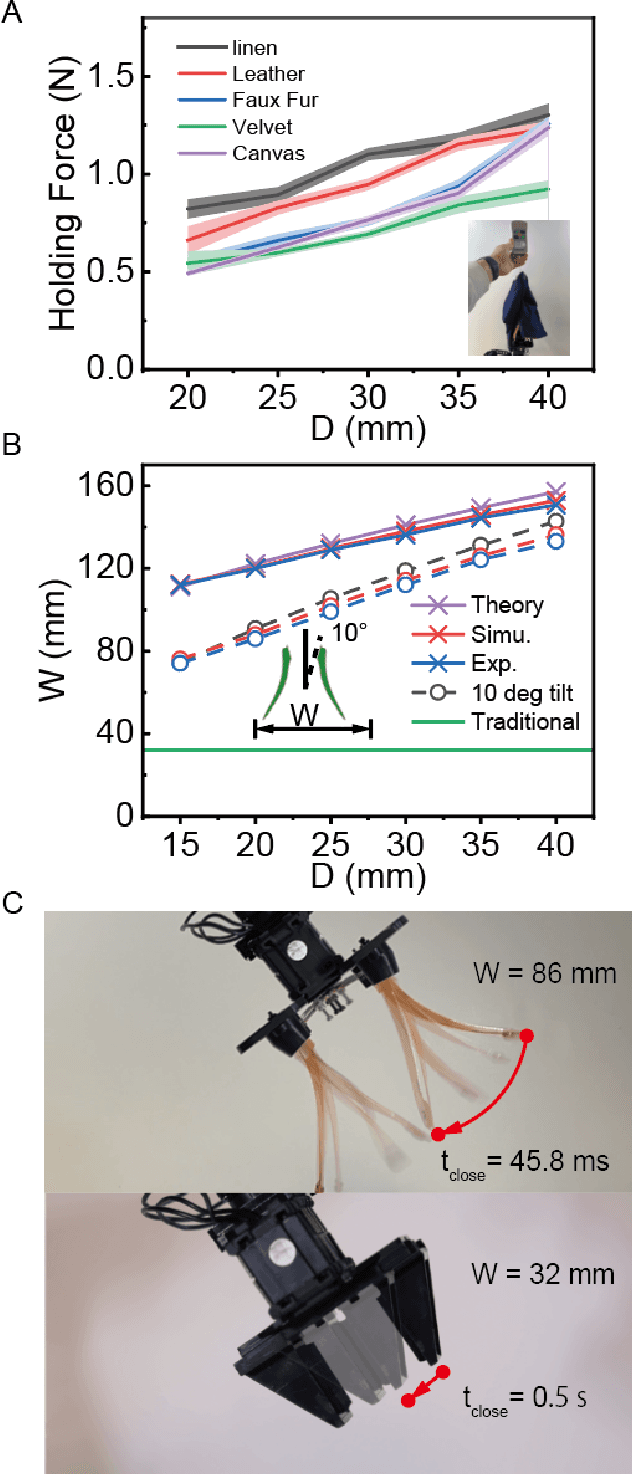
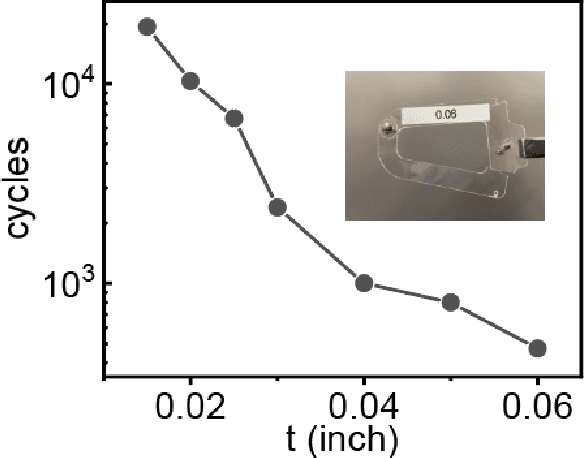
Robot grasping is subject to an inherent tradeoff: Grippers with a large span typically take a longer time to close, and fast grippers usually cover a small span. However, many practical applications of soft grippers require the ability to close a large distance rapidly. For example, grasping cloth typically requires pressing a wide span of fabric into a graspable cusp. Here, we demonstrate a human-finger-inspired snapping gripper that exploits elastic instability to achieve reversible rapid closure over a wide span. Using prestressed semi-rigid material as the skeleton, the gripper fingers can widely open (86 ~) and rapidly close (46 ms) following a trajectory similar to that of a thumb-index finger pinching which is 2.7 times and 10.9 times better than the reference gripper in terms of span and speed, respectively. We theoretically give the design principle, simulatively verify the method, and experimentally test this gripper on a variety of rigid, flexible, and limp objects and achieve good adaptivity and mechanical performance. This research helps bridge the gap between strong industry manipulators and safe human-interactive robotic hands.
Coordination for Connected and Automated Vehicles at Non-signalized Intersections: A Value Decomposition-based Multiagent Deep Reinforcement Learning Approach
Nov 16, 2022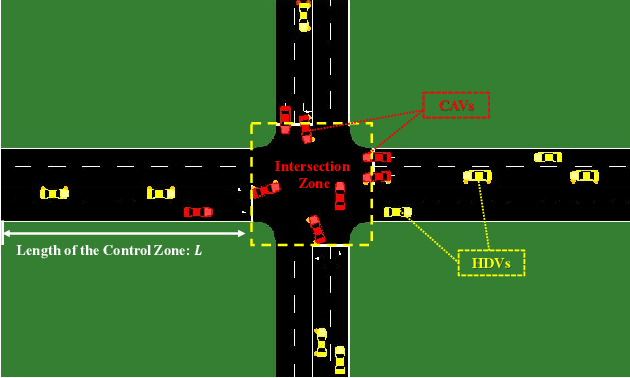
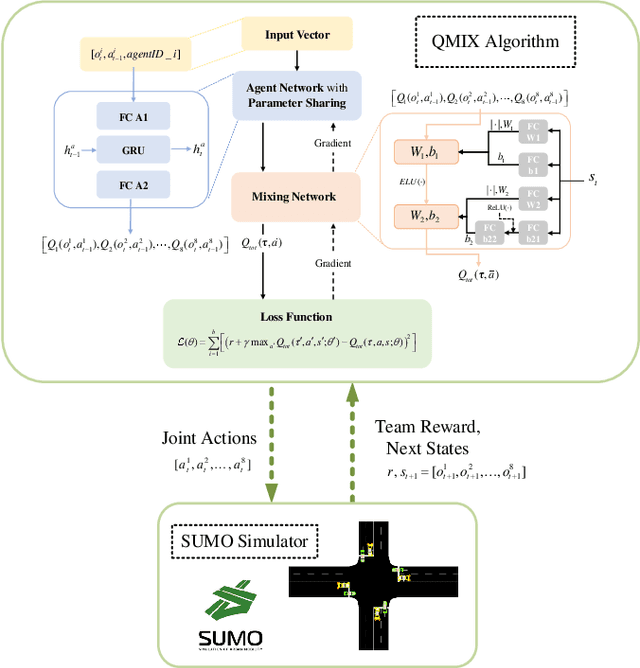
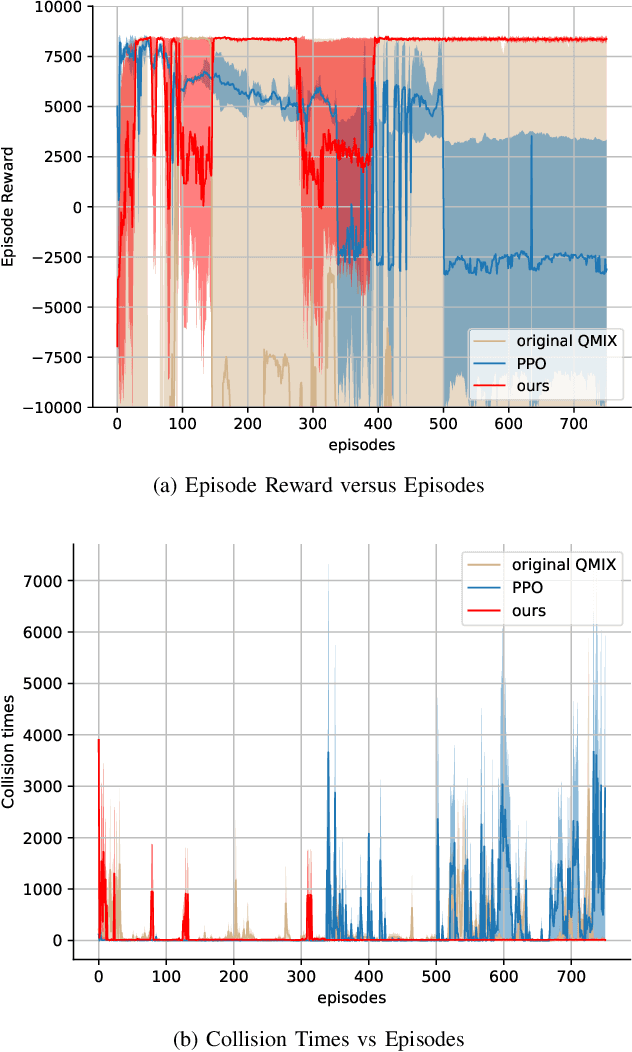
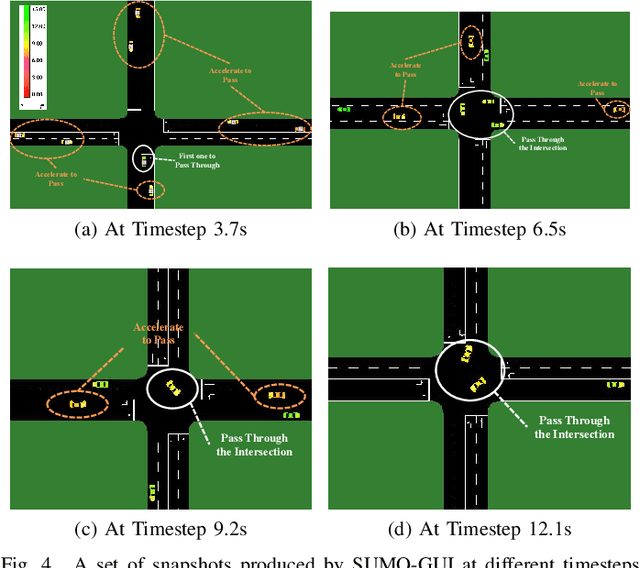
The recent proliferation of the research on multi-agent deep reinforcement learning (MDRL) offers an encouraging way to coordinate multiple connected and automated vehicles (CAVs) to pass the intersection. In this paper, we apply a value decomposition-based MDRL approach (QMIX) to control various CAVs in mixed-autonomy traffic of different densities to efficiently and safely pass the non-signalized intersection with fairish fuel consumption. Implementation tricks including network-level improvements, Q value update by TD ($\lambda$), and reward clipping operation are added to the pure QMIX framework, which is expected to improve the convergence speed and the asymptotic performance of the original version. The efficacy of our approach is demonstrated by several evaluation metrics: average speed, the number of collisions, and average fuel consumption per episode. The experimental results show that our approach's convergence speed and asymptotic performance can exceed that of the original QMIX and the proximal policy optimization (PPO), a state-of-the-art reinforcement learning baseline applied to the non-signalized intersection. Moreover, CAVs under the lower traffic flow controlled by our method can improve their average speed without collisions and consume the least fuel. The training is additionally conducted under the doubled traffic density, where the learning reward converges. Consequently, the model with maximal reward and minimum crashes can still guarantee low fuel consumption, but slightly reduce the efficiency of vehicles and induce more collisions than the lower-traffic counterpart, implying the difficulty of generalizing RL policy to more advanced scenarios.