 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordination for Connected and Automated Vehicles at Non-signalized Intersections: A Value Decomposition-based Multiagent Deep Reinforcement Learning Approach
Paper and Code
Nov 16, 2022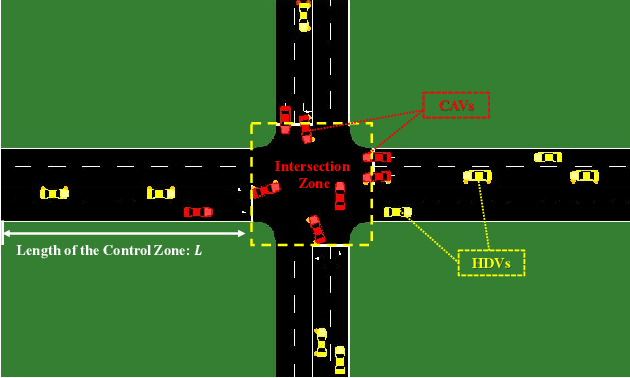
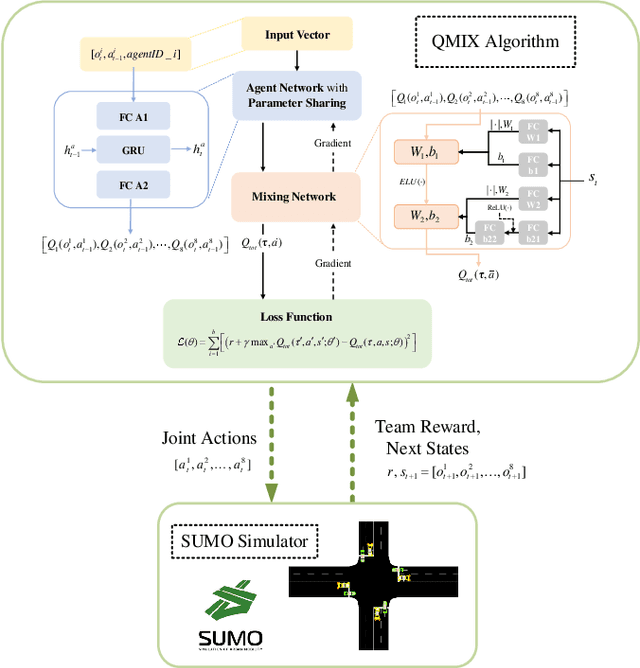
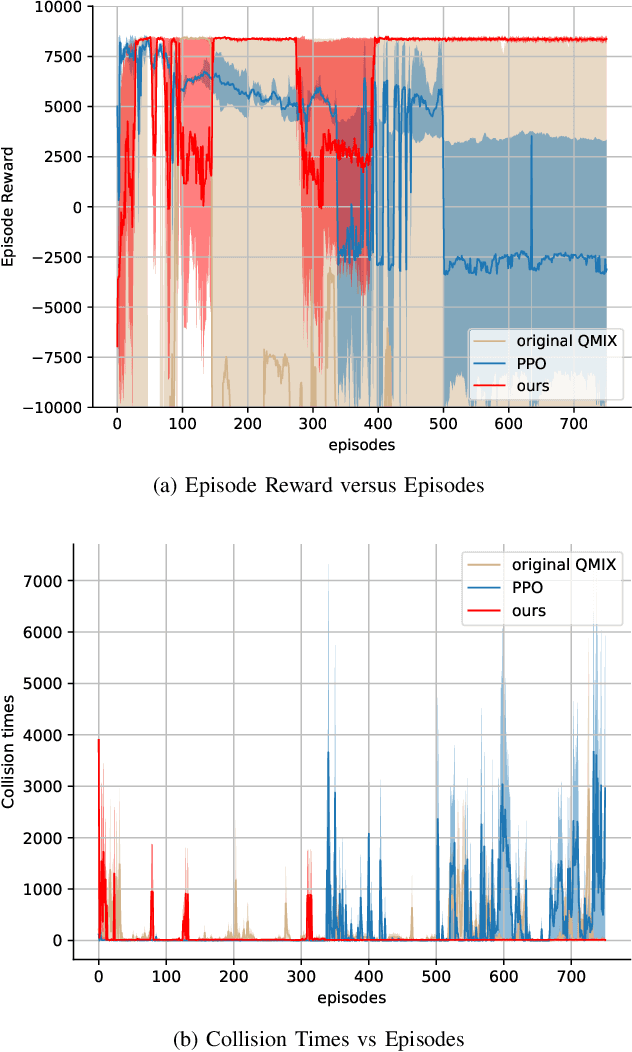
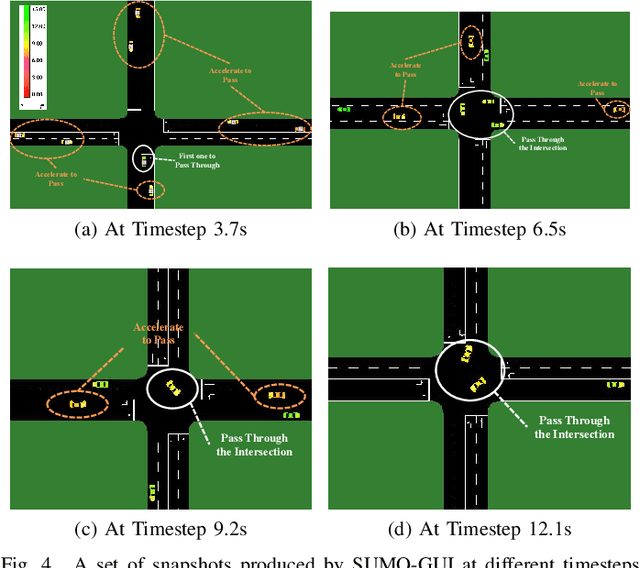
The recent proliferation of the research on multi-agent deep reinforcement learning (MDRL) offers an encouraging way to coordinate multiple connected and automated vehicles (CAVs) to pass the intersection. In this paper, we apply a value decomposition-based MDRL approach (QMIX) to control various CAVs in mixed-autonomy traffic of different densities to efficiently and safely pass the non-signalized intersection with fairish fuel consumption. Implementation tricks including network-level improvements, Q value update by TD ($\lambda$), and reward clipping operation are added to the pure QMIX framework, which is expected to improve the convergence speed and the asymptotic performance of the original version. The efficacy of our approach is demonstrated by several evaluation metrics: average speed, the number of collisions, and average fuel consumption per episode. The experimental results show that our approach's convergence speed and asymptotic performance can exceed that of the original QMIX and the proximal policy optimization (PPO), a state-of-the-art reinforcement learning baseline applied to the non-signalized intersection. Moreover, CAVs under the lower traffic flow controlled by our method can improve their average speed without collisions and consume the least fuel. The training is additionally conducted under the doubled traffic density, where the learning reward converges. Consequently, the model with maximal reward and minimum crashes can still guarantee low fuel consumption, but slightly reduce the efficiency of vehicles and induce more collisions than the lower-traffic counterpart, implying the difficulty of generalizing RL policy to more advanced scenarios.