 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSACA: A Scenario-Aware Collision Avoidance Framework for Autonomous Vehicles Integrating LLMs-Driven Reasoning
Mar 31, 2025Reliable collision avoidance under extreme situations remains a critical challenge for autonomous vehicles. While large language models (LLMs) offer promising reasoning capabilities, their application in safety-critical evasive maneuvers is limited by latency and robustness issues. Even so, LLMs stand out for their ability to weigh emotional, legal, and ethical factors, enabling socially responsible and context-aware collision avoidance. This paper proposes a scenario-aware collision avoidance (SACA) framework for extreme situations by integrating predictive scenario evaluation, data-driven reasoning, and scenario-preview-based deployment to improve collision avoidance decision-making. SACA consists of three key components. First, a predictive scenario analysis module utilizes obstacle reachability analysis and motion intention prediction to construct a comprehensive situational prompt. Second, an online reasoning module refines decision-making by leveraging prior collision avoidance knowledge and fine-tuning with scenario data. Third, an offline evaluation module assesses performance and stores scenarios in a memory bank. Additionally, A precomputed policy method improves deployability by previewing scenarios and retrieving or reasoning policies based on similarity and confidence levels. Real-vehicle tests show that, compared with baseline methods, SACA effectively reduces collision losses in extreme high-risk scenarios and lowers false triggering under complex conditions. Project page: https://sean-shiyuez.github.io/SACA/.
High-Speed Cornering Control and Real-Vehicle Deployment for Autonomous Electric Vehicles
Nov 18, 2024Executing drift maneuvers during high-speed cornering presents significant challenges for autonomous vehicles, yet offers the potential to minimize turning time and enhance driving dynamics. While reinforcement learning (RL) has shown promising results in simulated environments, discrepancies between simulations and real-world conditions have limited its practical deployment. This study introduces an innovative control framework that integrates trajectory optimization with drift maneuvers, aiming to improve the algorithm's adaptability for real-vehicle implementation. We leveraged Bezier-based pre-trajectory optimization to enhance rewards and optimize the controller through Twin Delayed Deep Deterministic Policy Gradient (TD3) in a simulated environment. For real-world deployment, we implement a hybrid RL-MPC fusion mechanism, , where TD3-derived maneuvers serve as primary inputs for a Model Predictive Controller (MPC). This integration enables precise real-time tracking of the optimal trajectory, with MPC providing corrective inputs to bridge the gap between simulation and reality. The efficacy of this method is validated through real-vehicle tests on consumer-grade electric vehicles, focusing on drift U-turns and drift right-angle turns. The control outcomes of these real-vehicle tests are thoroughly documented in the paper, supported by supplementary video evidence (https://youtu.be/5wp67FcpfL8). Notably, this study is the first to deploy and apply an RL-based transient drift cornering algorithm on consumer-grade electric vehicles.
Coordination for Connected and Automated Vehicles at Non-signalized Intersections: A Value Decomposition-based Multiagent Deep Reinforcement Learning Approach
Nov 16, 2022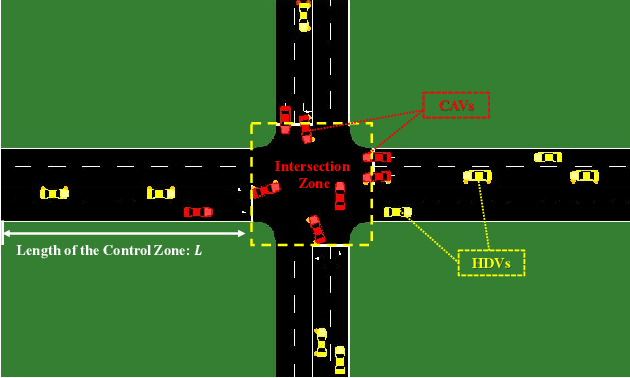
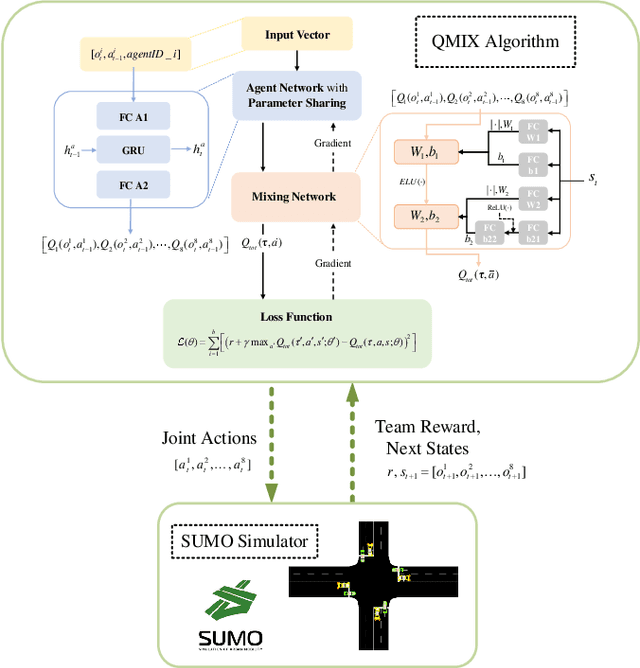
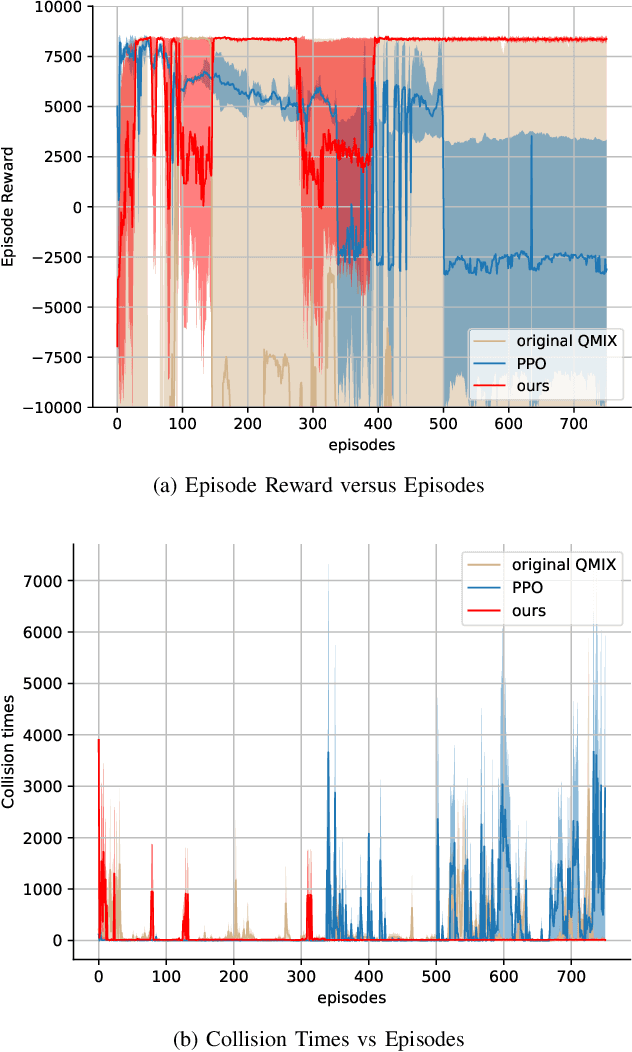
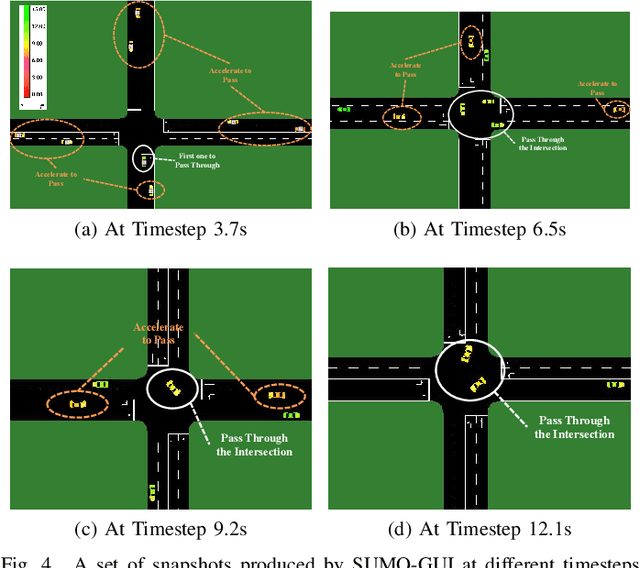
The recent proliferation of the research on multi-agent deep reinforcement learning (MDRL) offers an encouraging way to coordinate multiple connected and automated vehicles (CAVs) to pass the intersection. In this paper, we apply a value decomposition-based MDRL approach (QMIX) to control various CAVs in mixed-autonomy traffic of different densities to efficiently and safely pass the non-signalized intersection with fairish fuel consumption. Implementation tricks including network-level improvements, Q value update by TD ($\lambda$), and reward clipping operation are added to the pure QMIX framework, which is expected to improve the convergence speed and the asymptotic performance of the original version. The efficacy of our approach is demonstrated by several evaluation metrics: average speed, the number of collisions, and average fuel consumption per episode. The experimental results show that our approach's convergence speed and asymptotic performance can exceed that of the original QMIX and the proximal policy optimization (PPO), a state-of-the-art reinforcement learning baseline applied to the non-signalized intersection. Moreover, CAVs under the lower traffic flow controlled by our method can improve their average speed without collisions and consume the least fuel. The training is additionally conducted under the doubled traffic density, where the learning reward converges. Consequently, the model with maximal reward and minimum crashes can still guarantee low fuel consumption, but slightly reduce the efficiency of vehicles and induce more collisions than the lower-traffic counterpart, implying the difficulty of generalizing RL policy to more advanced scenarios.