 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMART: Scalable Multi-Agent Reasoning and Trajectory Planning in Dense Environments
Sep 19, 2025Multi-vehicle trajectory planning is a non-convex problem that becomes increasingly difficult in dense environments due to the rapid growth of collision constraints. Efficient exploration of feasible behaviors and resolution of tight interactions are essential for real-time, large-scale coordination. This paper introduces SMART, Scalable Multi-Agent Reasoning and Trajectory Planning, a hierarchical framework that combines priority-based search with distributed optimization to achieve efficient and feasible multi-vehicle planning. The upper layer explores diverse interaction modes using reinforcement learning-based priority estimation and large-step hybrid A* search, while the lower layer refines solutions via parallelizable convex optimization. By partitioning space among neighboring vehicles and constructing robust feasible corridors, the method decouples the joint non-convex problem into convex subproblems solved efficiently in parallel. This design alleviates the step-size trade-off while ensuring kinematic feasibility and collision avoidance. Experiments show that SMART consistently outperforms baselines. On 50 m x 50 m maps, it sustains over 90% success within 1 s up to 25 vehicles, while baselines often drop below 50%. On 100 m x 100 m maps, SMART achieves above 95% success up to 50 vehicles and remains feasible up to 90 vehicles, with runtimes more than an order of magnitude faster than optimization-only approaches. Built on vehicle-to-everything communication, SMART incorporates vehicle-infrastructure cooperation through roadside sensing and agent coordination, improving scalability and safety. Real-world experiments further validate this design, achieving planning times as low as 0.014 s while preserving cooperative behaviors.
REACT: Runtime-Enabled Active Collision-avoidance Technique for Autonomous Driving
May 16, 2025Achieving rapid and effective active collision avoidance in dynamic interactive traffic remains a core challenge for autonomous driving. This paper proposes REACT (Runtime-Enabled Active Collision-avoidance Technique), a closed-loop framework that integrates risk assessment with active avoidance control. By leveraging energy transfer principles and human-vehicle-road interaction modeling, REACT dynamically quantifies runtime risk and constructs a continuous spatial risk field. The system incorporates physically grounded safety constraints such as directional risk and traffic rules to identify high-risk zones and generate feasible, interpretable avoidance behaviors. A hierarchical warning trigger strategy and lightweight system design enhance runtime efficiency while ensuring real-time responsiveness. Evaluations across four representative high-risk scenarios including car-following braking, cut-in, rear-approaching, and intersection conflict demonstrate REACT's capability to accurately identify critical risks and execute proactive avoidance. Its risk estimation aligns closely with human driver cognition (i.e., warning lead time < 0.4 s), achieving 100% safe avoidance with zero false alarms or missed detections. Furthermore, it exhibits superior real-time performance (< 50 ms latency), strong foresight, and generalization. The lightweight architecture achieves state-of-the-art accuracy, highlighting its potential for real-time deployment in safety-critical autonomous systems.
RiskNet: Interaction-Aware Risk Forecasting for Autonomous Driving in Long-Tail Scenarios
Apr 22, 2025Ensuring the safety of autonomous vehicles (AVs) in long-tail scenarios remains a critical challenge, particularly under high uncertainty and complex multi-agent interactions. To address this, we propose RiskNet, an interaction-aware risk forecasting framework, which integrates deterministic risk modeling with probabilistic behavior prediction for comprehensive risk assessment. At its core, RiskNet employs a field-theoretic model that captures interactions among ego vehicle, surrounding agents, and infrastructure via interaction fields and force. This model supports multidimensional risk evaluation across diverse scenarios (highways, intersections, and roundabouts), and shows robustness under high-risk and long-tail settings. To capture the behavioral uncertainty, we incorporate a graph neural network (GNN)-based trajectory prediction module, which learns multi-modal future motion distributions. Coupled with the deterministic risk field, it enables dynamic, probabilistic risk inference across time, enabling proactive safety assessment under uncertainty. Evaluations on the highD, inD, and rounD datasets, spanning lane changes, turns, and complex merges, demonstrate that our method significantly outperforms traditional approaches (e.g., TTC, THW, RSS, NC Field) in terms of accuracy, responsiveness, and directional sensitivity, while maintaining strong generalization across scenarios. This framework supports real-time, scenario-adaptive risk forecasting and demonstrates strong generalization across uncertain driving environments. It offers a unified foundation for safety-critical decision-making in long-tail scenarios.
SACA: A Scenario-Aware Collision Avoidance Framework for Autonomous Vehicles Integrating LLMs-Driven Reasoning
Mar 31, 2025Reliable collision avoidance under extreme situations remains a critical challenge for autonomous vehicles. While large language models (LLMs) offer promising reasoning capabilities, their application in safety-critical evasive maneuvers is limited by latency and robustness issues. Even so, LLMs stand out for their ability to weigh emotional, legal, and ethical factors, enabling socially responsible and context-aware collision avoidance. This paper proposes a scenario-aware collision avoidance (SACA) framework for extreme situations by integrating predictive scenario evaluation, data-driven reasoning, and scenario-preview-based deployment to improve collision avoidance decision-making. SACA consists of three key components. First, a predictive scenario analysis module utilizes obstacle reachability analysis and motion intention prediction to construct a comprehensive situational prompt. Second, an online reasoning module refines decision-making by leveraging prior collision avoidance knowledge and fine-tuning with scenario data. Third, an offline evaluation module assesses performance and stores scenarios in a memory bank. Additionally, A precomputed policy method improves deployability by previewing scenarios and retrieving or reasoning policies based on similarity and confidence levels. Real-vehicle tests show that, compared with baseline methods, SACA effectively reduces collision losses in extreme high-risk scenarios and lowers false triggering under complex conditions. Project page: https://sean-shiyuez.github.io/SACA/.
Understanding Driver Cognition and Decision-Making Behaviors in High-Risk Scenarios: A Drift Diffusion Perspective
Mar 16, 2025

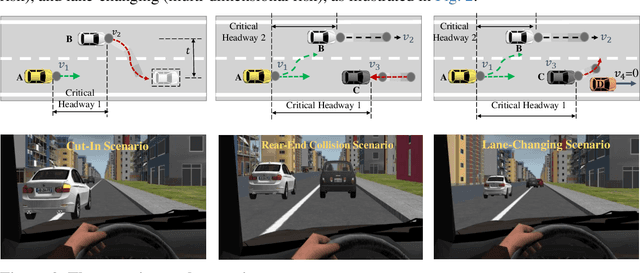
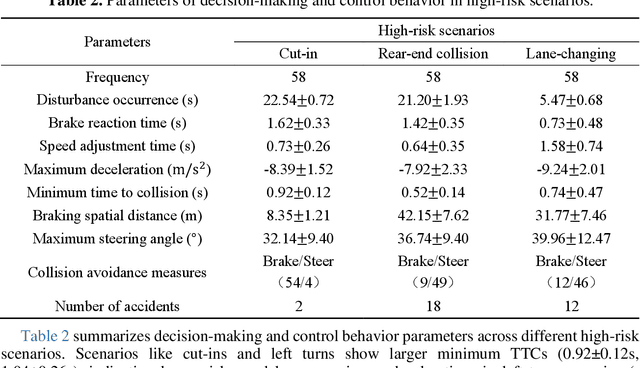
Ensuring safe interactions between autonomous vehicles (AVs) and human drivers in mixed traffic systems remains a major challenge, particularly in complex, high-risk scenarios. This paper presents a cognition-decision framework that integrates individual variability and commonalities in driver behavior to quantify risk cognition and model dynamic decision-making. First, a risk sensitivity model based on a multivariate Gaussian distribution is developed to characterize individual differences in risk cognition. Then, a cognitive decision-making model based on the drift diffusion model (DDM) is introduced to capture common decision-making mechanisms in high-risk environments. The DDM dynamically adjusts decision thresholds by integrating initial bias, drift rate, and boundary parameters, adapting to variations in speed, relative distance, and risk sensitivity to reflect diverse driving styles and risk preferences. By simulating high-risk scenarios with lateral, longitudinal, and multidimensional risk sources in a driving simulator, the proposed model accurately predicts cognitive responses and decision behaviors during emergency maneuvers. Specifically, by incorporating driver-specific risk sensitivity, the model enables dynamic adjustments of key DDM parameters, allowing for personalized decision-making representations in diverse scenarios. Comparative analysis with IDM, Gipps, and MOBIL demonstrates that DDM more precisely captures human cognitive processes and adaptive decision-making in high-risk scenarios. These findings provide a theoretical basis for modeling human driving behavior and offer critical insights for enhancing AV-human interaction in real-world traffic environments.
InVDriver: Intra-Instance Aware Vectorized Query-Based Autonomous Driving Transformer
Feb 25, 2025



End-to-end autonomous driving with its holistic optimization capabilities, has gained increasing traction in academia and industry. Vectorized representations, which preserve instance-level topological information while reducing computational overhead, have emerged as a promising paradigm. While existing vectorized query-based frameworks often overlook the inherent spatial correlations among intra-instance points, resulting in geometrically inconsistent outputs (e.g., fragmented HD map elements or oscillatory trajectories). To address these limitations, we propose InVDriver, a novel vectorized query-based system that systematically models intra-instance spatial dependencies through masked self-attention layers, thereby enhancing planning accuracy and trajectory smoothness. Across all core modules, i.e., perception, prediction, and planning, InVDriver incorporates masked self-attention mechanisms that restrict attention to intra-instance point interactions, enabling coordinated refinement of structural elements while suppressing irrelevant inter-instance noise. Experimental results on the nuScenes benchmark demonstrate that InVDriver achieves state-of-the-art performance, surpassing prior methods in both accuracy and safety, while maintaining high computational efficiency. Our work validates that explicit modeling of intra-instance geometric coherence is critical for advancing vectorized autonomous driving systems, bridging the gap between theoretical advantages of end-to-end frameworks and practical deployment requirements.
Online Adaptive Platoon Control for Connected and Automated Vehicles via Physics Enhanced Residual Learning
Dec 30, 2024This paper introduces a physics enhanced residual learning (PERL) framework for connected and automated vehicle (CAV) platoon control, addressing the dynamics and unpredictability inherent to platoon systems. The framework first develops a physics-based controller to model vehicle dynamics, using driving speed as input to optimize safety and efficiency. Then the residual controller, based on neural network (NN) learning, enriches the prior knowledge of the physical model and corrects residuals caused by vehicle dynamics. By integrating the physical model with data-driven online learning, the PERL framework retains the interpretability and transparency of physics-based models and enhances the adaptability and precision of data-driven learning, achieving significant improvements in computational efficiency and control accuracy in dynamic scenarios. Simulation and robot car platform tests demonstrate that PERL significantly outperforms pure physical and learning models, reducing average cumulative absolute position and speed errors by up to 58.5% and 40.1% (physical model) and 58.4% and 47.7% (NN model). The reduced-scale robot car platform tests further validate the adaptive PERL framework's superior accuracy and rapid convergence under dynamic disturbances, reducing position and speed cumulative errors by 72.73% and 99.05% (physical model) and 64.71% and 72.58% (NN model). PERL enhances platoon control performance through online parameter updates when external disturbances are detected. Results demonstrate the advanced framework's exceptional accuracy and rapid convergence capabilities, proving its effectiveness in maintaining platoon stability under diverse conditions.
SafeDrive: Knowledge- and Data-Driven Risk-Sensitive Decision-Making for Autonomous Vehicles with Large Language Models
Dec 19, 2024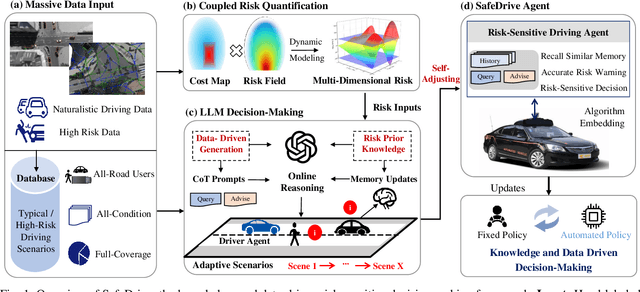
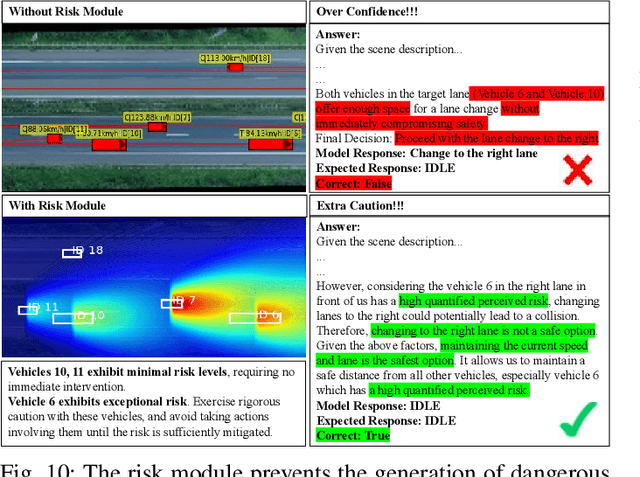
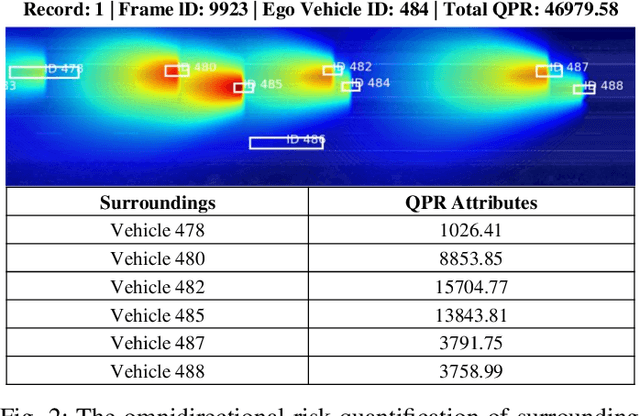
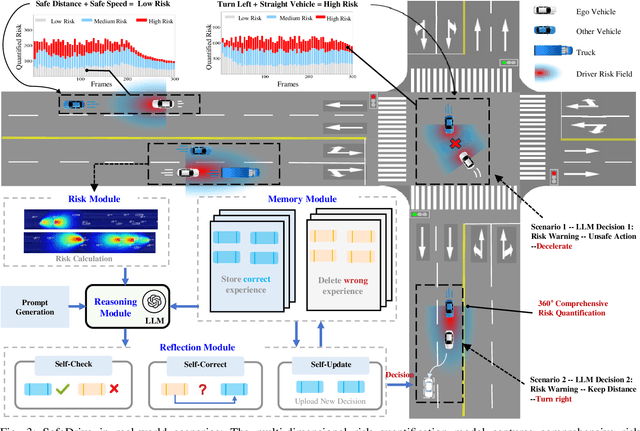
Recent advancements in autonomous vehicles (AVs) use Large Language Models (LLMs) to perform well in normal driving scenarios. However, ensuring safety in dynamic, high-risk environments and managing safety-critical long-tail events remain significant challenges. To address these issues, we propose SafeDrive, a knowledge- and data-driven risk-sensitive decision-making framework to enhance AV safety and adaptability. The proposed framework introduces a modular system comprising: (1) a Risk Module for quantifying multi-factor coupled risks involving driver, vehicle, and road interactions; (2) a Memory Module for storing and retrieving typical scenarios to improve adaptability; (3) a LLM-powered Reasoning Module for context-aware safety decision-making; and (4) a Reflection Module for refining decisions through iterative learning. By integrating knowledge-driven insights with adaptive learning mechanisms, the framework ensures robust decision-making under uncertain conditions. Extensive evaluations on real-world traffic datasets, including highways (HighD), intersections (InD), and roundabouts (RounD), validate the framework's ability to enhance decision-making safety (achieving a 100% safety rate), replicate human-like driving behaviors (with decision alignment exceeding 85%), and adapt effectively to unpredictable scenarios. SafeDrive establishes a novel paradigm for integrating knowledge- and data-driven methods, highlighting significant potential to improve safety and adaptability of autonomous driving in high-risk traffic scenarios. Project Page: https://mezzi33.github.io/SafeDrive/
High-Speed Cornering Control and Real-Vehicle Deployment for Autonomous Electric Vehicles
Nov 18, 2024Executing drift maneuvers during high-speed cornering presents significant challenges for autonomous vehicles, yet offers the potential to minimize turning time and enhance driving dynamics. While reinforcement learning (RL) has shown promising results in simulated environments, discrepancies between simulations and real-world conditions have limited its practical deployment. This study introduces an innovative control framework that integrates trajectory optimization with drift maneuvers, aiming to improve the algorithm's adaptability for real-vehicle implementation. We leveraged Bezier-based pre-trajectory optimization to enhance rewards and optimize the controller through Twin Delayed Deep Deterministic Policy Gradient (TD3) in a simulated environment. For real-world deployment, we implement a hybrid RL-MPC fusion mechanism, , where TD3-derived maneuvers serve as primary inputs for a Model Predictive Controller (MPC). This integration enables precise real-time tracking of the optimal trajectory, with MPC providing corrective inputs to bridge the gap between simulation and reality. The efficacy of this method is validated through real-vehicle tests on consumer-grade electric vehicles, focusing on drift U-turns and drift right-angle turns. The control outcomes of these real-vehicle tests are thoroughly documented in the paper, supported by supplementary video evidence (https://youtu.be/5wp67FcpfL8). Notably, this study is the first to deploy and apply an RL-based transient drift cornering algorithm on consumer-grade electric vehicles.
CSDO: Enhancing Efficiency and Success in Large-Scale Multi-Vehicle Trajectory Planning
May 31, 2024This paper presents an efficient algorithm, naming Centralized Searching and Decentralized Optimization (CSDO), to find feasible solution for large-scale Multi-Vehicle Trajectory Planning (MVTP) problem. Due to the intractable growth of non-convex constraints with the number of agents, exploring various homotopy classes that imply different convex domains, is crucial for finding a feasible solution. However, existing methods struggle to explore various homotopy classes efficiently due to combining it with time-consuming precise trajectory solution finding. CSDO, addresses this limitation by separating them into different levels and integrating an efficient Multi-Agent Path Finding (MAPF) algorithm to search homotopy classes. It first searches for a coarse initial guess using a large search step, identifying a specific homotopy class. Subsequent decentralized Quadratic Programming (QP) refinement processes this guess, resolving minor collisions efficiently. Experimental results demonstrate that CSDO outperforms existing MVTP algorithms in large-scale, high-density scenarios, achieving up to 95% success rate in 50m $\times$ 50m random scenarios around one second. Source codes are released in https://github.com/YangSVM/CSDOTrajectoryPlanning.