 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances and Innovations in the Multi-Agent Robotic System (MARS) Challenge
Jan 26, 2026Recent advancements in multimodal large language models and vision-languageaction models have significantly driven progress in Embodied AI. As the field transitions toward more complex task scenarios, multi-agent system frameworks are becoming essential for achieving scalable, efficient, and collaborative solutions. This shift is fueled by three primary factors: increasing agent capabilities, enhancing system efficiency through task delegation, and enabling advanced human-agent interactions. To address the challenges posed by multi-agent collaboration, we propose the Multi-Agent Robotic System (MARS) Challenge, held at the NeurIPS 2025 Workshop on SpaVLE. The competition focuses on two critical areas: planning and control, where participants explore multi-agent embodied planning using vision-language models (VLMs) to coordinate tasks and policy execution to perform robotic manipulation in dynamic environments. By evaluating solutions submitted by participants, the challenge provides valuable insights into the design and coordination of embodied multi-agent systems, contributing to the future development of advanced collaborative AI systems.
FieldGen: From Teleoperated Pre-Manipulation Trajectories to Field-Guided Data Generation
Oct 23, 2025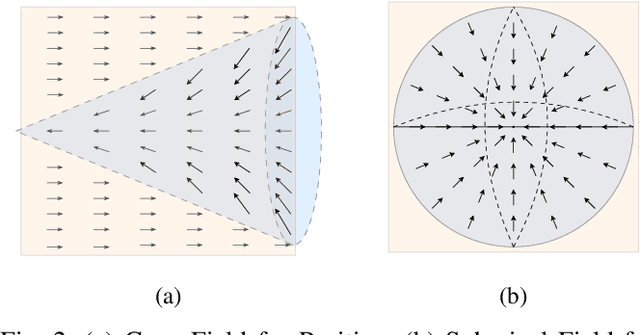

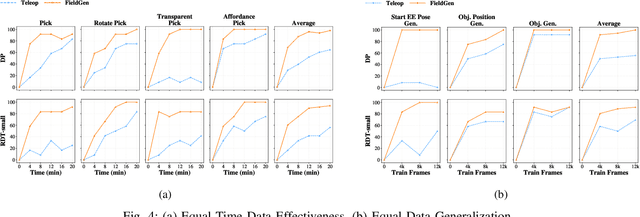

Large-scale and diverse datasets are vital for training robust robotic manipulation policies, yet existing data collection methods struggle to balance scale, diversity, and quality. Simulation offers scalability but suffers from sim-to-real gaps, while teleoperation yields high-quality demonstrations with limited diversity and high labor cost. We introduce FieldGen, a field-guided data generation framework that enables scalable, diverse, and high-quality real-world data collection with minimal human supervision. FieldGen decomposes manipulation into two stages: a pre-manipulation phase, allowing trajectory diversity, and a fine manipulation phase requiring expert precision. Human demonstrations capture key contact and pose information, after which an attraction field automatically generates diverse trajectories converging to successful configurations. This decoupled design combines scalable trajectory diversity with precise supervision. Moreover, FieldGen-Reward augments generated data with reward annotations to further enhance policy learning. Experiments demonstrate that policies trained with FieldGen achieve higher success rates and improved stability compared to teleoperation-based baselines, while significantly reducing human effort in long-term real-world data collection. Webpage is available at https://fieldgen.github.io/.
Expertise need not monopolize: Action-Specialized Mixture of Experts for Vision-Language-Action Learning
Oct 16, 2025Vision-Language-Action (VLA) models are experiencing rapid development and demonstrating promising capabilities in robotic manipulation tasks. However, scaling up VLA models presents several critical challenges: (1) Training new VLA models from scratch demands substantial computational resources and extensive datasets. Given the current scarcity of robot data, it becomes particularly valuable to fully leverage well-pretrained VLA model weights during the scaling process. (2) Real-time control requires carefully balancing model capacity with computational efficiency. To address these challenges, We propose AdaMoE, a Mixture-of-Experts (MoE) architecture that inherits pretrained weights from dense VLA models, and scales up the action expert by substituting the feedforward layers into sparsely activated MoE layers. AdaMoE employs a decoupling technique that decouples expert selection from expert weighting through an independent scale adapter working alongside the traditional router. This enables experts to be selected based on task relevance while contributing with independently controlled weights, allowing collaborative expert utilization rather than winner-takes-all dynamics. Our approach demonstrates that expertise need not monopolize. Instead, through collaborative expert utilization, we can achieve superior performance while maintaining computational efficiency. AdaMoE consistently outperforms the baseline model across key benchmarks, delivering performance gains of 1.8% on LIBERO and 9.3% on RoboTwin. Most importantly, a substantial 21.5% improvement in real-world experiments validates its practical effectiveness for robotic manipulation tasks.
SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
Sep 11, 2025Vision-Language-Action (VLA) models have recently emerged as a powerful paradigm for robotic manipulation. Despite substantial progress enabled by large-scale pretraining and supervised fine-tuning (SFT), these models face two fundamental challenges: (i) the scarcity and high cost of large-scale human-operated robotic trajectories required for SFT scaling, and (ii) limited generalization to tasks involving distribution shift. Recent breakthroughs in Large Reasoning Models (LRMs) demonstrate that reinforcement learning (RL) can dramatically enhance step-by-step reasoning capabilities, raising a natural question: Can RL similarly improve the long-horizon step-by-step action planning of VLA? In this work, we introduce SimpleVLA-RL, an efficient RL framework tailored for VLA models. Building upon veRL, we introduce VLA-specific trajectory sampling, scalable parallelization, multi-environment rendering, and optimized loss computation. When applied to OpenVLA-OFT, SimpleVLA-RL achieves SoTA performance on LIBERO and even outperforms $\pi_0$ on RoboTwin 1.0\&2.0 with the exploration-enhancing strategies we introduce. SimpleVLA-RL not only reduces dependence on large-scale data and enables robust generalization, but also remarkably surpasses SFT in real-world tasks. Moreover, we identify a novel phenomenon ``pushcut'' during RL training, wherein the policy discovers previously unseen patterns beyond those seen in the previous training process. Github: https://github.com/PRIME-RL/SimpleVLA-RL
Discrete Diffusion VLA: Bringing Discrete Diffusion to Action Decoding in Vision-Language-Action Policies
Aug 27, 2025Vision-Language-Action (VLA) models adapt large vision-language backbones to map images and instructions to robot actions. However, prevailing VLA decoders either generate actions autoregressively in a fixed left-to-right order or attach continuous diffusion or flow matching heads outside the backbone, demanding specialized training and iterative sampling that hinder a unified, scalable architecture. We present Discrete Diffusion VLA, a single-transformer policy that models discretized action chunks with discrete diffusion and is trained with the same cross-entropy objective as the VLM backbone. The design retains diffusion's progressive refinement paradigm while remaining natively compatible with the discrete token interface of VLMs. Our method achieves an adaptive decoding order that resolves easy action elements before harder ones and uses secondary remasking to revisit uncertain predictions across refinement rounds, which improves consistency and enables robust error correction. This unified decoder preserves pretrained vision language priors, supports parallel decoding, breaks the autoregressive bottleneck, and reduces the number of function evaluations. Discrete Diffusion VLA achieves 96.3% avg. SR on LIBERO, 71.2% visual matching on SimplerEnv Fractal and 49.3% overall on SimplerEnv Bridge, improving over both autoregressive and continuous diffusion baselines. These findings indicate that discrete-diffusion action decoder supports precise action modeling and consistent training, laying groundwork for scaling VLA to larger models and datasets.
FMimic: Foundation Models are Fine-grained Action Learners from Human Videos
Jul 28, 2025Visual imitation learning (VIL) provides an efficient and intuitive strategy for robotic systems to acquire novel skills. Recent advancements in foundation models, particularly Vision Language Models (VLMs), have demonstrated remarkable capabilities in visual and linguistic reasoning for VIL tasks. Despite this progress, existing approaches primarily utilize these models for learning high-level plans from human demonstrations, relying on pre-defined motion primitives for executing physical interactions, which remains a major bottleneck for robotic systems. In this work, we present FMimic, a novel paradigm that harnesses foundation models to directly learn generalizable skills at even fine-grained action levels, using only a limited number of human videos. Extensive experiments demonstrate that our FMimic delivers strong performance with a single human video, and significantly outperforms all other methods with five videos. Furthermore, our method exhibits significant improvements of over 39% and 29% in RLBench multi-task experiments and real-world manipulation tasks, respectively, and exceeds baselines by more than 34% in high-precision tasks and 47% in long-horizon tasks.
ArtGS:3D Gaussian Splatting for Interactive Visual-Physical Modeling and Manipulation of Articulated Objects
Jul 03, 2025Articulated object manipulation remains a critical challenge in robotics due to the complex kinematic constraints and the limited physical reasoning of existing methods. In this work, we introduce ArtGS, a novel framework that extends 3D Gaussian Splatting (3DGS) by integrating visual-physical modeling for articulated object understanding and interaction. ArtGS begins with multi-view RGB-D reconstruction, followed by reasoning with a vision-language model (VLM) to extract semantic and structural information, particularly the articulated bones. Through dynamic, differentiable 3DGS-based rendering, ArtGS optimizes the parameters of the articulated bones, ensuring physically consistent motion constraints and enhancing the manipulation policy. By leveraging dynamic Gaussian splatting, cross-embodiment adaptability, and closed-loop optimization, ArtGS establishes a new framework for efficient, scalable, and generalizable articulated object modeling and manipulation. Experiments conducted in both simulation and real-world environments demonstrate that ArtGS significantly outperforms previous methods in joint estimation accuracy and manipulation success rates across a variety of articulated objects. Additional images and videos are available on the project website: https://sites.google.com/view/artgs/home
OWMM-Agent: Open World Mobile Manipulation With Multi-modal Agentic Data Synthesis
Jun 04, 2025The rapid progress of navigation, manipulation, and vision models has made mobile manipulators capable in many specialized tasks. However, the open-world mobile manipulation (OWMM) task remains a challenge due to the need for generalization to open-ended instructions and environments, as well as the systematic complexity to integrate high-level decision making with low-level robot control based on both global scene understanding and current agent state. To address this complexity, we propose a novel multi-modal agent architecture that maintains multi-view scene frames and agent states for decision-making and controls the robot by function calling. A second challenge is the hallucination from domain shift. To enhance the agent performance, we further introduce an agentic data synthesis pipeline for the OWMM task to adapt the VLM model to our task domain with instruction fine-tuning. We highlight our fine-tuned OWMM-VLM as the first dedicated foundation model for mobile manipulators with global scene understanding, robot state tracking, and multi-modal action generation in a unified model. Through experiments, we demonstrate that our model achieves SOTA performance compared to other foundation models including GPT-4o and strong zero-shot generalization in real world. The project page is at https://github.com/HHYHRHY/OWMM-Agent
SwarmDiff: Swarm Robotic Trajectory Planning in Cluttered Environments via Diffusion Transformer
May 21, 2025Swarm robotic trajectory planning faces challenges in computational efficiency, scalability, and safety, particularly in complex, obstacle-dense environments. To address these issues, we propose SwarmDiff, a hierarchical and scalable generative framework for swarm robots. We model the swarm's macroscopic state using Probability Density Functions (PDFs) and leverage conditional diffusion models to generate risk-aware macroscopic trajectory distributions, which then guide the generation of individual robot trajectories at the microscopic level. To ensure a balance between the swarm's optimal transportation and risk awareness, we integrate Wasserstein metrics and Conditional Value at Risk (CVaR). Additionally, we introduce a Diffusion Transformer (DiT) to improve sampling efficiency and generation quality by capturing long-range dependencies. Extensive simulations and real-world experiments demonstrate that SwarmDiff outperforms existing methods in computational efficiency, trajectory validity, and scalability, making it a reliable solution for swarm robotic trajectory planning.
AutoBio: A Simulation and Benchmark for Robotic Automation in Digital Biology Laboratory
May 20, 2025Vision-language-action (VLA) models have shown promise as generalist robotic policies by jointly leveraging visual, linguistic, and proprioceptive modalities to generate action trajectories. While recent benchmarks have advanced VLA research in domestic tasks, professional science-oriented domains remain underexplored. We introduce AutoBio, a simulation framework and benchmark designed to evaluate robotic automation in biology laboratory environments--an application domain that combines structured protocols with demanding precision and multimodal interaction. AutoBio extends existing simulation capabilities through a pipeline for digitizing real-world laboratory instruments, specialized physics plugins for mechanisms ubiquitous in laboratory workflows, and a rendering stack that support dynamic instrument interfaces and transparent materials through physically based rendering. Our benchmark comprises biologically grounded tasks spanning three difficulty levels, enabling standardized evaluation of language-guided robotic manipulation in experimental protocols. We provide infrastructure for demonstration generation and seamless integration with VLA models. Baseline evaluations with two SOTA VLA models reveal significant gaps in precision manipulation, visual reasoning, and instruction following in scientific workflows. By releasing AutoBio, we aim to catalyze research on generalist robotic systems for complex, high-precision, and multimodal professional environments. The simulator and benchmark are publicly available to facilitate reproducible research.