 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOA-WAM: Object-Addressable World Action Model for Robust Robot Manipulation
May 07, 2026World Action Models (WAMs) enhance Vision-Language-Action policies by jointly predicting scene evolution and robot actions, but existing methods usually represent the predicted world as holistic images, video tokens, or global latents. These representations are difficult for an action decoder to address when an instruction refers to a particular object, especially under scene shifts where object identity is entangled with context. We propose OA-WAM, an Object-Addressable World Action Model for robust robot manipulation. OA-WAM decomposes each frame into N+1 slot states, with one robot slot and N object slots. Each slot contains a persistent address vector and a time-varying content vector, and is fused with text, image, proprioception, and past-action tokens in a block-causal sequence. A world head predicts next-frame slot states, while a flow-matching action head decodes a 16-step continuous action chunk in the same forward pass. Addressability is enforced by routing cross-slot attention through address-only keys and resetting the address slice at every transformer layer, separating which object to act on from what that object currently is without adding extra tokens. OA-WAM matches strong VLA and WAM baselines on LIBERO (97.8%) and SimplerEnv (79.3%), reaches state-of-the-art performance on the most relevant LIBERO-Plus geometric axes, and remains competitive on the seven-axis aggregate. A causal slot-intervention test yields a swap-binding cosine of 0.87, versus at most 0.09 for holistic baselines. These results suggest that addressable object states provide an effective interface for robust world-action modeling under scene perturbations.
AVR: Active Vision-Driven Robotic Precision Manipulation with Viewpoint and Focal Length Optimization
Mar 03, 2025Robotic manipulation within dynamic environments presents challenges to precise control and adaptability. Traditional fixed-view camera systems face challenges adapting to change viewpoints and scale variations, limiting perception and manipulation precision. To tackle these issues, we propose the Active Vision-driven Robotic (AVR) framework, a teleoperation hardware solution that supports dynamic viewpoint and dynamic focal length adjustments to continuously center targets and maintain optimal scale, accompanied by a corresponding algorithm that effectively enhances the success rates of various operational tasks. Using the RoboTwin platform with a real-time image processing plugin, AVR framework improves task success rates by 5%-16% on five manipulation tasks. Physical deployment on a dual-arm system demonstrates in collaborative tasks and 36% precision in screwdriver insertion, outperforming baselines by over 25%. Experimental results confirm that AVR framework enhances environmental perception, manipulation repeatability (40% $\le $1 cm error), and robustness in complex scenarios, paving the way for future robotic precision manipulation methods in the pursuit of human-level robot dexterity and precision.
Exo-ViHa: A Cross-Platform Exoskeleton System with Visual and Haptic Feedback for Efficient Dexterous Skill Learning
Mar 03, 2025Imitation learning has emerged as a powerful paradigm for robot skills learning. However, traditional data collection systems for dexterous manipulation face challenges, including a lack of balance between acquisition efficiency, consistency, and accuracy. To address these issues, we introduce Exo-ViHa, an innovative 3D-printed exoskeleton system that enables users to collect data from a first-person perspective while providing real-time haptic feedback. This system combines a 3D-printed modular structure with a slam camera, a motion capture glove, and a wrist-mounted camera. Various dexterous hands can be installed at the end, enabling it to simultaneously collect the posture of the end effector, hand movements, and visual data. By leveraging the first-person perspective and direct interaction, the exoskeleton enhances the task realism and haptic feedback, improving the consistency between demonstrations and actual robot deployments. In addition, it has cross-platform compatibility with various robotic arms and dexterous hands. Experiments show that the system can significantly improve the success rate and efficiency of data collection for dexterous manipulation tasks.
A Knowledge Graph Perspective on Supply Chain Resilience
May 15, 2023



Global crises and regulatory developments require increased supply chain transparency and resilience. Companies do not only need to react to a dynamic environment but have to act proactively and implement measures to prevent production delays and reduce risks in the supply chains. However, information about supply chains, especially at the deeper levels, is often intransparent and incomplete, making it difficult to obtain precise predictions about prospective risks. By connecting different data sources, we model the supply network as a knowledge graph and achieve transparency up to tier-3 suppliers. To predict missing information in the graph, we apply state-of-the-art knowledge graph completion methods and attain a mean reciprocal rank of 0.4377 with the best model. Further, we apply graph analysis algorithms to identify critical entities in the supply network, supporting supply chain managers in automated risk identification.
On Calibration of Graph Neural Networks for Node Classification
Jun 03, 2022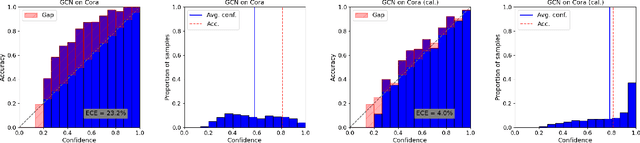
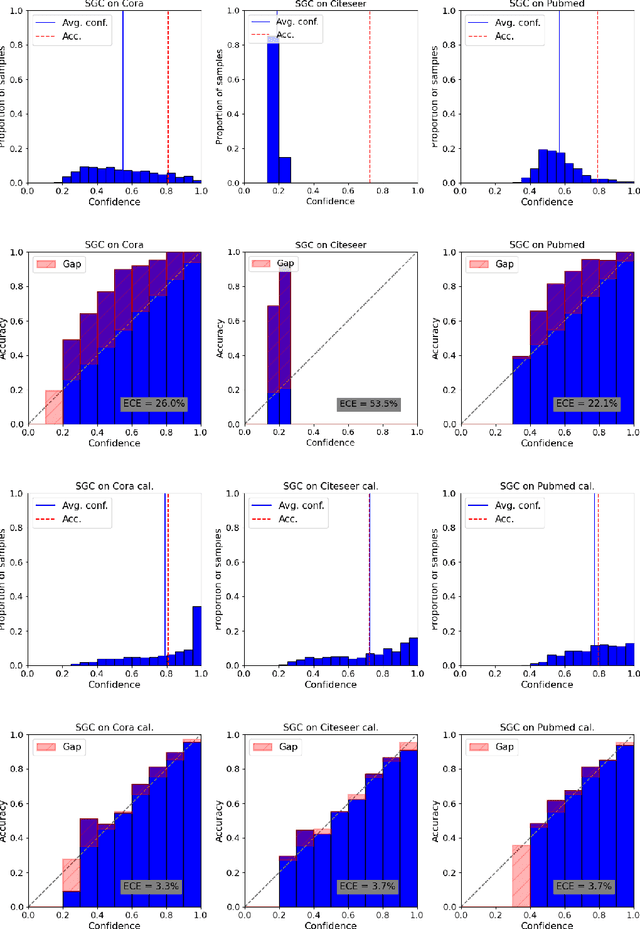
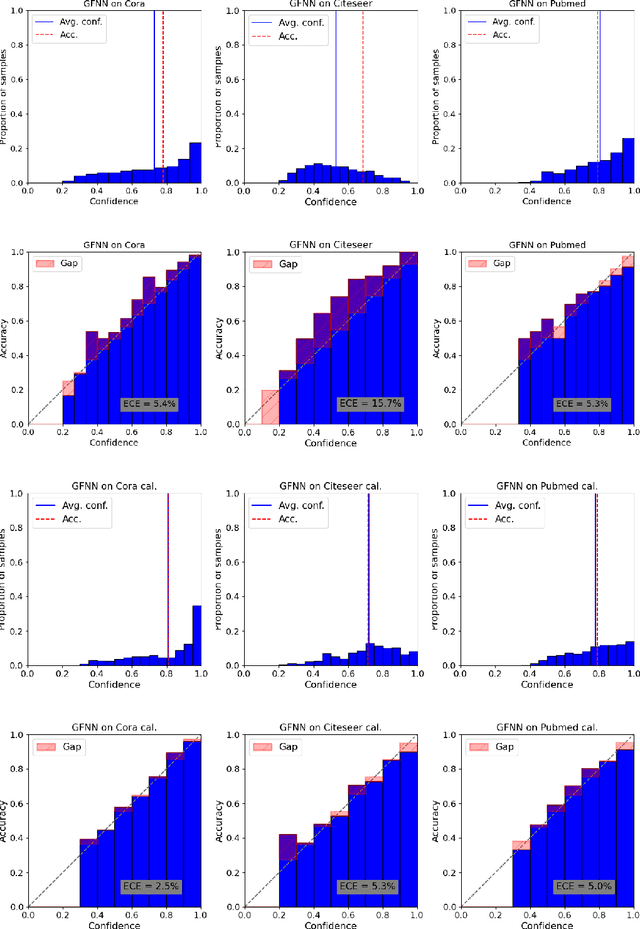
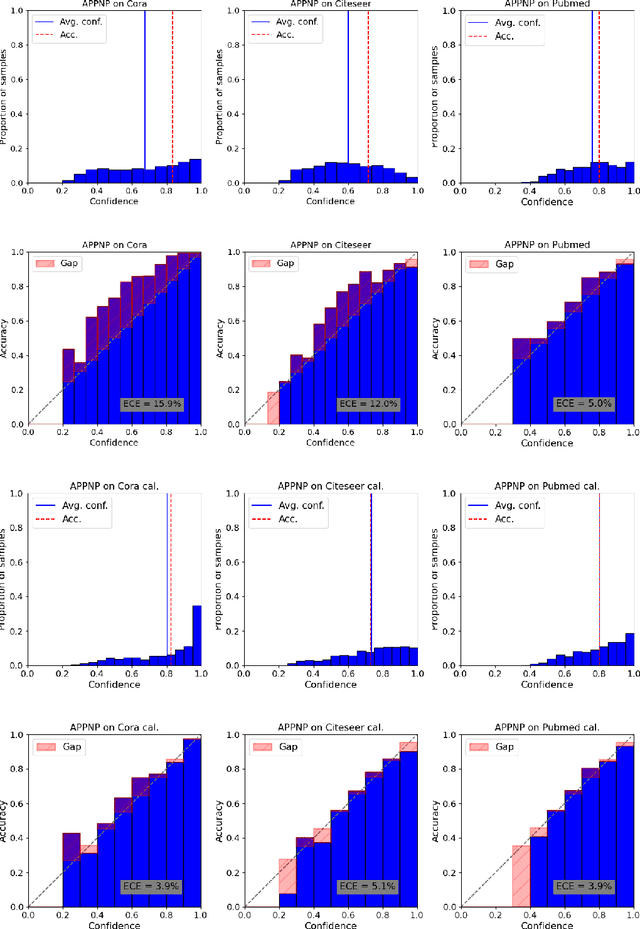
Graphs can model real-world, complex systems by representing entities and their interactions in terms of nodes and edges. To better exploit the graph structure, graph neural networks have been developed, which learn entity and edge embeddings for tasks such as node classification and link prediction. These models achieve good performance with respect to accuracy, but the confidence scores associated with the predictions might not be calibrated. That means that the scores might not reflect the ground-truth probabilities of the predicted events, which would be especially important for safety-critical applications. Even though graph neural networks are used for a wide range of tasks, the calibration thereof has not been sufficiently explored yet. We investigate the calibration of graph neural networks for node classification, study the effect of existing post-processing calibration methods, and analyze the influence of model capacity, graph density, and a new loss function on calibration. Further, we propose a topology-aware calibration method that takes the neighboring nodes into account and yields improved calibration compared to baseline methods.
TLogic: Temporal Logical Rules for Explainable Link Forecasting on Temporal Knowledge Graphs
Dec 15, 2021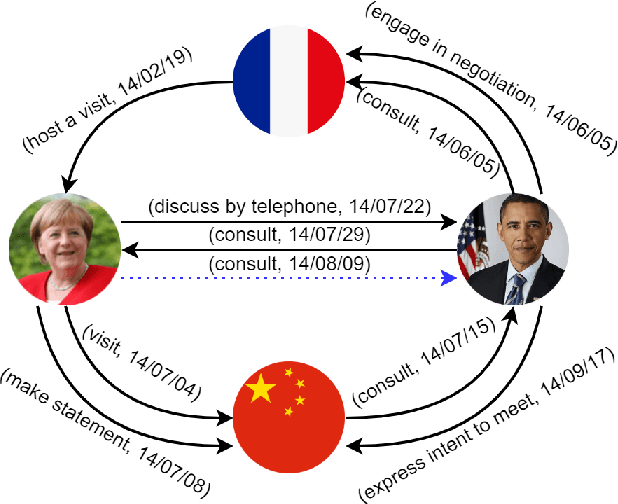
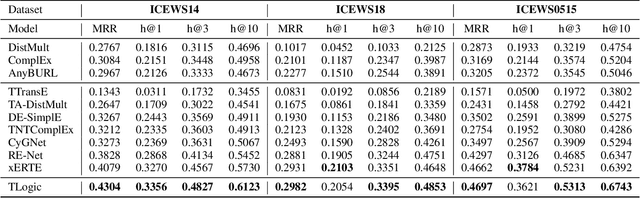

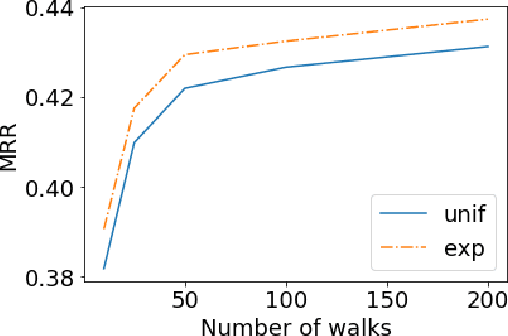
Conventional static knowledge graphs model entities in relational data as nodes, connected by edges of specific relation types. However, information and knowledge evolve continuously, and temporal dynamics emerge, which are expected to influence future situations. In temporal knowledge graphs, time information is integrated into the graph by equipping each edge with a timestamp or a time range. Embedding-based methods have been introduced for link prediction on temporal knowledge graphs, but they mostly lack explainability and comprehensible reasoning chains. Particularly, they are usually not designed to deal with link forecasting -- event prediction involving future timestamps. We address the task of link forecasting on temporal knowledge graphs and introduce TLogic, an explainable framework that is based on temporal logical rules extracted via temporal random walks. We compare TLogic with state-of-the-art baselines on three benchmark datasets and show better overall performance while our method also provides explanations that preserve time consistency. Furthermore, in contrast to most state-of-the-art embedding-based methods, TLogic works well in the inductive setting where already learned rules are transferred to related datasets with a common vocabulary.
Cascaded Channel Estimation for RIS Assisted mmWave MIMO Transmissions
Jun 19, 2021
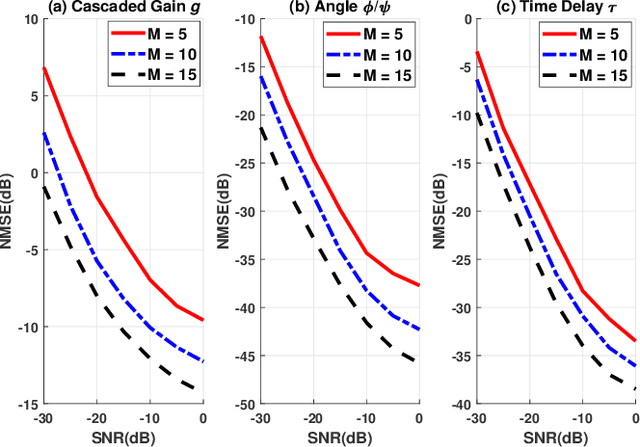
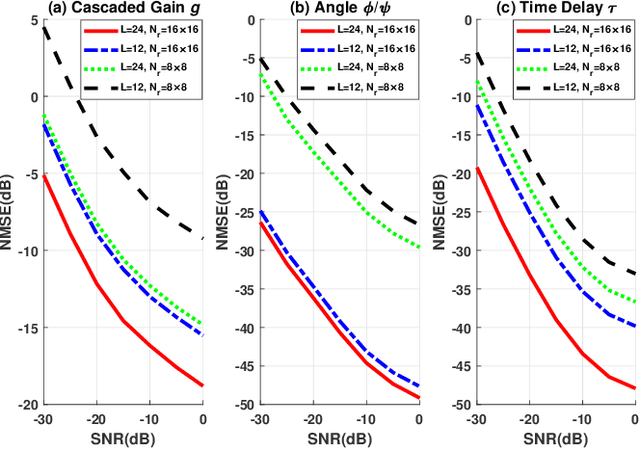
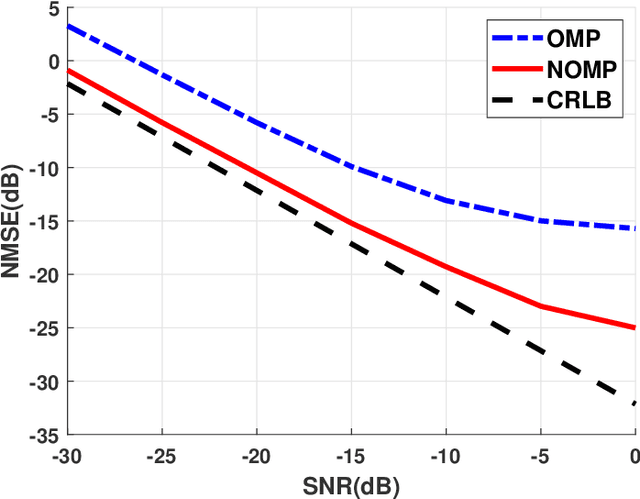
Channel estimation is challenging for the reconfigurable intelligence surface (RIS) assisted millimeter wave (mmWave) communications. Since the number of coefficients of the cascaded channels in such systems is closely dependent on the product of the number of base station antennas and the number of RIS elements, the pilot overhead would be prohibitively high. In this letter, we propose a cascaded channel estimation framework for an RIS assisted mmWave multiple-input multiple-output system, where the wideband effect on transmission model is considered. Then, we transform the wideband channel estimation into a parameter recovery problem and use a few pilot symbols to detect the channel parameters by the Newtonized orthogonal matching pursuit algorithm. Moreover, the Cramer-Rao lower bound on the channel estimation is introduced. Numerical results show the effectiveness of the proposed channel estimation scheme.
Neural Multi-Hop Reasoning With Logical Rules on Biomedical Knowledge Graphs
Mar 18, 2021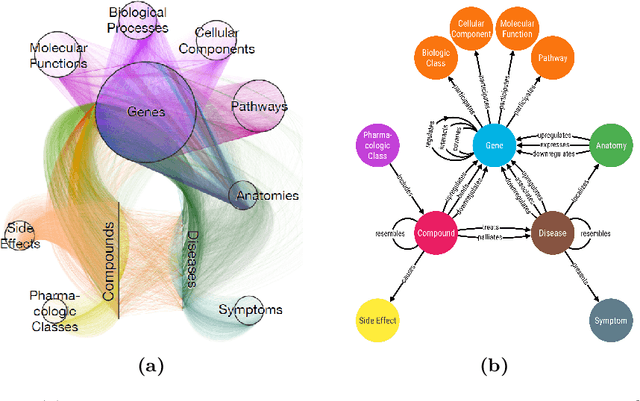

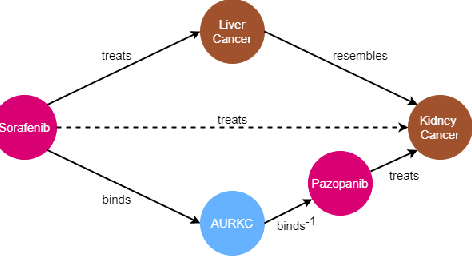

Biomedical knowledge graphs permit an integrative computational approach to reasoning about biological systems. The nature of biological data leads to a graph structure that differs from those typically encountered in benchmarking datasets. To understand the implications this may have on the performance of reasoning algorithms, we conduct an empirical study based on the real-world task of drug repurposing. We formulate this task as a link prediction problem where both compounds and diseases correspond to entities in a knowledge graph. To overcome apparent weaknesses of existing algorithms, we propose a new method, PoLo, that combines policy-guided walks based on reinforcement learning with logical rules. These rules are integrated into the algorithm by using a novel reward function. We apply our method to Hetionet, which integrates biomedical information from 29 prominent bioinformatics databases. Our experiments show that our approach outperforms several state-of-the-art methods for link prediction while providing interpretability.
Deep Learning based Channel Extrapolation for Large-Scale Antenna Systems: Opportunities, Challenges and Solutions
Feb 25, 2021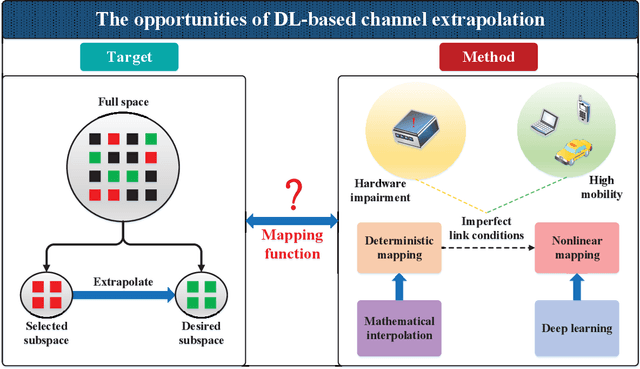
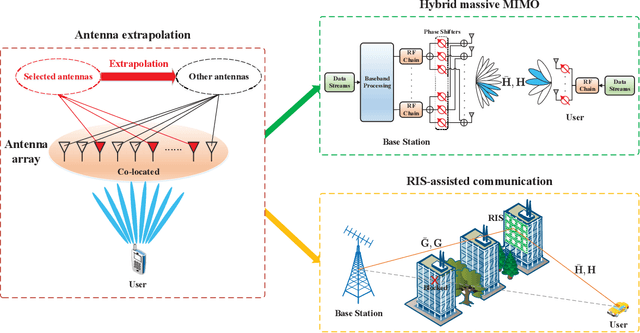
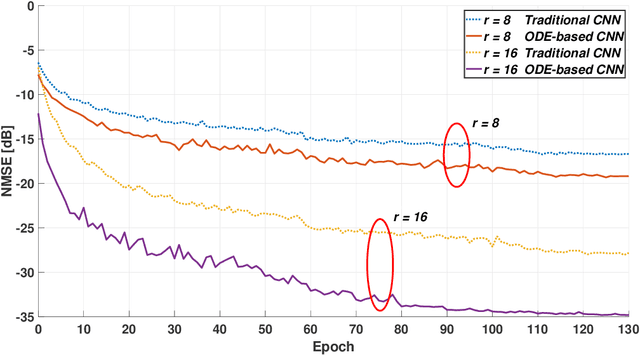
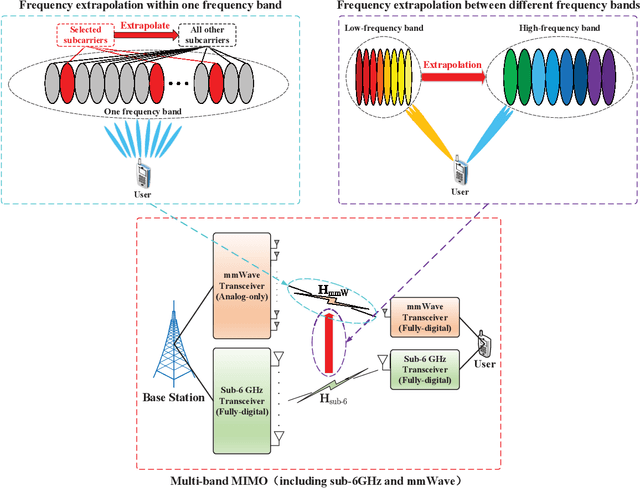
With the depletion of spectrum, wireless communication systems turn to exploit large antenna arrays to achieve the degree of freedom in space domain, such as millimeter wave massive multi-input multioutput (MIMO), reconfigurable intelligent surface assisted communications and cell-free massive MIMO. In these systems, how to acquire accurate channel state information (CSI) is difficult and becomes a bottleneck of the communication links. In this article, we introduce the concept of channel extrapolation that relies on a small portion of channel parameters to infer the remaining channel parameters. Since the substance of channel extrapolation is a mapping from one parameter subspace to another, we can resort to deep learning (DL), a powerful learning architecture, to approximate such mapping function. Specifically, we first analyze the requirements, conditions and challenges for channel extrapolation. Then, we present three typical extrapolations over the antenna dimension, the frequency dimension, and the physical terminal, respectively. We also illustrate their respective principles, design challenges and DL strategies. It will be seen that channel extrapolation could greatly reduce the transmission overhead and subsequently enhance the performance gains compared with the traditional strategies. In the end, we provide several potential research directions on channel extrapolation for future intelligent communications systems.
TIMELY: Improving Labeling Consistency in Medical Imaging for Cell Type Classification
Jul 10, 2020
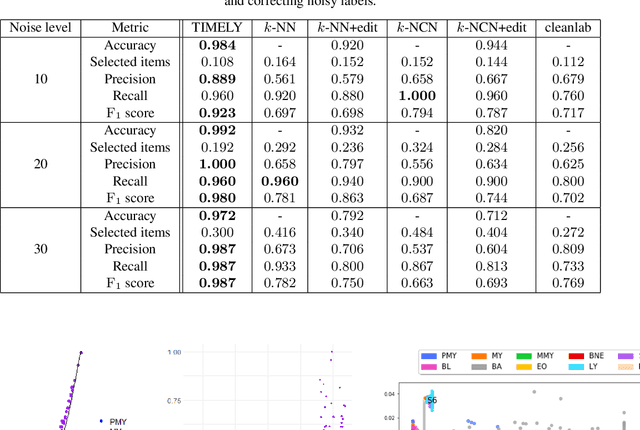
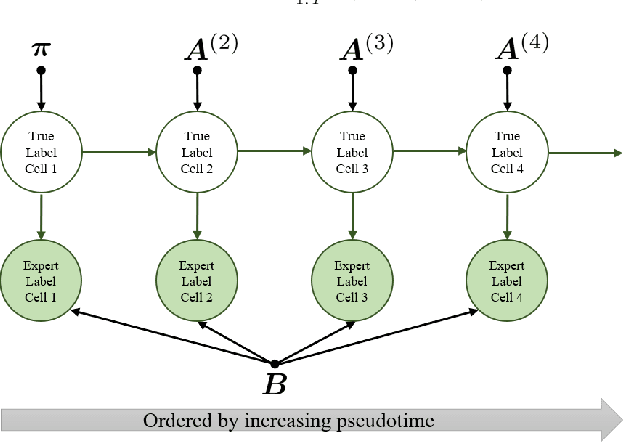
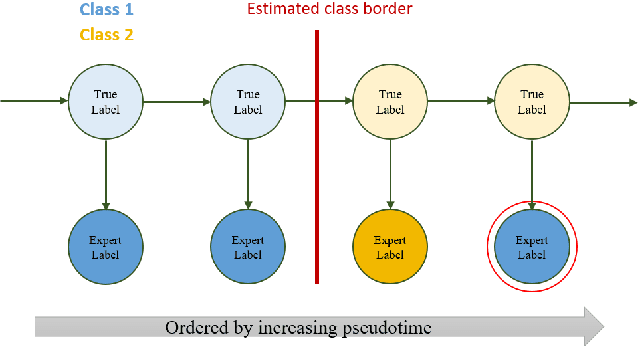
Diagnosing diseases such as leukemia or anemia requires reliable counts of blood cells. Hematologists usually label and count microscopy images of blood cells manually. In many cases, however, cells in different maturity states are difficult to distinguish, and in combination with image noise and subjectivity, humans are prone to make labeling mistakes. This results in labels that are often not reproducible, which can directly affect the diagnoses. We introduce TIMELY, a probabilistic model that combines pseudotime inference methods with inhomogeneous hidden Markov trees, which addresses this challenge of label inconsistency. We show first on simulation data that TIMELY is able to identify and correct wrong labels with higher precision and recall than baseline methods for labeling correction. We then apply our method to two real-world datasets of blood cell data and show that TIMELY successfully finds inconsistent labels, thereby improving the quality of human-generated labels.