 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Role of LLMs in Time Series Forecasting
Feb 16, 2026Large language models (LLMs) have been introduced to time series forecasting (TSF) to incorporate contextual knowledge beyond numerical signals. However, existing studies question whether LLMs provide genuine benefits, often reporting comparable performance without LLMs. We show that such conclusions stem from limited evaluation settings and do not hold at scale. We conduct a large-scale study of LLM-based TSF (LLM4TSF) across 8 billion observations, 17 forecasting scenarios, 4 horizons, multiple alignment strategies, and both in-domain and out-of-domain settings. Our results demonstrate that \emph{LLM4TS indeed improves forecasting performance}, with especially large gains in cross-domain generalization. Pre-alignment outperforming post-alignment in over 90\% of tasks. Both pretrained knowledge and model architecture of LLMs contribute and play complementary roles: pretraining is critical under distribution shifts, while architecture excels at modeling complex temporal dynamics. Moreover, under large-scale mixed distributions, a fully intact LLM becomes indispensable, as confirmed by token-level routing analysis and prompt-based improvements. Overall, Our findings overturn prior negative assessments, establish clear conditions under which LLMs are not only useful, and provide practical guidance for effective model design. We release our code at https://github.com/EIT-NLP/LLM4TSF.
On-Policy Supervised Fine-Tuning for Efficient Reasoning
Feb 13, 2026Large reasoning models (LRMs) are commonly trained with reinforcement learning (RL) to explore long chain-of-thought reasoning, achieving strong performance at high computational cost. Recent methods add multi-reward objectives to jointly optimize correctness and brevity, but these complex extensions often destabilize training and yield suboptimal trade-offs. We revisit this objective and challenge the necessity of such complexity. Through principled analysis, we identify fundamental misalignments in this paradigm: KL regularization loses its intended role when correctness and length are directly verifiable, and group-wise normalization becomes ambiguous under multiple reward signals. By removing these two items and simplifying the reward to a truncation-based length penalty, we show that the optimization problem reduces to supervised fine-tuning on self-generated data filtered for both correctness and conciseness. We term this simplified training strategy on-policy SFT. Despite its simplicity, on-policy SFT consistently defines the accuracy-efficiency Pareto frontier. It reduces CoT length by up to 80 while maintaining original accuracy, surpassing more complex RL-based methods across five benchmarks. Furthermore, it significantly enhances training efficiency, reducing GPU memory usage by 50% and accelerating convergence by 70%. Our code is available at https://github.com/EIT-NLP/On-Policy-SFT.
ViCA: Efficient Multimodal LLMs with Vision-Only Cross-Attention
Feb 07, 2026Modern multimodal large language models (MLLMs) adopt a unified self-attention design that processes visual and textual tokens at every Transformer layer, incurring substantial computational overhead. In this work, we revisit the necessity of such dense visual processing and show that projected visual embeddings are already well-aligned with the language space, while effective vision-language interaction occurs in only a small subset of layers. Based on these insights, we propose ViCA (Vision-only Cross-Attention), a minimal MLLM architecture in which visual tokens bypass all self-attention and feed-forward layers, interacting with text solely through sparse cross-attention at selected layers. Extensive evaluations across three MLLM backbones, nine multimodal benchmarks, and 26 pruning-based baselines show that ViCA preserves 98% of baseline accuracy while reducing visual-side computation to 4%, consistently achieving superior performance-efficiency trade-offs. Moreover, ViCA provides a regular, hardware-friendly inference pipeline that yields over 3.5x speedup in single-batch inference and over 10x speedup in multi-batch inference, reducing visual grounding to near-zero overhead compared with text-only LLMs. It is also orthogonal to token pruning methods and can be seamlessly combined for further efficiency gains. Our code is available at https://github.com/EIT-NLP/ViCA.
Graph is a Substrate Across Data Modalities
Jan 29, 2026Graphs provide a natural representation of relational structure that arises across diverse domains. Despite this ubiquity, graph structure is typically learned in a modality- and task-isolated manner, where graph representations are constructed within individual task contexts and discarded thereafter. As a result, structural regularities across modalities and tasks are repeatedly reconstructed rather than accumulated at the level of intermediate graph representations. This motivates a representation-learning question: how should graph structure be organized so that it can persist and accumulate across heterogeneous modalities and tasks? We adopt a representation-centric perspective in which graph structure is treated as a structural substrate that persists across learning contexts. To instantiate this perspective, we propose G-Substrate, a graph substrate framework that organizes learning around shared graph structures. G-Substrate comprises two complementary mechanisms: a unified structural schema that ensures compatibility among graph representations across heterogeneous modalities and tasks, and an interleaved role-based training strategy that exposes the same graph structure to multiple functional roles during learning. Experiments across multiple domains, modalities, and tasks show that G-Substrate outperforms task-isolated and naive multi-task learning methods.
Policy of Thoughts: Scaling LLM Reasoning via Test-time Policy Evolution
Jan 28, 2026Large language models (LLMs) struggle with complex, long-horizon reasoning due to instability caused by their frozen policy assumption. Current test-time scaling methods treat execution feedback merely as an external signal for filtering or rewriting trajectories, without internalizing it to improve the underlying reasoning strategy. Inspired by Popper's epistemology of "conjectures and refutations," we argue that intelligence requires real-time evolution of the model's policy through learning from failed attempts. We introduce Policy of Thoughts (PoT), a framework that recasts reasoning as a within-instance online optimization process. PoT first generates diverse candidate solutions via an efficient exploration mechanism, then uses Group Relative Policy Optimization (GRPO) to update a transient LoRA adapter based on execution feedback. This closed-loop design enables dynamic, instance-specific refinement of the model's reasoning priors. Experiments show that PoT dramatically boosts performance: a 4B model achieves 49.71% accuracy on LiveCodeBench, outperforming GPT-4o and DeepSeek-V3 despite being over 50 smaller.
The Few Govern the Many:Unveiling Few-Layer Dominance for Time Series Models
Nov 10, 2025Large-scale models are at the forefront of time series (TS) forecasting, dominated by two paradigms: fine-tuning text-based Large Language Models (LLM4TS) and training Time Series Foundation Models (TSFMs) from scratch. Both approaches share a foundational assumption that scaling up model capacity and data volume leads to improved performance. However, we observe a \textit{\textbf{scaling paradox}} in TS models, revealing a puzzling phenomenon that larger models do \emph{NOT} achieve better performance. Through extensive experiments on two model families across four scales (100M to 1.7B parameters) and diverse data (up to 6B observations), we rigorously confirm that the scaling paradox is a pervasive issue. We then diagnose its root cause by analyzing internal representations, identifying a phenomenon we call \textit{few-layer dominance}: only a small subset of layers are functionally important, while the majority are redundant, under-utilized, and can even distract training. Based on this discovery, we propose a practical method to automatically identify and retain only these dominant layers. In our models, retaining only 21\% of the parameters achieves up to a 12\% accuracy improvement and a 2.7$\times$ inference speedup. We validate the universality of our method on 8 prominent SOTA models (LLM4TS and TSFMs, 90M to 6B), showing that retaining less than 30\% of layers achieves comparable or superior accuracy in over 95\% of tasks.
Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning
Aug 27, 2025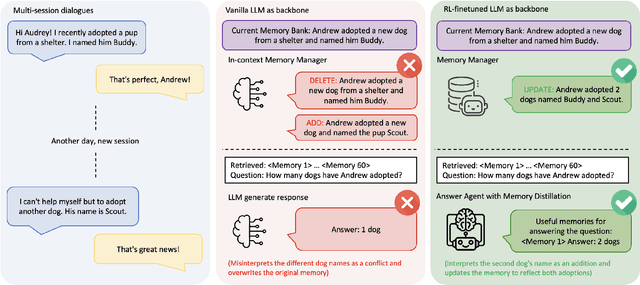
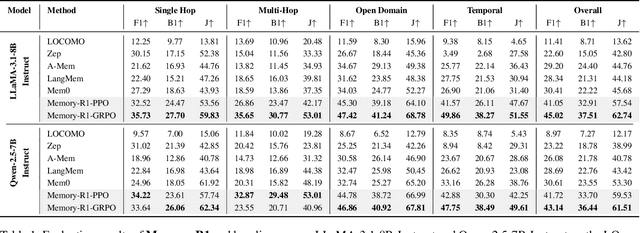
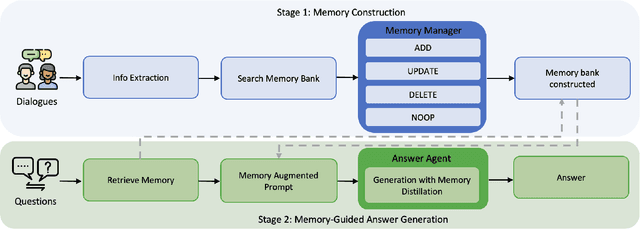

Large Language Models (LLMs) have demonstrated impressive capabilities across a wide range of NLP tasks, but they remain fundamentally stateless, constrained by limited context windows that hinder long-horizon reasoning. Recent efforts to address this limitation often augment LLMs with an external memory bank, yet most existing pipelines are static and heuristic-driven, lacking any learned mechanism for deciding what to store, update, or retrieve. We present Memory-R1, a reinforcement learning (RL) framework that equips LLMs with the ability to actively manage and utilize external memory through two specialized agents: a Memory Manager that learns to perform structured memory operations {ADD, UPDATE, DELETE, NOOP}, and an Answer Agent that selects the most relevant entries and reasons over them to produce an answer. Both agents are fine-tuned with outcome-driven RL (PPO and GRPO), enabling adaptive memory management and use with minimal supervision. With as few as 152 question-answer pairs and a corresponding temporal memory bank for training, Memory-R1 outperforms the most competitive existing baseline and demonstrates strong generalization across diverse question types and LLM backbones. Beyond presenting an effective approach, this work provides insights into how RL can unlock more agentic, memory-aware behaviors in LLMs, pointing toward richer, more persistent reasoning systems.
MV-Debate: Multi-view Agent Debate with Dynamic Reflection Gating for Multimodal Harmful Content Detection in Social Media
Aug 07, 2025Social media has evolved into a complex multimodal environment where text, images, and other signals interact to shape nuanced meanings, often concealing harmful intent. Identifying such intent, whether sarcasm, hate speech, or misinformation, remains challenging due to cross-modal contradictions, rapid cultural shifts, and subtle pragmatic cues. To address these challenges, we propose MV-Debate, a multi-view agent debate framework with dynamic reflection gating for unified multimodal harmful content detection. MV-Debate assembles four complementary debate agents, a surface analyst, a deep reasoner, a modality contrast, and a social contextualist, to analyze content from diverse interpretive perspectives. Through iterative debate and reflection, the agents refine responses under a reflection-gain criterion, ensuring both accuracy and efficiency. Experiments on three benchmark datasets demonstrate that MV-Debate significantly outperforms strong single-model and existing multi-agent debate baselines. This work highlights the promise of multi-agent debate in advancing reliable social intent detection in safety-critical online contexts.
SwarmAgentic: Towards Fully Automated Agentic System Generation via Swarm Intelligence
Jun 18, 2025The rapid progress of Large Language Models has advanced agentic systems in decision-making, coordination, and task execution. Yet, existing agentic system generation frameworks lack full autonomy, missing from-scratch agent generation, self-optimizing agent functionality, and collaboration, limiting adaptability and scalability. We propose SwarmAgentic, a framework for fully automated agentic system generation that constructs agentic systems from scratch and jointly optimizes agent functionality and collaboration as interdependent components through language-driven exploration. To enable efficient search over system-level structures, SwarmAgentic maintains a population of candidate systems and evolves them via feedback-guided updates, drawing inspiration from Particle Swarm Optimization (PSO). We evaluate our method on six real-world, open-ended, and exploratory tasks involving high-level planning, system-level coordination, and creative reasoning. Given only a task description and an objective function, SwarmAgentic outperforms all baselines, achieving a +261.8% relative improvement over ADAS on the TravelPlanner benchmark, highlighting the effectiveness of full automation in structurally unconstrained tasks. This framework marks a significant step toward scalable and autonomous agentic system design, bridging swarm intelligence with fully automated system multi-agent generation. Our code is publicly released at https://yaoz720.github.io/SwarmAgentic/.
ASCD: Attention-Steerable Contrastive Decoding for Reducing Hallucination in MLLM
Jun 17, 2025Multimodal Large Language Model (MLLM) often suffer from hallucinations. They over-rely on partial cues and generate incorrect responses. Recently, methods like Visual Contrastive Decoding (VCD) and Instruction Contrastive Decoding (ICD) have been proposed to mitigate hallucinations by contrasting predictions from perturbed or negatively prefixed inputs against original outputs. In this work, we uncover that methods like VCD and ICD fundamentally influence internal attention dynamics of the model. This observation suggests that their effectiveness may not stem merely from surface-level modifications to logits but from deeper shifts in attention distribution. Inspired by this insight, we propose an attention-steerable contrastive decoding framework that directly intervenes in attention mechanisms of the model to offer a more principled approach to mitigating hallucinations. Our experiments across multiple MLLM architectures and diverse decoding methods demonstrate that our approach significantly reduces hallucinations and improves the performance on benchmarks such as POPE, CHAIR, and MMHal-Bench, while simultaneously enhancing performance on standard VQA benchmarks.