 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASCD: Attention-Steerable Contrastive Decoding for Reducing Hallucination in MLLM
Jun 17, 2025Multimodal Large Language Model (MLLM) often suffer from hallucinations. They over-rely on partial cues and generate incorrect responses. Recently, methods like Visual Contrastive Decoding (VCD) and Instruction Contrastive Decoding (ICD) have been proposed to mitigate hallucinations by contrasting predictions from perturbed or negatively prefixed inputs against original outputs. In this work, we uncover that methods like VCD and ICD fundamentally influence internal attention dynamics of the model. This observation suggests that their effectiveness may not stem merely from surface-level modifications to logits but from deeper shifts in attention distribution. Inspired by this insight, we propose an attention-steerable contrastive decoding framework that directly intervenes in attention mechanisms of the model to offer a more principled approach to mitigating hallucinations. Our experiments across multiple MLLM architectures and diverse decoding methods demonstrate that our approach significantly reduces hallucinations and improves the performance on benchmarks such as POPE, CHAIR, and MMHal-Bench, while simultaneously enhancing performance on standard VQA benchmarks.
Consistent Multimodal Generation via A Unified GAN Framework
Jul 04, 2023We investigate how to generate multimodal image outputs, such as RGB, depth, and surface normals, with a single generative model. The challenge is to produce outputs that are realistic, and also consistent with each other. Our solution builds on the StyleGAN3 architecture, with a shared backbone and modality-specific branches in the last layers of the synthesis network, and we propose per-modality fidelity discriminators and a cross-modality consistency discriminator. In experiments on the Stanford2D3D dataset, we demonstrate realistic and consistent generation of RGB, depth, and normal images. We also show a training recipe to easily extend our pretrained model on a new domain, even with a few pairwise data. We further evaluate the use of synthetically generated RGB and depth pairs for training or fine-tuning depth estimators. Code will be available at https://github.com/jessemelpolio/MultimodalGAN.
Principles and Guidelines for Evaluating Social Robot Navigation Algorithms
Jun 29, 2023



A major challenge to deploying robots widely is navigation in human-populated environments, commonly referred to as social robot navigation. While the field of social navigation has advanced tremendously in recent years, the fair evaluation of algorithms that tackle social navigation remains hard because it involves not just robotic agents moving in static environments but also dynamic human agents and their perceptions of the appropriateness of robot behavior. In contrast, clear, repeatable, and accessible benchmarks have accelerated progress in fields like computer vision, natural language processing and traditional robot navigation by enabling researchers to fairly compare algorithms, revealing limitations of existing solutions and illuminating promising new directions. We believe the same approach can benefit social navigation. In this paper, we pave the road towards common, widely accessible, and repeatable benchmarking criteria to evaluate social robot navigation. Our contributions include (a) a definition of a socially navigating robot as one that respects the principles of safety, comfort, legibility, politeness, social competency, agent understanding, proactivity, and responsiveness to context, (b) guidelines for the use of metrics, development of scenarios, benchmarks, datasets, and simulators to evaluate social navigation, and (c) a design of a social navigation metrics framework to make it easier to compare results from different simulators, robots and datasets.
Socially Compliant Navigation Dataset (SCAND): A Large-Scale Dataset of Demonstrations for Social Navigation
Mar 28, 2022


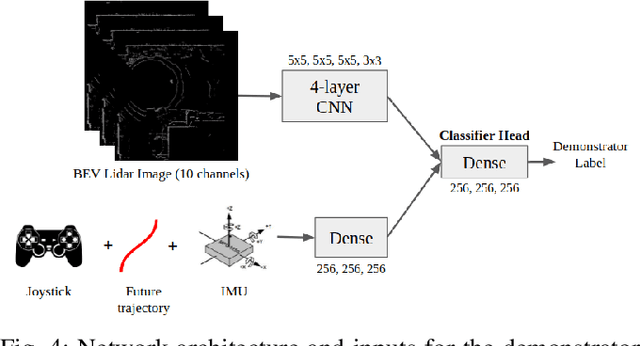
Social navigation is the capability of an autonomous agent, such as a robot, to navigate in a 'socially compliant' manner in the presence of other intelligent agents such as humans. With the emergence of autonomously navigating mobile robots in human populated environments (e.g., domestic service robots in homes and restaurants and food delivery robots on public sidewalks), incorporating socially compliant navigation behaviors on these robots becomes critical to ensuring safe and comfortable human robot coexistence. To address this challenge, imitation learning is a promising framework, since it is easier for humans to demonstrate the task of social navigation rather than to formulate reward functions that accurately capture the complex multi objective setting of social navigation. The use of imitation learning and inverse reinforcement learning to social navigation for mobile robots, however, is currently hindered by a lack of large scale datasets that capture socially compliant robot navigation demonstrations in the wild. To fill this gap, we introduce Socially CompliAnt Navigation Dataset (SCAND) a large scale, first person view dataset of socially compliant navigation demonstrations. Our dataset contains 8.7 hours, 138 trajectories, 25 miles of socially compliant, human teleoperated driving demonstrations that comprises multi modal data streams including 3D lidar, joystick commands, odometry, visual and inertial information, collected on two morphologically different mobile robots a Boston Dynamics Spot and a Clearpath Jackal by four different human demonstrators in both indoor and outdoor environments. We additionally perform preliminary analysis and validation through real world robot experiments and show that navigation policies learned by imitation learning on SCAND generate socially compliant behaviors
Unsupervised Monocular Depth and Ego-motion Learning with Structure and Semantics
Jun 12, 2019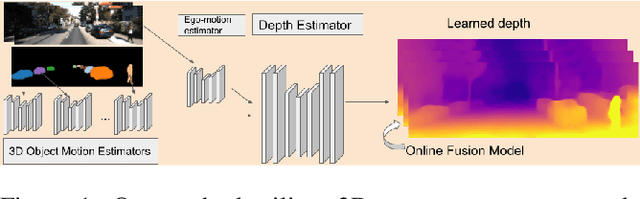
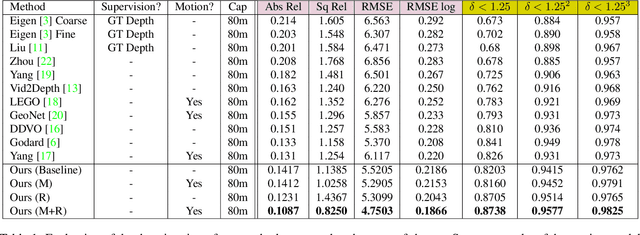
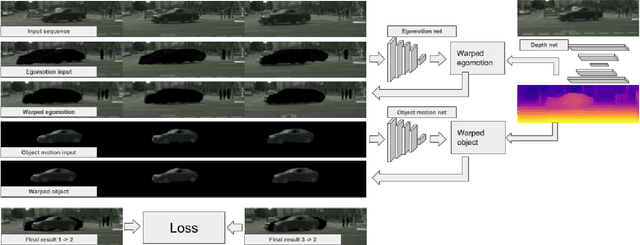

We present an approach which takes advantage of both structure and semantics for unsupervised monocular learning of depth and ego-motion. More specifically, we model the motion of individual objects and learn their 3D motion vector jointly with depth and ego-motion. We obtain more accurate results, especially for challenging dynamic scenes not addressed by previous approaches. This is an extended version of Casser et al. [AAAI'19]. Code and models have been open sourced at https://sites.google.com/corp/view/struct2depth.
Future Segmentation Using 3D Structure
Nov 28, 2018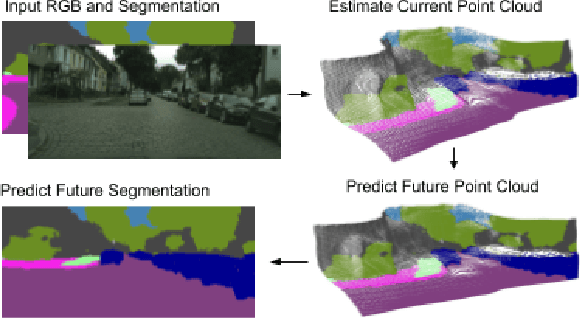

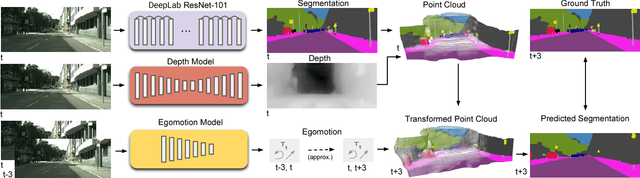

Predicting the future to anticipate the outcome of events and actions is a critical attribute of autonomous agents; particularly for agents which must rely heavily on real time visual data for decision making. Working towards this capability, we address the task of predicting future frame segmentation from a stream of monocular video by leveraging the 3D structure of the scene. Our framework is based on learnable sub-modules capable of predicting pixel-wise scene semantic labels, depth, and camera ego-motion of adjacent frames. We further propose a recurrent neural network based model capable of predicting future ego-motion trajectory as a function of a series of past ego-motion steps. Ultimately, we observe that leveraging 3D structure in the model facilitates successful prediction, achieving state of the art accuracy in future semantic segmentation.
Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos
Nov 15, 2018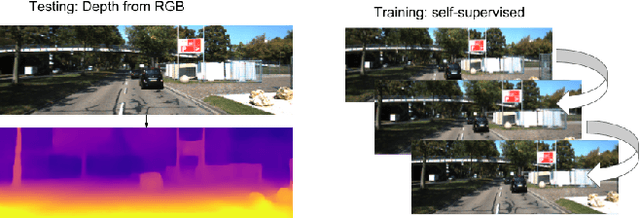
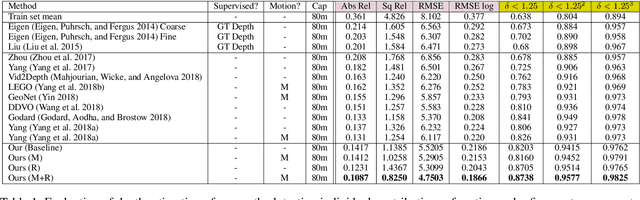
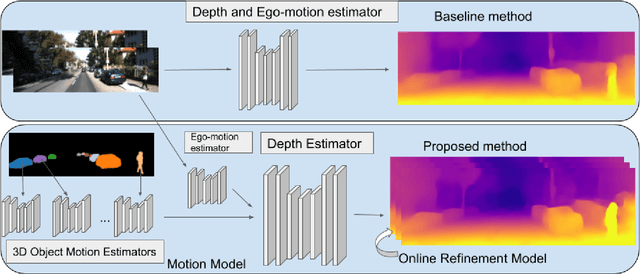

Learning to predict scene depth from RGB inputs is a challenging task both for indoor and outdoor robot navigation. In this work we address unsupervised learning of scene depth and robot ego-motion where supervision is provided by monocular videos, as cameras are the cheapest, least restrictive and most ubiquitous sensor for robotics. Previous work in unsupervised image-to-depth learning has established strong baselines in the domain. We propose a novel approach which produces higher quality results, is able to model moving objects and is shown to transfer across data domains, e.g. from outdoors to indoor scenes. The main idea is to introduce geometric structure in the learning process, by modeling the scene and the individual objects; camera ego-motion and object motions are learned from monocular videos as input. Furthermore an online refinement method is introduced to adapt learning on the fly to unknown domains. The proposed approach outperforms all state-of-the-art approaches, including those that handle motion e.g. through learned flow. Our results are comparable in quality to the ones which used stereo as supervision and significantly improve depth prediction on scenes and datasets which contain a lot of object motion. The approach is of practical relevance, as it allows transfer across environments, by transferring models trained on data collected for robot navigation in urban scenes to indoor navigation settings. The code associated with this paper can be found at https://sites.google.com/view/struct2depth.
Parsing Geometry Using Structure-Aware Shape Templates
Sep 05, 2018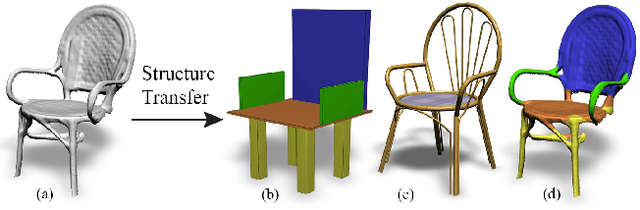
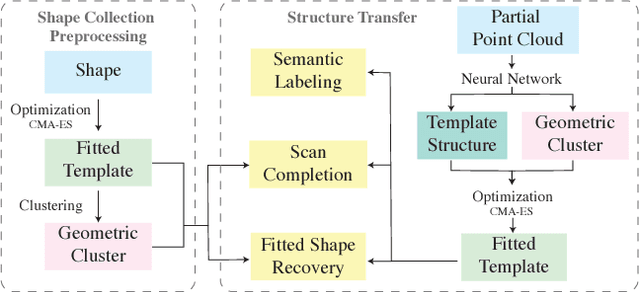
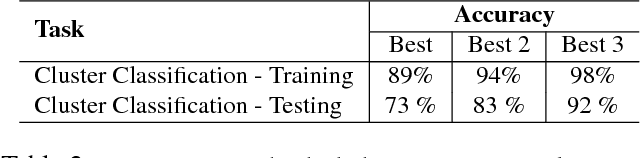
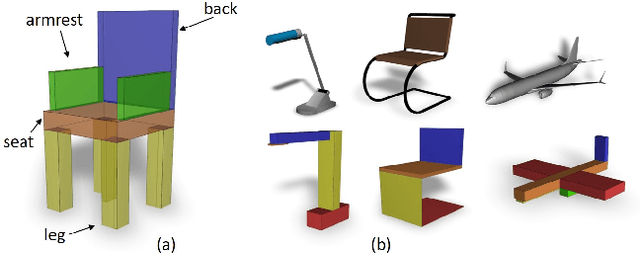
Real-life man-made objects often exhibit strong and easily-identifiable structure, as a direct result of their design or their intended functionality. Structure typically appears in the form of individual parts and their arrangement. Knowing about object structure can be an important cue for object recognition and scene understanding - a key goal for various AR and robotics applications. However, commodity RGB-D sensors used in these scenarios only produce raw, unorganized point clouds, without structural information about the captured scene. Moreover, the generated data is commonly partial and susceptible to artifacts and noise, which makes inferring the structure of scanned objects challenging. In this paper, we organize large shape collections into parameterized shape templates to capture the underlying structure of the objects. The templates allow us to transfer the structural information onto new objects and incomplete scans. We employ a deep neural network that matches the partial scan with one of the shape templates, then match and fit it to complete and detailed models from the collection. This allows us to faithfully label its parts and to guide the reconstruction of the scanned object. We showcase the effectiveness of our method by comparing it to other state-of-the-art approaches.
FPNN: Field Probing Neural Networks for 3D Data
Oct 25, 2016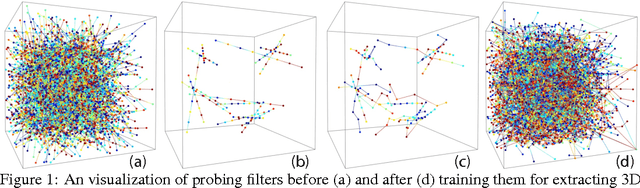
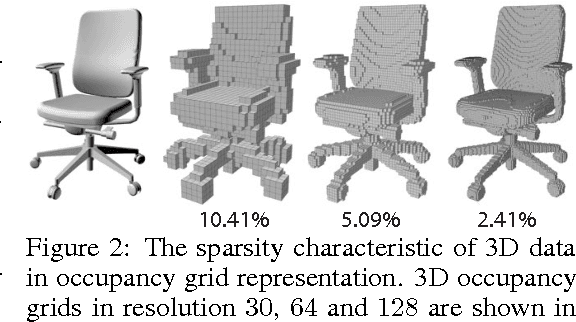
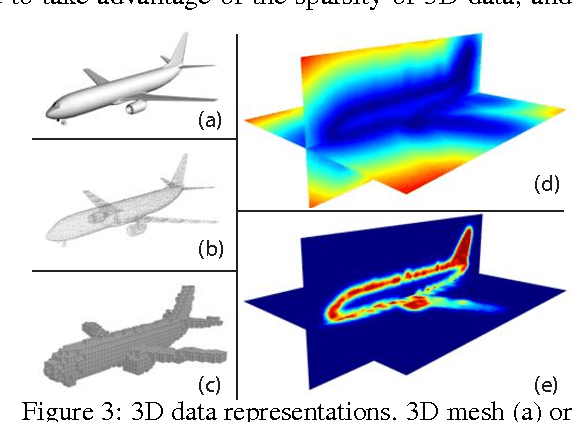
Building discriminative representations for 3D data has been an important task in computer graphics and computer vision research. Convolutional Neural Networks (CNNs) have shown to operate on 2D images with great success for a variety of tasks. Lifting convolution operators to 3D (3DCNNs) seems like a plausible and promising next step. Unfortunately, the computational complexity of 3D CNNs grows cubically with respect to voxel resolution. Moreover, since most 3D geometry representations are boundary based, occupied regions do not increase proportionately with the size of the discretization, resulting in wasted computation. In this work, we represent 3D spaces as volumetric fields, and propose a novel design that employs field probing filters to efficiently extract features from them. Each field probing filter is a set of probing points --- sensors that perceive the space. Our learning algorithm optimizes not only the weights associated with the probing points, but also their locations, which deforms the shape of the probing filters and adaptively distributes them in 3D space. The optimized probing points sense the 3D space "intelligently", rather than operating blindly over the entire domain. We show that field probing is significantly more efficient than 3DCNNs, while providing state-of-the-art performance, on classification tasks for 3D object recognition benchmark datasets.