 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Imitation Learning in Real World Unstructured Social Mini-Games in Pedestrian Crowds
May 26, 2024Imitation Learning (IL) strategies are used to generate policies for robot motion planning and navigation by learning from human trajectories. Recently, there has been a lot of excitement in applying IL in social interactions arising in urban environments such as university campuses, restaurants, grocery stores, and hospitals. However, obtaining numerous expert demonstrations in social settings might be expensive, risky, or even impossible. Current approaches therefore, focus only on simulated social interaction scenarios. This raises the question: \textit{How can a robot learn to imitate an expert demonstrator from real world multi-agent social interaction scenarios}? It remains unknown which, if any, IL methods perform well and what assumptions they require. We benchmark representative IL methods in real world social interaction scenarios on a motion planning task, using a novel pedestrian intersection dataset collected at the University of Texas at Austin campus. Our evaluation reveals two key findings: first, learning multi-agent cost functions is required for learning the diverse behavior modes of agents in tightly coupled interactions and second, conditioning the training of IL methods on partial state information or providing global information in simulation can improve imitation learning, especially in real world social interaction scenarios.
Self-Supervised Terrain Representation Learning from Unconstrained Robot Experience
Sep 26, 2023Terrain awareness, i.e., the ability to identify and distinguish different types of terrain, is a critical ability that robots must have to succeed at autonomous off-road navigation. Current approaches that provide robots with this awareness either rely on labeled data which is expensive to collect, engineered features and cost functions that may not generalize, or expert human demonstrations which may not be available. Towards endowing robots with terrain awareness without these limitations, we introduce Self-supervised TErrain Representation LearnING (STERLING), a novel approach for learning terrain representations that relies solely on easy-to-collect, unconstrained (e.g., non-expert), and unlabelled robot experience, with no additional constraints on data collection. STERLING employs a novel multi-modal self-supervision objective through non-contrastive representation learning to learn relevant terrain representations for terrain-aware navigation. Through physical robot experiments in off-road environments, we evaluate STERLING features on the task of preference-aligned visual navigation and find that STERLING features perform on par with fully supervised approaches and outperform other state-of-the-art methods with respect to preference alignment. Additionally, we perform a large-scale experiment of autonomously hiking a 3-mile long trail which STERLING completes successfully with only two manual interventions, demonstrating its robustness to real-world off-road conditions.
Targeted Learning: A Hybrid Approach to Social Robot Navigation
Sep 23, 2023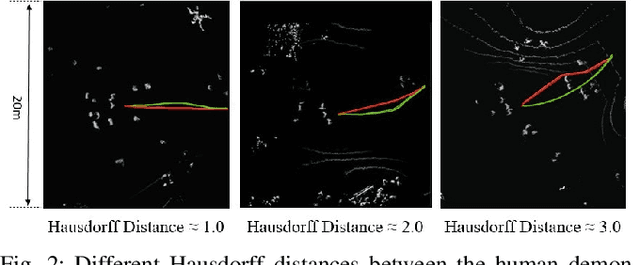



Empowering robots to navigate in a socially compliant manner is essential for the acceptance of robots moving in human-inhabited environments. Previously, roboticists have developed classical navigation systems with decades of empirical validation to achieve safety and efficiency. However, the many complex factors of social compliance make classical navigation systems hard to adapt to social situations, where no amount of tuning enables them to be both safe (people are too unpredictable) and efficient (the frozen robot problem). With recent advances in deep learning approaches, the common reaction has been to entirely discard classical navigation systems and start from scratch, building a completely new learning-based social navigation planner. In this work, we find that this reaction is unnecessarily extreme: using a large-scale real-world social navigation dataset, SCAND, we find that classical systems can be used safely and efficiently in a large number of social situations (up to 80%). We therefore ask if we can rethink this problem by leveraging the advantages of both classical and learning-based approaches. We propose a hybrid strategy in which we learn to switch between a classical geometric planner and a data-driven method. Our experiments on both SCAND and two physical robots show that the hybrid planner can achieve better social compliance in terms of a variety of metrics, compared to using either the classical or learning-based approach alone.
Wait, That Feels Familiar: Learning to Extrapolate Human Preferences for Preference Aligned Path Planning
Sep 18, 2023Autonomous mobility tasks such as lastmile delivery require reasoning about operator indicated preferences over terrains on which the robot should navigate to ensure both robot safety and mission success. However, coping with out of distribution data from novel terrains or appearance changes due to lighting variations remains a fundamental problem in visual terrain adaptive navigation. Existing solutions either require labor intensive manual data recollection and labeling or use handcoded reward functions that may not align with operator preferences. In this work, we posit that operator preferences for visually novel terrains, which the robot should adhere to, can often be extrapolated from established terrain references within the inertial, proprioceptive, and tactile domain. Leveraging this insight, we introduce Preference extrApolation for Terrain awarE Robot Navigation, PATERN, a novel framework for extrapolating operator terrain preferences for visual navigation. PATERN learns to map inertial, proprioceptive, tactile measurements from the robots observations to a representation space and performs nearest neighbor search in this space to estimate operator preferences over novel terrains. Through physical robot experiments in outdoor environments, we assess PATERNs capability to extrapolate preferences and generalize to novel terrains and challenging lighting conditions. Compared to baseline approaches, our findings indicate that PATERN robustly generalizes to diverse terrains and varied lighting conditions, while navigating in a preference aligned manner.
Principles and Guidelines for Evaluating Social Robot Navigation Algorithms
Jun 29, 2023



A major challenge to deploying robots widely is navigation in human-populated environments, commonly referred to as social robot navigation. While the field of social navigation has advanced tremendously in recent years, the fair evaluation of algorithms that tackle social navigation remains hard because it involves not just robotic agents moving in static environments but also dynamic human agents and their perceptions of the appropriateness of robot behavior. In contrast, clear, repeatable, and accessible benchmarks have accelerated progress in fields like computer vision, natural language processing and traditional robot navigation by enabling researchers to fairly compare algorithms, revealing limitations of existing solutions and illuminating promising new directions. We believe the same approach can benefit social navigation. In this paper, we pave the road towards common, widely accessible, and repeatable benchmarking criteria to evaluate social robot navigation. Our contributions include (a) a definition of a socially navigating robot as one that respects the principles of safety, comfort, legibility, politeness, social competency, agent understanding, proactivity, and responsiveness to context, (b) guidelines for the use of metrics, development of scenarios, benchmarks, datasets, and simulators to evaluate social navigation, and (c) a design of a social navigation metrics framework to make it easier to compare results from different simulators, robots and datasets.
Autonomous Ground Navigation in Highly Constrained Spaces: Lessons learned from The BARN Challenge at ICRA 2022
Aug 22, 2022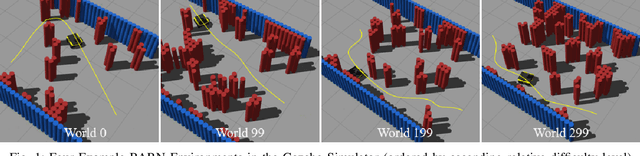


The BARN (Benchmark Autonomous Robot Navigation) Challenge took place at the 2022 IEEE International Conference on Robotics and Automation (ICRA 2022) in Philadelphia, PA. The aim of the challenge was to evaluate state-of-the-art autonomous ground navigation systems for moving robots through highly constrained environments in a safe and efficient manner. Specifically, the task was to navigate a standardized, differential-drive ground robot from a predefined start location to a goal location as quickly as possible without colliding with any obstacles, both in simulation and in the real world. Five teams from all over the world participated in the qualifying simulation competition, three of which were invited to compete with each other at a set of physical obstacle courses at the conference center in Philadelphia. The competition results suggest that autonomous ground navigation in highly constrained spaces, despite seeming ostensibly simple even for experienced roboticists, is actually far from being a solved problem. In this article, we discuss the challenge, the approaches used by the top three winning teams, and lessons learned to direct future research.
High-Speed Accurate Robot Control using Learned Forward Kinodynamics and Non-linear Least Squares Optimization
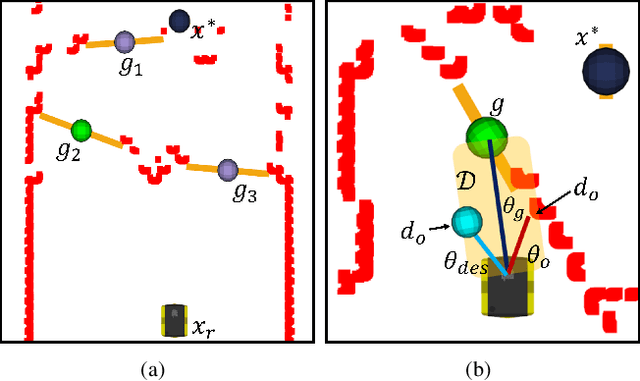
Jun 16, 2022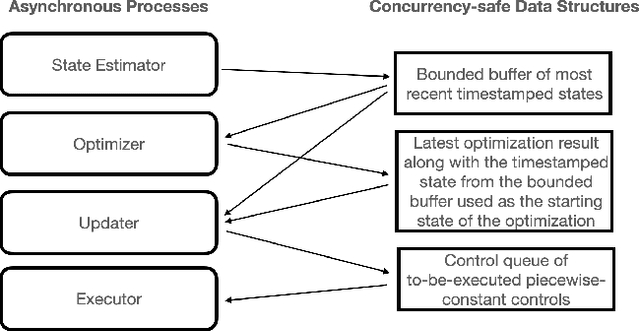
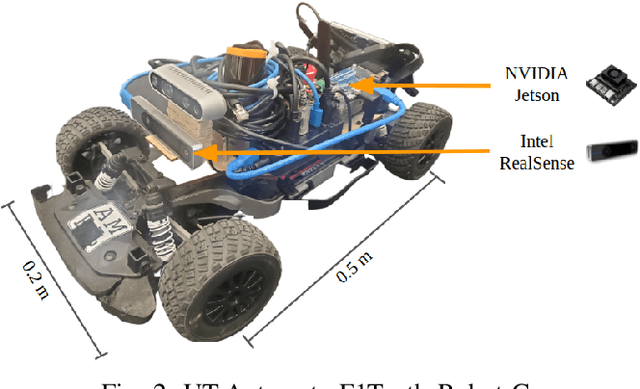
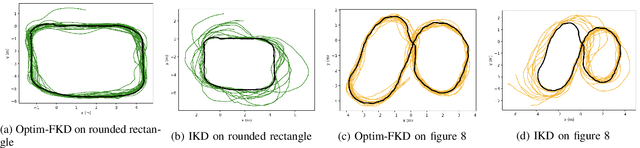
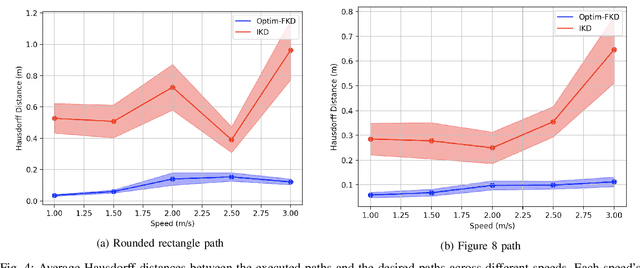
Accurate control of robots in the real world requires a control system that is capable of taking into account the kinodynamic interactions of the robot with its environment. At high speeds, the dependence of the movement of the robot on these kinodynamic interactions becomes more pronounced, making high-speed, accurate robot control a challenging problem. Previous work has shown that learning the inverse kinodynamics (IKD) of the robot can be helpful for high-speed robot control. However a learned inverse kinodynamic model can only be applied to a limited class of control problems, and different control problems require the learning of a new IKD model. In this work we present a new formulation for accurate, high-speed robot control that makes use of a learned forward kinodynamic (FKD) model and non-linear least squares optimization. By nature of the formulation, this approach is extensible to a wide array of control problems without requiring the retraining of a new model. We demonstrate the ability of this approach to accurately control a scale one-tenth robot car at high speeds, and show improved results over baselines.
VI-IKD: High-Speed Accurate Off-Road Navigation using Learned Visual-Inertial Inverse Kinodynamics
Mar 30, 2022
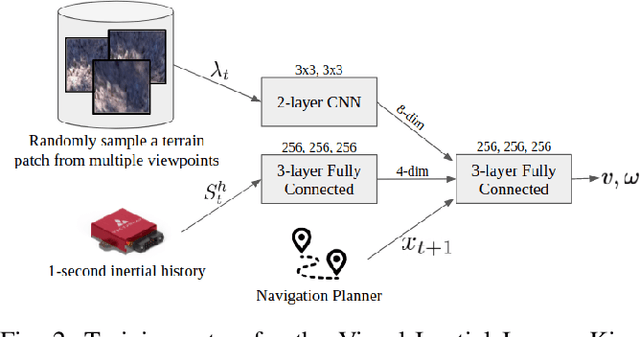


One of the key challenges in high speed off road navigation on ground vehicles is that the kinodynamics of the vehicle terrain interaction can differ dramatically depending on the terrain. Previous approaches to addressing this challenge have considered learning an inverse kinodynamics (IKD) model, conditioned on inertial information of the vehicle to sense the kinodynamic interactions. In this paper, we hypothesize that to enable accurate high-speed off-road navigation using a learned IKD model, in addition to inertial information from the past, one must also anticipate the kinodynamic interactions of the vehicle with the terrain in the future. To this end, we introduce Visual-Inertial Inverse Kinodynamics (VI-IKD), a novel learning based IKD model that is conditioned on visual information from a terrain patch ahead of the robot in addition to past inertial information, enabling it to anticipate kinodynamic interactions in the future. We validate the effectiveness of VI-IKD in accurate high-speed off-road navigation experimentally on a scale 1/5 UT-AlphaTruck off-road autonomous vehicle in both indoor and outdoor environments and show that compared to other state-of-the-art approaches, VI-IKD enables more accurate and robust off-road navigation on a variety of different terrains at speeds of up to 3.5 m/s.
Socially Compliant Navigation Dataset (SCAND): A Large-Scale Dataset of Demonstrations for Social Navigation
Mar 28, 2022


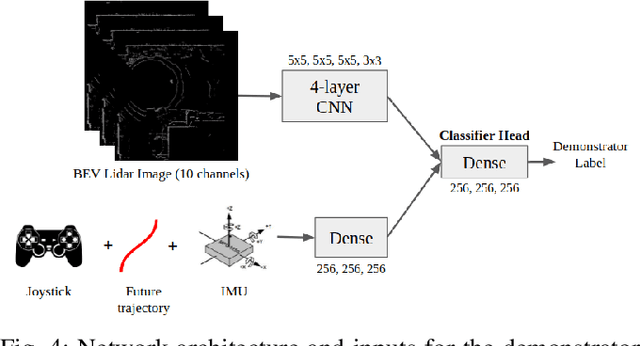
Social navigation is the capability of an autonomous agent, such as a robot, to navigate in a 'socially compliant' manner in the presence of other intelligent agents such as humans. With the emergence of autonomously navigating mobile robots in human populated environments (e.g., domestic service robots in homes and restaurants and food delivery robots on public sidewalks), incorporating socially compliant navigation behaviors on these robots becomes critical to ensuring safe and comfortable human robot coexistence. To address this challenge, imitation learning is a promising framework, since it is easier for humans to demonstrate the task of social navigation rather than to formulate reward functions that accurately capture the complex multi objective setting of social navigation. The use of imitation learning and inverse reinforcement learning to social navigation for mobile robots, however, is currently hindered by a lack of large scale datasets that capture socially compliant robot navigation demonstrations in the wild. To fill this gap, we introduce Socially CompliAnt Navigation Dataset (SCAND) a large scale, first person view dataset of socially compliant navigation demonstrations. Our dataset contains 8.7 hours, 138 trajectories, 25 miles of socially compliant, human teleoperated driving demonstrations that comprises multi modal data streams including 3D lidar, joystick commands, odometry, visual and inertial information, collected on two morphologically different mobile robots a Boston Dynamics Spot and a Clearpath Jackal by four different human demonstrators in both indoor and outdoor environments. We additionally perform preliminary analysis and validation through real world robot experiments and show that navigation policies learned by imitation learning on SCAND generate socially compliant behaviors
Adversarial Imitation Learning from Video using a State Observer
Feb 01, 2022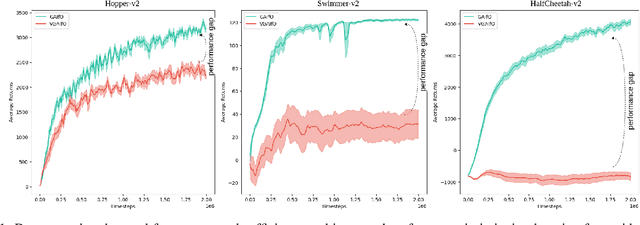
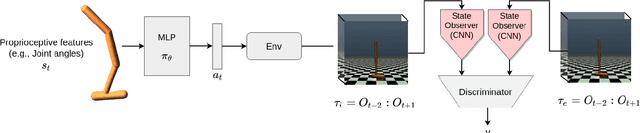
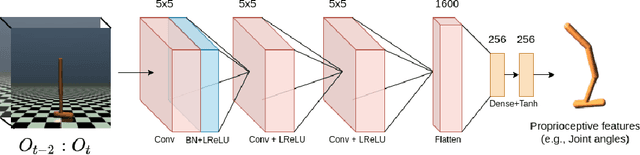
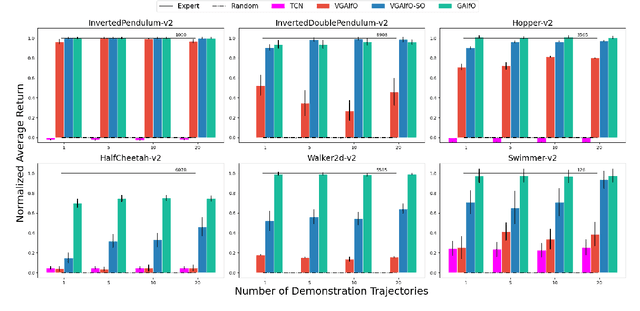
The imitation learning research community has recently made significant progress towards the goal of enabling artificial agents to imitate behaviors from video demonstrations alone. However, current state-of-the-art approaches developed for this problem exhibit high sample complexity due, in part, to the high-dimensional nature of video observations. Towards addressing this issue, we introduce here a new algorithm called Visual Generative Adversarial Imitation from Observation using a State Observer VGAIfO-SO. At its core, VGAIfO-SO seeks to address sample inefficiency using a novel, self-supervised state observer, which provides estimates of lower-dimensional proprioceptive state representations from high-dimensional images. We show experimentally in several continuous control environments that VGAIfO-SO is more sample efficient than other IfO algorithms at learning from video-only demonstrations and can sometimes even achieve performance close to the Generative Adversarial Imitation from Observation (GAIfO) algorithm that has privileged access to the demonstrator's proprioceptive state information.