 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Imitation Learning from Video using a State Observer
Feb 01, 2022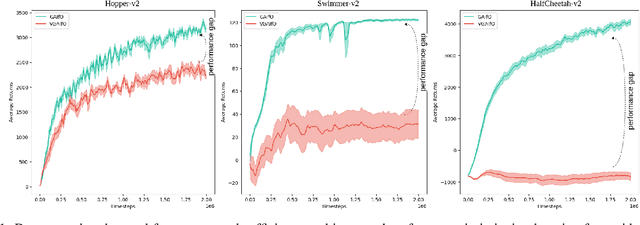
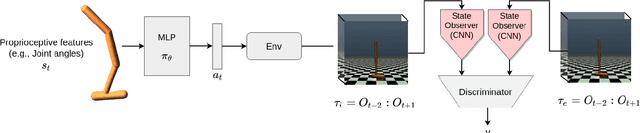
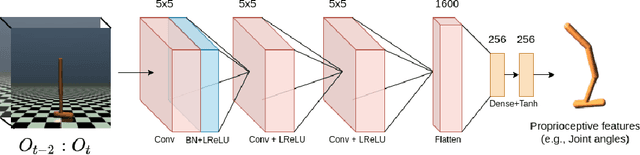
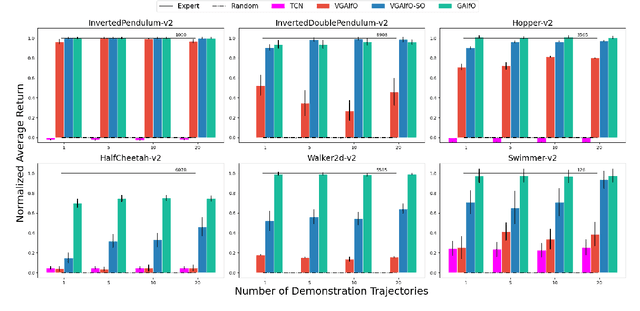
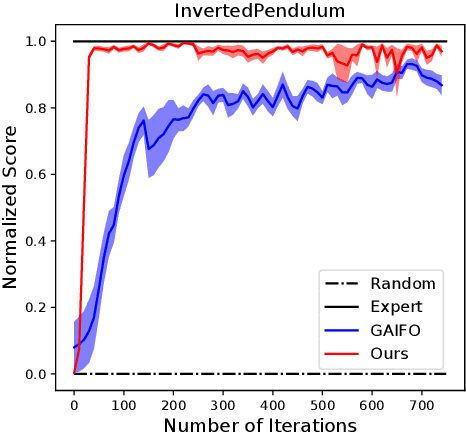
The imitation learning research community has recently made significant progress towards the goal of enabling artificial agents to imitate behaviors from video demonstrations alone. However, current state-of-the-art approaches developed for this problem exhibit high sample complexity due, in part, to the high-dimensional nature of video observations. Towards addressing this issue, we introduce here a new algorithm called Visual Generative Adversarial Imitation from Observation using a State Observer VGAIfO-SO. At its core, VGAIfO-SO seeks to address sample inefficiency using a novel, self-supervised state observer, which provides estimates of lower-dimensional proprioceptive state representations from high-dimensional images. We show experimentally in several continuous control environments that VGAIfO-SO is more sample efficient than other IfO algorithms at learning from video-only demonstrations and can sometimes even achieve performance close to the Generative Adversarial Imitation from Observation (GAIfO) algorithm that has privileged access to the demonstrator's proprioceptive state information.
Recent Advances in Leveraging Human Guidance for Sequential Decision-Making Tasks
Jul 13, 2021
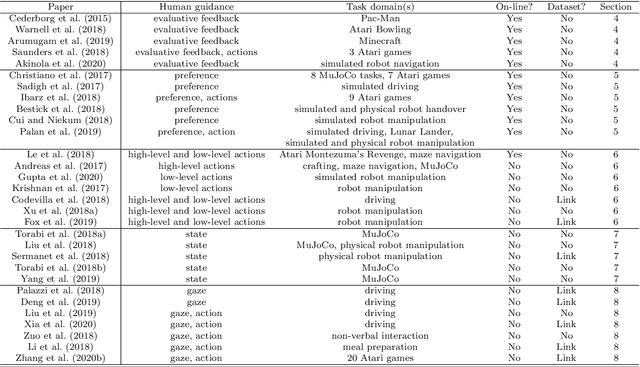
A longstanding goal of artificial intelligence is to create artificial agents capable of learning to perform tasks that require sequential decision making. Importantly, while it is the artificial agent that learns and acts, it is still up to humans to specify the particular task to be performed. Classical task-specification approaches typically involve humans providing stationary reward functions or explicit demonstrations of the desired tasks. However, there has recently been a great deal of research energy invested in exploring alternative ways in which humans may guide learning agents that may, e.g., be more suitable for certain tasks or require less human effort. This survey provides a high-level overview of five recent machine learning frameworks that primarily rely on human guidance apart from pre-specified reward functions or conventional, step-by-step action demonstrations. We review the motivation, assumptions, and implementation of each framework, and we discuss possible future research directions.
* Springer journal, Autonomous Agents and Multi-Agent Systems (JAAMAS)
Skeletal Feature Compensation for Imitation Learning with Embodiment Mismatch
Apr 15, 2021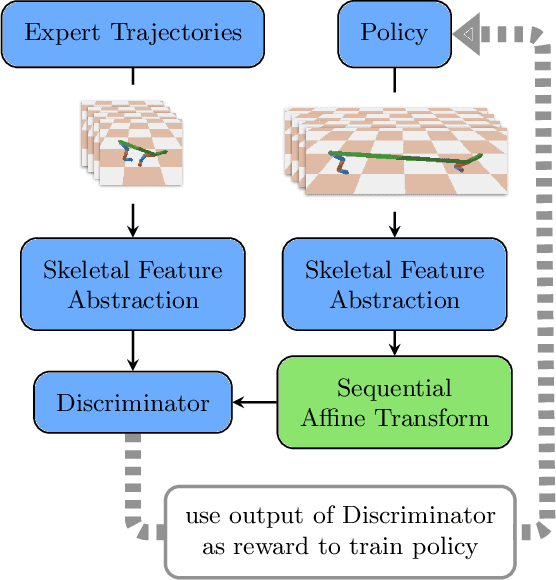

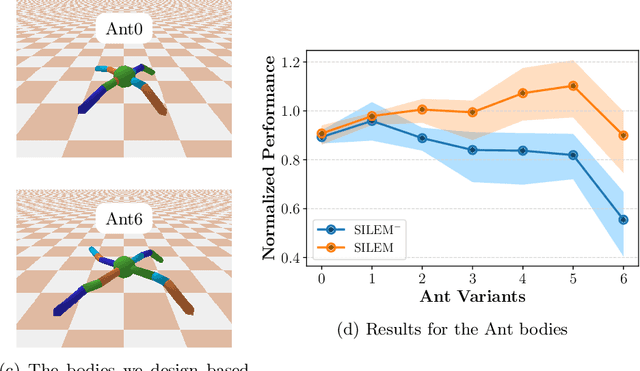
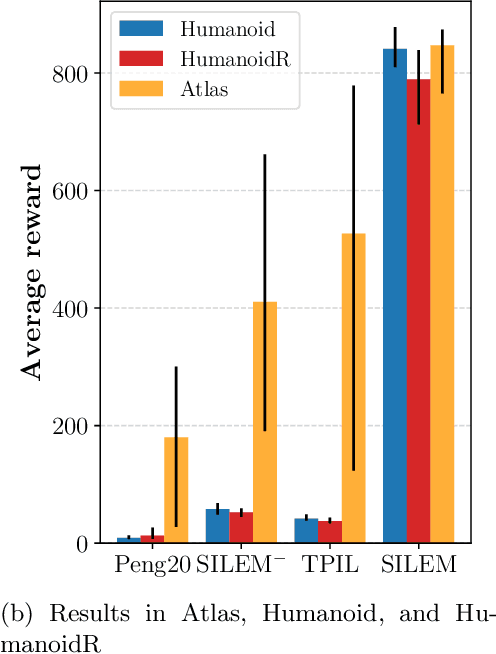
Learning from demonstrations in the wild (e.g. YouTube videos) is a tantalizing goal in imitation learning. However, for this goal to be achieved, imitation learning algorithms must deal with the fact that the demonstrators and learners may have bodies that differ from one another. This condition -- "embodiment mismatch" -- is ignored by many recent imitation learning algorithms. Our proposed imitation learning technique, SILEM (\textbf{S}keletal feature compensation for \textbf{I}mitation \textbf{L}earning with \textbf{E}mbodiment \textbf{M}ismatch), addresses a particular type of embodiment mismatch by introducing a learned affine transform to compensate for differences in the skeletal features obtained from the learner and expert. We create toy domains based on PyBullet's HalfCheetah and Ant to assess SILEM's benefits for this type of embodiment mismatch. We also provide qualitative and quantitative results on more realistic problems -- teaching simulated humanoid agents, including Atlas from Boston Dynamics, to walk by observing human demonstrations.
DEALIO: Data-Efficient Adversarial Learning for Imitation from Observation
Mar 31, 2021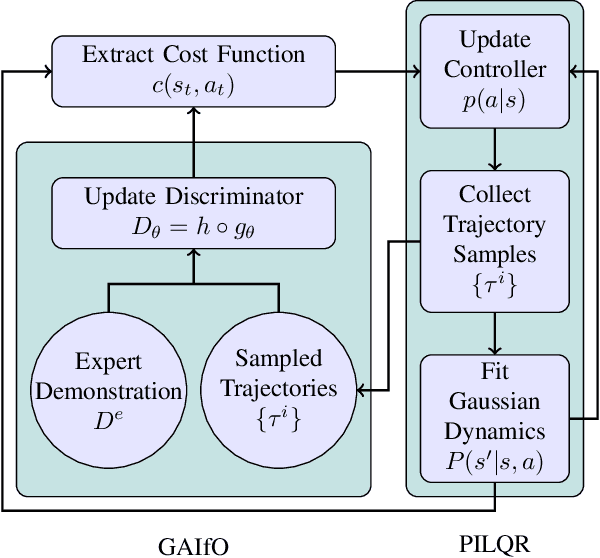
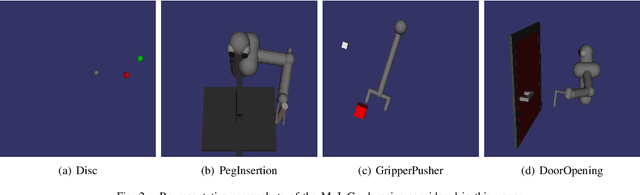
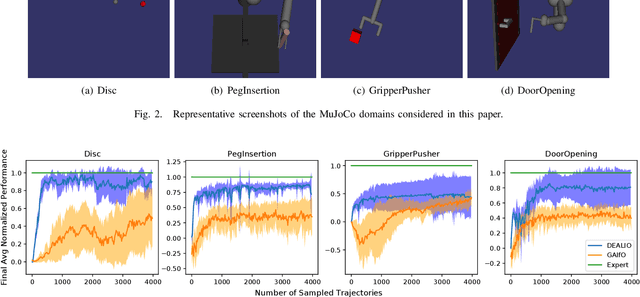
In imitation learning from observation IfO, a learning agent seeks to imitate a demonstrating agent using only observations of the demonstrated behavior without access to the control signals generated by the demonstrator. Recent methods based on adversarial imitation learning have led to state-of-the-art performance on IfO problems, but they typically suffer from high sample complexity due to a reliance on data-inefficient, model-free reinforcement learning algorithms. This issue makes them impractical to deploy in real-world settings, where gathering samples can incur high costs in terms of time, energy, and risk. In this work, we hypothesize that we can incorporate ideas from model-based reinforcement learning with adversarial methods for IfO in order to increase the data efficiency of these methods without sacrificing performance. Specifically, we consider time-varying linear Gaussian policies, and propose a method that integrates the linear-quadratic regulator with path integral policy improvement into an existing adversarial IfO framework. The result is a more data-efficient IfO algorithm with better performance, which we show empirically in four simulation domains: using far fewer interactions with the environment, the proposed method exhibits similar or better performance than the existing technique.
Leveraging Human Guidance for Deep Reinforcement Learning Tasks
Sep 21, 2019
Reinforcement learning agents can learn to solve sequential decision tasks by interacting with the environment. Human knowledge of how to solve these tasks can be incorporated using imitation learning, where the agent learns to imitate human demonstrated decisions. However, human guidance is not limited to the demonstrations. Other types of guidance could be more suitable for certain tasks and require less human effort. This survey provides a high-level overview of five recent learning frameworks that primarily rely on human guidance other than conventional, step-by-step action demonstrations. We review the motivation, assumption, and implementation of each framework. We then discuss possible future research directions.
RIDM: Reinforced Inverse Dynamics Modeling for Learning from a Single Observed Demonstration
Jul 01, 2019
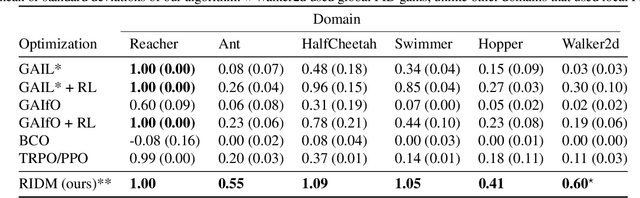

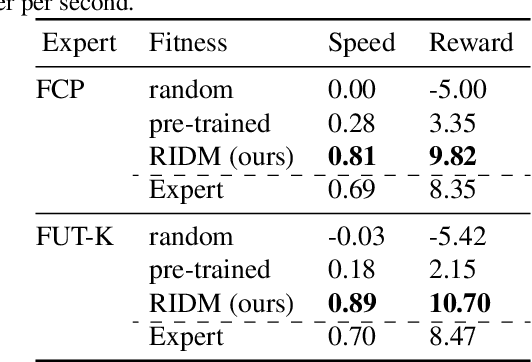
Imitation learning has long been an approach to alleviate the tractability issues that arise in reinforcement learning. However, most literature makes several assumptions such as access to the expert's actions, availability of many expert demonstrations, and injection of task-specific domain knowledge into the learning process. We propose reinforced inverse dynamics modeling (RIDM), a method of combining reinforcement learning and imitation from observation (IfO) to perform imitation using a single expert demonstration, with no access to the expert's actions, and with little task-specific domain knowledge. Given only a single set of the expert's raw states, such as joint angles in a robot control task, at each time-step, we learn an inverse dynamics model to produce the necessary low-level actions, such as torques, to transition from one state to the next such that the reward from the environment is maximized. We demonstrate that RIDM outperforms other techniques when we apply the same constraints on the other methods on six domains of the MuJoCo simulator and for two different robot soccer tasks for two experts from the RoboCup 3D simulation league on the SimSpark simulator.
Sample-efficient Adversarial Imitation Learning from Observation
Jun 18, 2019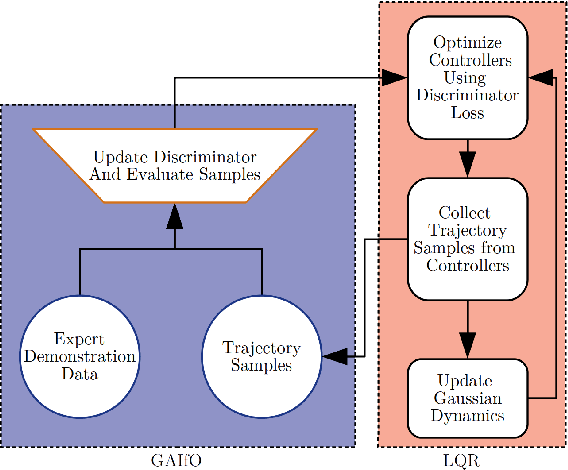

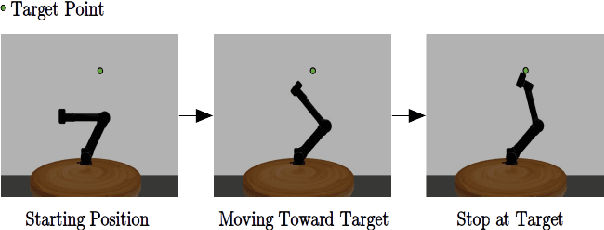
Imitation from observation is the framework of learning tasks by observing demonstrated state-only trajectories. Recently, adversarial approaches have achieved significant performance improvements over other methods for imitating complex behaviors. However, these adversarial imitation algorithms often require many demonstration examples and learning iterations to produce a policy that is successful at imitating a demonstrator's behavior. This high sample complexity often prohibits these algorithms from being deployed on physical robots. In this paper, we propose an algorithm that addresses the sample inefficiency problem by utilizing ideas from trajectory centric reinforcement learning algorithms. We test our algorithm and conduct experiments using an imitation task on a physical robot arm and its simulated version in Gazebo and will show the improvement in learning rate and efficiency.
Recent Advances in Imitation Learning from Observation
May 30, 2019
Imitation learning is the process by which one agent tries to learn how to perform a certain task using information generated by another, often more-expert agent performing that same task. Conventionally, the imitator has access to both state and action information generated by an expert performing the task (e.g., the expert may provide a kinesthetic demonstration of object placement using a robotic arm). However, requiring the action information prevents imitation learning from a large number of existing valuable learning resources such as online videos of humans performing tasks. To overcome this issue, the specific problem of imitation from observation (IfO) has recently garnered a great deal of attention, in which the imitator only has access to the state information (e.g., video frames) generated by the expert. In this paper, we provide a literature review of methods developed for IfO, and then point out some open research problems and potential future work.
Imitation Learning from Video by Leveraging Proprioception
May 22, 2019

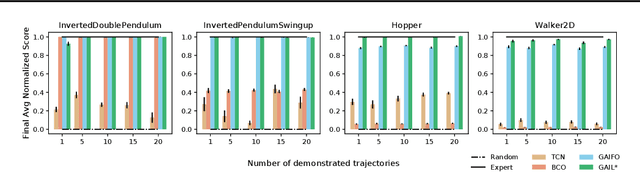
Classically, imitation learning algorithms have been developed for idealized situations, e.g., the demonstrations are often required to be collected in the exact same environment and usually include the demonstrator's actions. Recently, however, the research community has begun to address some of these shortcomings by offering algorithmic solutions that enable imitation learning from observation (IfO), e.g., learning to perform a task from visual demonstrations that may be in a different environment and do not include actions. Motivated by the fact that agents often also have access to their own internal states (i.e., proprioception), we propose and study an IfO algorithm that leverages this information in the policy learning process. The proposed architecture learns policies over proprioceptive state representations and compares the resulting trajectories visually to the demonstration data. We experimentally test the proposed technique on several MuJoCo domains and show that it outperforms other imitation from observation algorithms by a large margin.
Generative Adversarial Imitation from Observation
Jul 17, 2018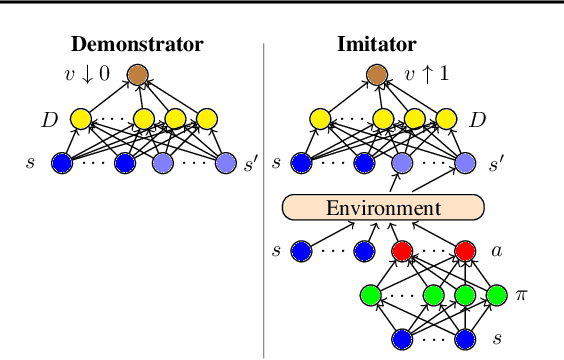
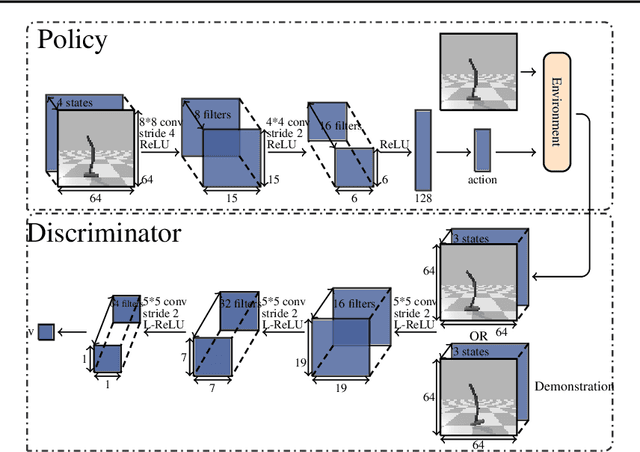
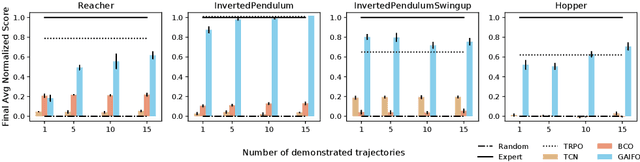
Imitation from observation (IfO) is the problem of learning directly from state-only demonstrations without having access to the demonstrator's actions. The lack of action information both distinguishes IfO from most of the literature in imitation learning, and also sets it apart as a method that may enable agents to learn from large set of previously inapplicable resources such as internet videos. In this paper, we propose both a general framework for IfO approaches and propose a new IfO approach based on generative adversarial networks called generative adversarial imitation from observation (GAIfO). We demonstrate that this approach performs comparably to classical imitation learning approaches (which have access to the demonstrator's actions) and significantly outperforms existing imitation from observation methods in high-dimensional simulation environments.