 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Human Guidance for Deep Reinforcement Learning Tasks
Sep 21, 2019
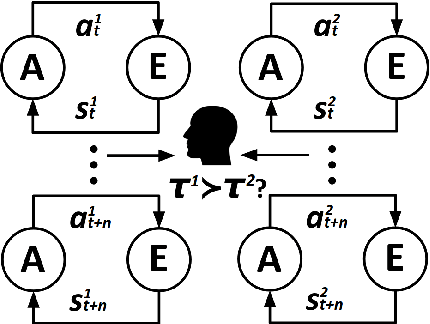
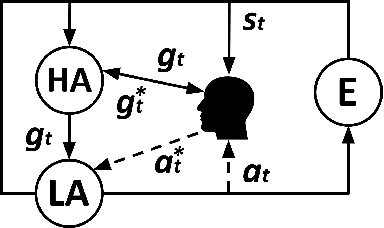
Reinforcement learning agents can learn to solve sequential decision tasks by interacting with the environment. Human knowledge of how to solve these tasks can be incorporated using imitation learning, where the agent learns to imitate human demonstrated decisions. However, human guidance is not limited to the demonstrations. Other types of guidance could be more suitable for certain tasks and require less human effort. This survey provides a high-level overview of five recent learning frameworks that primarily rely on human guidance other than conventional, step-by-step action demonstrations. We review the motivation, assumption, and implementation of each framework. We then discuss possible future research directions.
An Initial Attempt of Combining Visual Selective Attention with Deep Reinforcement Learning
Nov 11, 2018
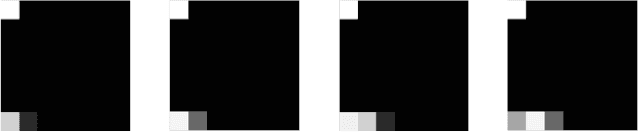

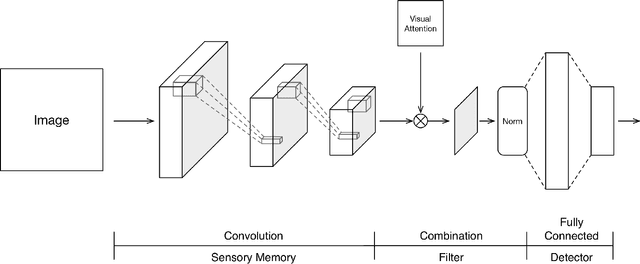
Visual attention serves as a means of feature selection mechanism in the perceptual system. Motivated by Broadbent's leaky filter model of selective attention, we evaluate how such mechanism could be implemented and affect the learning process of deep reinforcement learning. We visualize and analyze the feature maps of DQN on a toy problem Catch, and propose an approach to combine visual selective attention with deep reinforcement learning. We experiment with optical flow-based attention and A2C on Atari games. Experiment results show that visual selective attention could lead to improvements in terms of sample efficiency on tested games. An intriguing relation between attention and batch normalization is also discovered.
AGIL: Learning Attention from Human for Visuomotor Tasks
Jun 01, 2018



When intelligent agents learn visuomotor behaviors from human demonstrations, they may benefit from knowing where the human is allocating visual attention, which can be inferred from their gaze. A wealth of information regarding intelligent decision making is conveyed by human gaze allocation; hence, exploiting such information has the potential to improve the agents' performance. With this motivation, we propose the AGIL (Attention Guided Imitation Learning) framework. We collect high-quality human action and gaze data while playing Atari games in a carefully controlled experimental setting. Using these data, we first train a deep neural network that can predict human gaze positions and visual attention with high accuracy (the gaze network) and then train another network to predict human actions (the policy network). Incorporating the learned attention model from the gaze network into the policy network significantly improves the action prediction accuracy and task performance.