 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterFlywheel: Scaling Iterative Improvement of Engaging and Steerable LLMs in Production
Mar 02, 2026This report presents CharacterFlywheel, an iterative flywheel process for improving large language models (LLMs) in production social chat applications across Instagram, WhatsApp, and Messenger. Starting from LLaMA 3.1, we refined models across 15 generations using data from both internal and external real-user traffic. Through continuous deployments from July 2024 to April 2025, we conducted controlled 7-day A/B tests showing consistent engagement improvements: 7 of 8 newly deployed models demonstrated positive lift over the baseline, with the strongest performers achieving up to 8.8% improvement in engagement breadth and 19.4% in engagement depth. We also observed substantial gains in steerability, with instruction following increasing from 59.2% to 84.8% and instruction violations decreasing from 26.6% to 5.8%. We detail the CharacterFlywheel process which integrates data curation, reward modeling to estimate and interpolate the landscape of engagement metrics, supervised fine-tuning (SFT), reinforcement learning (RL), and both offline and online evaluation to ensure reliable progress at each optimization step. We also discuss our methods for overfitting prevention and navigating production dynamics at scale. These contributions advance the scientific rigor and understanding of LLMs in social applications serving millions of users.
Paying Less Generalization Tax: A Cross-Domain Generalization Study of RL Training for LLM Agents
Jan 26, 2026Generalist LLM agents are often post-trained on a narrow set of environments but deployed across far broader, unseen domains. In this work, we investigate the challenge of agentic post-training when the eventual test domains are unknown. Specifically, we analyze which properties of reinforcement learning (RL) environments and modeling choices have the greatest influence on out-of-domain performance. First, we identify two environment axes that strongly correlate with cross-domain generalization: (i) state information richness, i.e., the amount of information for the agent to process from the state, and (ii) planning complexity, estimated via goal reachability and trajectory length under a base policy. Notably, domain realism and text-level similarity are not the primary factors; for instance, the simple grid-world domain Sokoban leads to even stronger generalization in SciWorld than the more realistic ALFWorld. Motivated by these findings, we further show that increasing state information richness alone can already effectively improve cross-domain robustness. We propose a randomization technique, which is low-overhead and broadly applicable: add small amounts of distractive goal-irrelevant features to the state to make it richer without altering the task. Beyond environment-side properties, we also examine several modeling choices: (a) SFT warmup or mid-training helps prevent catastrophic forgetting during RL but undermines generalization to domains that are not included in the mid-training datamix; and (b) turning on step-by-step thinking during RL, while not always improving in-domain performance, plays a crucial role in preserving generalization.
Scale-Adaptive Power Flow Analysis with Local Topology Slicing and Multi-Task Graph Learning
Jan 04, 2026Developing deep learning models with strong adaptability to topological variations is of great practical significance for power flow analysis. To enhance model performance under variable system scales and improve robustness in branch power prediction, this paper proposes a Scale-adaptive Multi-task Power Flow Analysis (SaMPFA) framework. SaMPFA introduces a Local Topology Slicing (LTS) sampling technique that extracts subgraphs of different scales from the complete power network to strengthen the model's cross-scale learning capability. Furthermore, a Reference-free Multi-task Graph Learning (RMGL) model is designed for robust power flow prediction. Unlike existing approaches, RMGL predicts bus voltages and branch powers instead of phase angles. This design not only avoids the risk of error amplification in branch power calculation but also guides the model to learn the physical relationships of phase angle differences. In addition, the loss function incorporates extra terms that encourage the model to capture the physical patterns of angle differences and power transmission, further improving consistency between predictions and physical laws. Simulations on the IEEE 39-bus system and a real provincial grid in China demonstrate that the proposed model achieves superior adaptability and generalization under variable system scales, with accuracy improvements of 4.47% and 36.82%, respectively.
Make It Long, Keep It Fast: End-to-End 10k-Sequence Modeling at Billion Scale on Douyin
Nov 08, 2025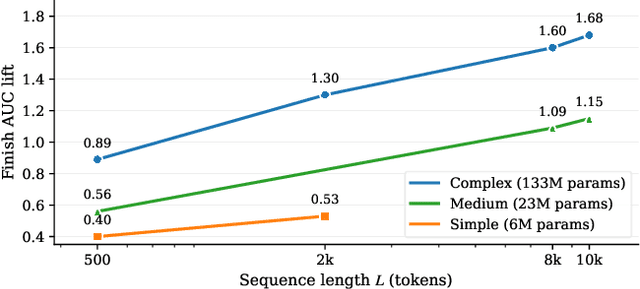
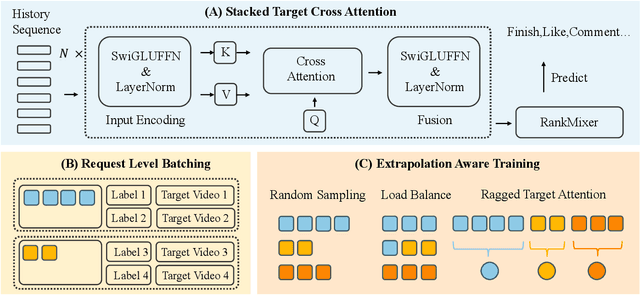

Short-video recommenders such as Douyin must exploit extremely long user histories without breaking latency or cost budgets. We present an end-to-end system that scales long-sequence modeling to 10k-length histories in production. First, we introduce Stacked Target-to-History Cross Attention (STCA), which replaces history self-attention with stacked cross-attention from the target to the history, reducing complexity from quadratic to linear in sequence length and enabling efficient end-to-end training. Second, we propose Request Level Batching (RLB), a user-centric batching scheme that aggregates multiple targets for the same user/request to share the user-side encoding, substantially lowering sequence-related storage, communication, and compute without changing the learning objective. Third, we design a length-extrapolative training strategy -- train on shorter windows, infer on much longer ones -- so the model generalizes to 10k histories without additional training cost. Across offline and online experiments, we observe predictable, monotonic gains as we scale history length and model capacity, mirroring the scaling law behavior observed in large language models. Deployed at full traffic on Douyin, our system delivers significant improvements on key engagement metrics while meeting production latency, demonstrating a practical path to scaling end-to-end long-sequence recommendation to the 10k regime.
TWIN V2: Scaling Ultra-Long User Behavior Sequence Modeling for Enhanced CTR Prediction at Kuaishou
Jul 23, 2024



The significance of modeling long-term user interests for CTR prediction tasks in large-scale recommendation systems is progressively gaining attention among researchers and practitioners. Existing work, such as SIM and TWIN, typically employs a two-stage approach to model long-term user behavior sequences for efficiency concerns. The first stage rapidly retrieves a subset of sequences related to the target item from a long sequence using a search-based mechanism namely the General Search Unit (GSU), while the second stage calculates the interest scores using the Exact Search Unit (ESU) on the retrieved results. Given the extensive length of user behavior sequences spanning the entire life cycle, potentially reaching up to 10^6 in scale, there is currently no effective solution for fully modeling such expansive user interests. To overcome this issue, we introduced TWIN-V2, an enhancement of TWIN, where a divide-and-conquer approach is applied to compress life-cycle behaviors and uncover more accurate and diverse user interests. Specifically, a hierarchical clustering method groups items with similar characteristics in life-cycle behaviors into a single cluster during the offline phase. By limiting the size of clusters, we can compress behavior sequences well beyond the magnitude of 10^5 to a length manageable for online inference in GSU retrieval. Cluster-aware target attention extracts comprehensive and multi-faceted long-term interests of users, thereby making the final recommendation results more accurate and diverse. Extensive offline experiments on a multi-billion-scale industrial dataset and online A/B tests have demonstrated the effectiveness of TWIN-V2. Under an efficient deployment framework, TWIN-V2 has been successfully deployed to the primary traffic that serves hundreds of millions of daily active users at Kuaishou.
Robust Planning with LLM-Modulo Framework: Case Study in Travel Planning
May 31, 2024As the applicability of Large Language Models (LLMs) extends beyond traditional text processing tasks, there is a burgeoning interest in their potential to excel in planning and reasoning assignments, realms traditionally reserved for System 2 cognitive competencies. Despite their perceived versatility, the research community is still unraveling effective strategies to harness these models in such complex domains. The recent discourse introduced by the paper on LLM Modulo marks a significant stride, proposing a conceptual framework that enhances the integration of LLMs into diverse planning and reasoning activities. This workshop paper delves into the practical application of this framework within the domain of travel planning, presenting a specific instance of its implementation. We are using the Travel Planning benchmark by the OSU NLP group, a benchmark for evaluating the performance of LLMs in producing valid itineraries based on user queries presented in natural language. While popular methods of enhancing the reasoning abilities of LLMs such as Chain of Thought, ReAct, and Reflexion achieve a meager 0%, 0.6%, and 0% with GPT3.5-Turbo respectively, our operationalization of the LLM-Modulo framework for TravelPlanning domain provides a remarkable improvement, enhancing baseline performances by 4.6x for GPT4-Turbo and even more for older models like GPT3.5-Turbo from 0% to 5%. Furthermore, we highlight the other useful roles of LLMs in the planning pipeline, as suggested in LLM-Modulo, which can be reliably operationalized such as extraction of useful critics and reformulator for critics.
LLMs Can't Plan, But Can Help Planning in LLM-Modulo Frameworks
Feb 06, 2024
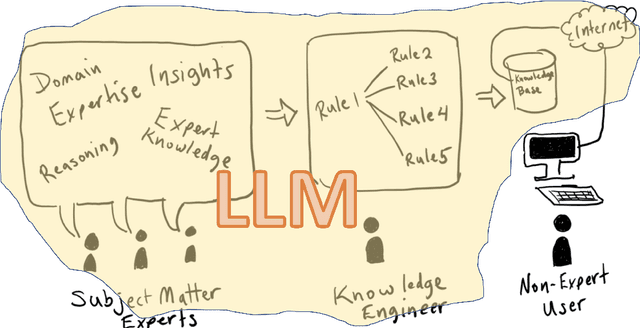
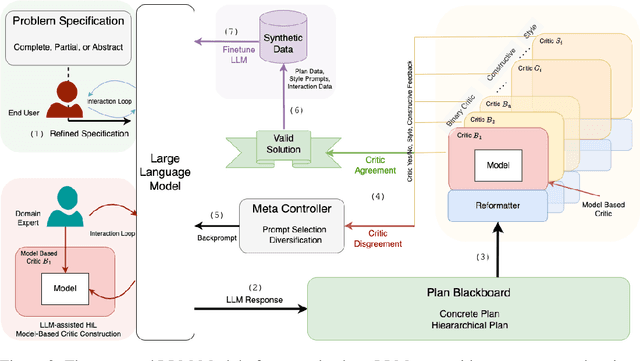
There is considerable confusion about the role of Large Language Models (LLMs) in planning and reasoning tasks. On one side are over-optimistic claims that LLMs can indeed do these tasks with just the right prompting or self-verification strategies. On the other side are perhaps over-pessimistic claims that all that LLMs are good for in planning/reasoning tasks are as mere translators of the problem specification from one syntactic format to another, and ship the problem off to external symbolic solvers. In this position paper, we take the view that both these extremes are misguided. We argue that auto-regressive LLMs cannot, by themselves, do planning or self-verification (which is after all a form of reasoning), and shed some light on the reasons for misunderstandings in the literature. We will also argue that LLMs should be viewed as universal approximate knowledge sources that have much more meaningful roles to play in planning/reasoning tasks beyond simple front-end/back-end format translators. We present a vision of {\bf LLM-Modulo Frameworks} that combine the strengths of LLMs with external model-based verifiers in a tighter bi-directional interaction regime. We will show how the models driving the external verifiers themselves can be acquired with the help of LLMs. We will also argue that rather than simply pipelining LLMs and symbolic components, this LLM-Modulo Framework provides a better neuro-symbolic approach that offers tighter integration between LLMs and symbolic components, and allows extending the scope of model-based planning/reasoning regimes towards more flexible knowledge, problem and preference specifications.
"Task Success" is not Enough: Investigating the Use of Video-Language Models as Behavior Critics for Catching Undesirable Agent Behaviors
Feb 06, 2024Large-scale generative models are shown to be useful for sampling meaningful candidate solutions, yet they often overlook task constraints and user preferences. Their full power is better harnessed when the models are coupled with external verifiers and the final solutions are derived iteratively or progressively according to the verification feedback. In the context of embodied AI, verification often solely involves assessing whether goal conditions specified in the instructions have been met. Nonetheless, for these agents to be seamlessly integrated into daily life, it is crucial to account for a broader range of constraints and preferences beyond bare task success (e.g., a robot should grasp bread with care to avoid significant deformations). However, given the unbounded scope of robot tasks, it is infeasible to construct scripted verifiers akin to those used for explicit-knowledge tasks like the game of Go and theorem proving. This begs the question: when no sound verifier is available, can we use large vision and language models (VLMs), which are approximately omniscient, as scalable Behavior Critics to catch undesirable robot behaviors in videos? To answer this, we first construct a benchmark that contains diverse cases of goal-reaching yet undesirable robot policies. Then, we comprehensively evaluate VLM critics to gain a deeper understanding of their strengths and failure modes. Based on the evaluation, we provide guidelines on how to effectively utilize VLM critiques and showcase a practical way to integrate the feedback into an iterative process of policy refinement. The dataset and codebase are released at: https://guansuns.github.io/pages/vlm-critic.
Leveraging Pre-trained Large Language Models to Construct and Utilize World Models for Model-based Task Planning
May 24, 2023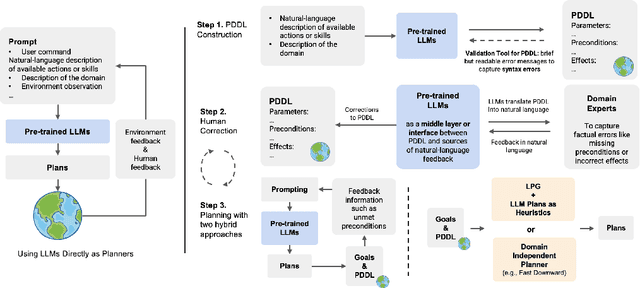

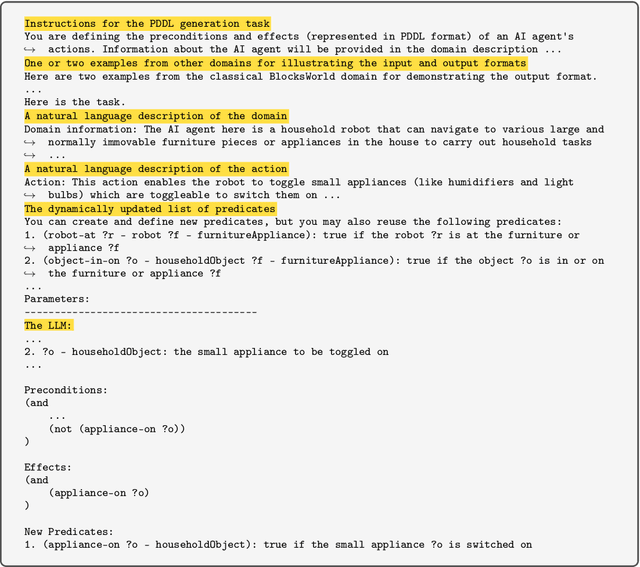
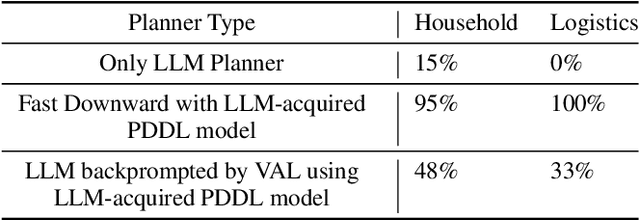
There is a growing interest in applying pre-trained large language models (LLMs) to planning problems. However, methods that use LLMs directly as planners are currently impractical due to several factors, including limited correctness of plans, strong reliance on feedback from interactions with simulators or even the actual environment, and the inefficiency in utilizing human feedback. In this work, we introduce a novel alternative paradigm that constructs an explicit world (domain) model in planning domain definition language (PDDL) and then uses it to plan with sound domain-independent planners. To address the fact that LLMs may not generate a fully functional PDDL model initially, we employ LLMs as an interface between PDDL and sources of corrective feedback, such as PDDL validators and humans. For users who lack a background in PDDL, we show that LLMs can translate PDDL into natural language and effectively encode corrective feedback back to the underlying domain model. Our framework not only enjoys the correctness guarantee offered by the external planners but also reduces human involvement by allowing users to correct domain models at the beginning, rather than inspecting and correcting (through interactive prompting) every generated plan as in previous work. On two IPC domains and a Household domain that is more complicated than commonly used benchmarks such as ALFWorld, we demonstrate that GPT-4 can be leveraged to produce high-quality PDDL models for over 40 actions, and the corrected PDDL models are then used to successfully solve 48 challenging planning tasks. Resources including the source code will be released at: https://guansuns.github.io/pages/llm-dm.
TWIN: TWo-stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou
Feb 05, 2023Life-long user behavior modeling, i.e., extracting a user's hidden interests from rich historical behaviors in months or even years, plays a central role in modern CTR prediction systems. Conventional algorithms mostly follow two cascading stages: a simple General Search Unit (GSU) for fast and coarse search over tens of thousands of long-term behaviors and an Exact Search Unit (ESU) for effective Target Attention (TA) over the small number of finalists from GSU. Although efficient, existing algorithms mostly suffer from a crucial limitation: the \textit{inconsistent} target-behavior relevance metrics between GSU and ESU. As a result, their GSU usually misses highly relevant behaviors but retrieves ones considered irrelevant by ESU. In such case, the TA in ESU, no matter how attention is allocated, mostly deviates from the real user interests and thus degrades the overall CTR prediction accuracy. To address such inconsistency, we propose \textbf{TWo-stage Interest Network (TWIN)}, where our Consistency-Preserved GSU (CP-GSU) adopts the identical target-behavior relevance metric as the TA in ESU, making the two stages twins. Specifically, to break TA's computational bottleneck and extend it from ESU to GSU, or namely from behavior length $10^2$ to length $10^4-10^5$, we build a novel attention mechanism by behavior feature splitting. For the video inherent features of a behavior, we calculate their linear projection by efficient pre-computing \& caching strategies. And for the user-item cross features, we compress each into a one-dimentional bias term in the attention score calculation to save the computational cost. The consistency between two stages, together with the effective TA-based relevance metric in CP-GSU, contributes to significant performance gain in CTR prediction.