 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMethods and Mechanisms for Interactive Novelty Handling in Adversarial Environments
Mar 06, 2023
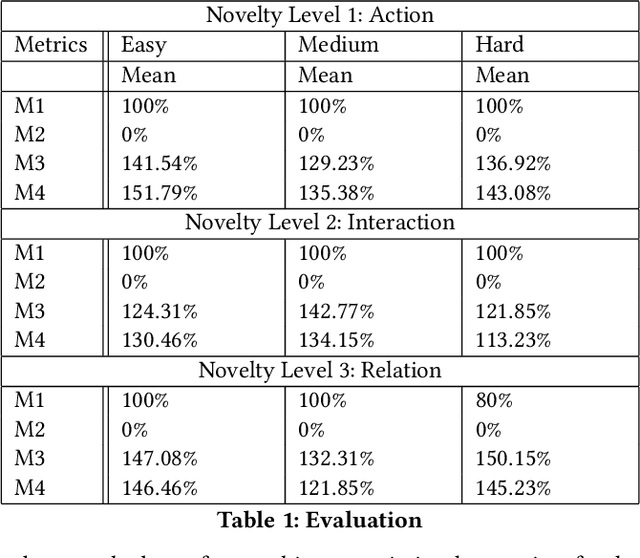
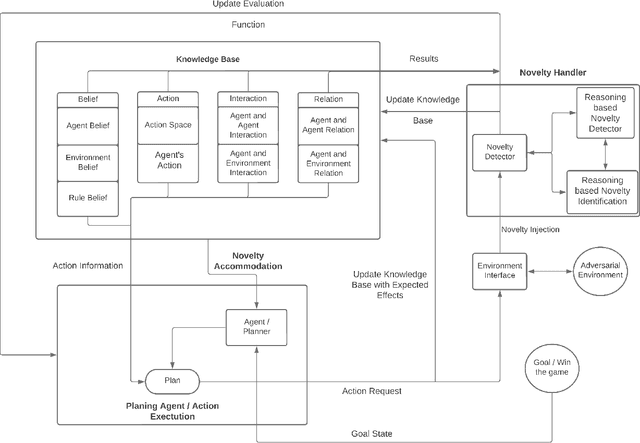
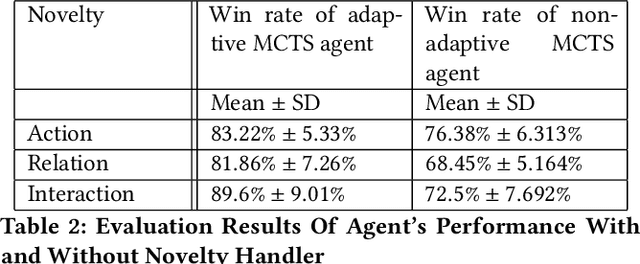
Learning to detect, characterize and accommodate novelties is a challenge that agents operating in open-world domains need to address to be able to guarantee satisfactory task performance. Certain novelties (e.g., changes in environment dynamics) can interfere with the performance or prevent agents from accomplishing task goals altogether. In this paper, we introduce general methods and architectural mechanisms for detecting and characterizing different types of novelties, and for building an appropriate adaptive model to accommodate them utilizing logical representations and reasoning methods. We demonstrate the effectiveness of the proposed methods in evaluations performed by a third party in the adversarial multi-agent board game Monopoly. The results show high novelty detection and accommodation rates across a variety of novelty types, including changes to the rules of the game, as well as changes to the agent's action capabilities.
Towards customizable reinforcement learning agents: Enabling preference specification through online vocabulary expansion
Oct 27, 2022There is a growing interest in developing automated agents that can work alongside humans. In addition to completing the assigned task, such an agent will undoubtedly be expected to behave in a manner that is preferred by the human. This requires the human to communicate their preferences to the agent. To achieve this, the current approaches either require the users to specify the reward function or the preference is interactively learned from queries that ask the user to compare trajectories. The former approach can be challenging if the internal representation used by the agent is inscrutable to the human while the latter is unnecessarily cumbersome for the user if their preference can be specified more easily in symbolic terms. In this work, we propose PRESCA (PREference Specification through Concept Acquisition), a system that allows users to specify their preferences in terms of concepts that they understand. PRESCA maintains a set of such concepts in a shared vocabulary. If the relevant concept is not in the shared vocabulary, then it is learned. To make learning a new concept more efficient, PRESCA leverages causal associations between the target concept and concepts that are already known. Additionally, the effort of learning the new concept is amortized by adding the concept to the shared vocabulary for supporting preference specification in future interactions. We evaluate PRESCA by using it on a Minecraft environment and show that it can be effectively used to make the agent align with the user's preference.
Integrating Planning, Execution and Monitoring in the presence of Open World Novelties: Case Study of an Open World Monopoly Solver
Aug 09, 2021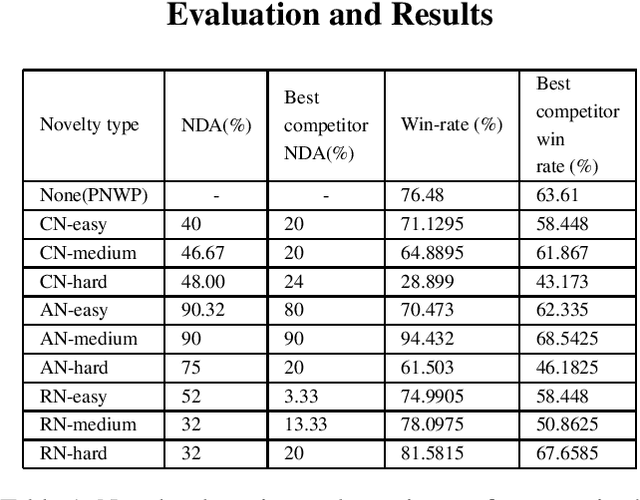
The game of monopoly is an adversarial multi-agent domain where there is no fixed goal other than to be the last player solvent, There are useful subgoals like monopolizing sets of properties, and developing them. There is also a lot of randomness from dice rolls, card-draws, and adversaries' strategies. This unpredictability is made worse when unknown novelties are added during gameplay. Given these challenges, Monopoly was one of the test beds chosen for the DARPA-SAILON program which aims to create agents that can detect and accommodate novelties. To handle the game complexities, we developed an agent that eschews complete plans, and adapts it's policy online as the game evolves. In the most recent independent evaluation in the SAILON program, our agent was the best performing agent on most measures. We herein present our approach and results.
Not all users are the same: Providing personalized explanations for sequential decision making problems
Jun 23, 2021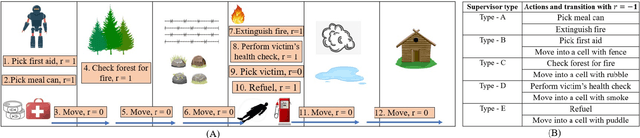
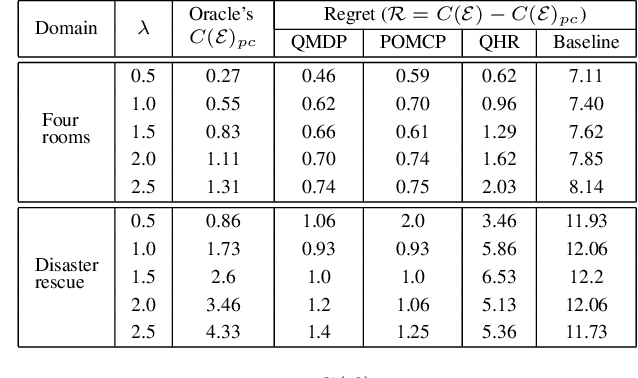
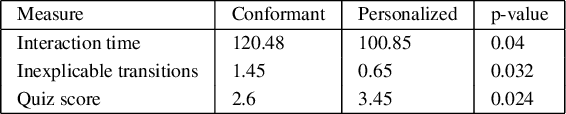
There is a growing interest in designing autonomous agents that can work alongside humans. Such agents will undoubtedly be expected to explain their behavior and decisions. While generating explanations is an actively researched topic, most works tend to focus on methods that generate explanations that are one size fits all. As in the specifics of the user-model are completely ignored. The handful of works that look at tailoring their explanation to the user's background rely on having specific models of the users (either analytic models or learned labeling models). The goal of this work is thus to propose an end-to-end adaptive explanation generation system that begins by learning the different types of users that the agent could interact with. Then during the interaction with the target user, it is tasked with identifying the type on the fly and adjust its explanations accordingly. The former is achieved by a data-driven clustering approach while for the latter, we compile our explanation generation problem into a POMDP. We demonstrate the usefulness of our system on two domains using state-of-the-art POMDP solvers. We also report the results of a user study that investigates the benefits of providing personalized explanations in a human-robot interaction setting.
Let Me At Least Learn What You Really Like: Dealing With Noisy Humans When Learning Preferences
Feb 15, 2020

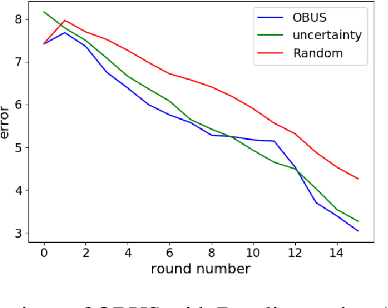

Learning the preferences of a human improves the quality of the interaction with the human. The number of queries available to learn preferences maybe limited especially when interacting with a human, and so active learning is a must. One approach to active learning is to use uncertainty sampling to decide the informativeness of a query. In this paper, we propose a modification to uncertainty sampling which uses the expected output value to help speed up learning of preferences. We compare our approach with the uncertainty sampling baseline, as well as conduct an ablation study to test the validity of each component of our approach.