 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based Pin Site Image Classification in Orthopaedic Patients with External Fixators
Mar 25, 2026Pin sites represent the interface where a metal pin or wire from the external environment passes through the skin into the internal environment of the limb. These pins or wires connect an external fixator to the bone to stabilize the bone segments in a patient with trauma or deformity. Because these pin sites represent an opportunity for external skin flora to enter the internal environment of the limb, infections of the pin site are common. These pin site infections are painful, annoying, and cause increased morbidity to the patients. Improving the identification and management of pin site infections would greatly enhance the patient experience when external fixators are used. For this, this paper collects and produces a dataset on pin sites wound infections and proposes a deep learning (DL) method to classify pin sites images based on their appearance: Group A displayed signs of inflammation or infection, while Group B showed no evident complications. Unlike studies that primarily focus on open wounds, our research includes potential interventions at the metal pin/skin interface. Our attention-based deep learning model addresses this complexity by emphasizing relevant regions and minimizing distractions from the pins. Moreover, we introduce an Efficient Redundant Reconstruction Convolution (ERRC) method to enhance the richness of feature maps while reducing the number of parameters. Our model outperforms baseline methods with an AUC of 0.975 and an F1-score of 0.927, requiring only 5.77 M parameters. These results highlight the potential of DL in differentiating pin sites only based on visual signs of infection, aligning with healthcare professional assessments, while further validation with more data remains essential.
A Contrastive Variational AutoEncoder for NSCLC Survival Prediction with Missing Modalities
Feb 19, 2026Predicting survival outcomes for non-small cell lung cancer (NSCLC) patients is challenging due to the different individual prognostic features. This task can benefit from the integration of whole-slide images, bulk transcriptomics, and DNA methylation, which offer complementary views of the patient's condition at diagnosis. However, real-world clinical datasets are often incomplete, with entire modalities missing for a significant fraction of patients. State-of-the-art models rely on available data to create patient-level representations or use generative models to infer missing modalities, but they lack robustness in cases of severe missingness. We propose a Multimodal Contrastive Variational AutoEncoder (MCVAE) to address this issue: modality-specific variational encoders capture the uncertainty in each data source, and a fusion bottleneck with learned gating mechanisms is introduced to normalize the contributions from present modalities. We propose a multi-task objective that combines survival loss and reconstruction loss to regularize patient representations, along with a cross-modal contrastive loss that enforces cross-modal alignment in the latent space. During training, we apply stochastic modality masking to improve the robustness to arbitrary missingness patterns. Extensive evaluations on the TCGA-LUAD (n=475) and TCGA-LUSC (n=446) datasets demonstrate the efficacy of our approach in predicting disease-specific survival (DSS) and its robustness to severe missingness scenarios compared to two state-of-the-art models. Finally, we bring some clarifications on multimodal integration by testing our model on all subsets of modalities, finding that integration is not always beneficial to the task.
Mismatch Analysis and Cooperative Calibration of Array Beam Patterns for ISAC Systems
Feb 01, 2026Integrated sensing and communication (ISAC) is a key technology for enabling a wide range of applications in future wireless systems. However, the sensing performance is often degraded by model mismatches caused by geometric errors (e.g., position and orientation) and hardware impairments (e.g., mutual coupling and amplifier non-linearity). This paper focuses on the angle estimation performance with antenna arrays and tackles the critical challenge of array beam pattern calibration for ISAC systems. To assess calibration quality from a sensing perspective, a novel performance metric that accounts for angle estimation error, rather than beam pattern similarity, is proposed and incorporated into a differentiable loss function. Additionally, a cooperative calibration framework is introduced, allowing multiple user equipments to iteratively optimize the beam pattern based on the proposed loss functions and local data, and collaboratively update global calibration parameters. The proposed models and algorithms are validated using real-world beam pattern measurements collected in an anechoic chamber. Experimental results show that the angle estimation error can be reduced from {$\textbf{1.01}^\circ$} to $\textbf{0.11}^\circ$ in 2D calibration scenarios, and from $\textbf{5.19}^\circ$ to $\textbf{0.86}^\circ$ in 3D calibration ones.
Co-Channel Interference Mitigation Using Deep Learning for Drone-Based Large-Scale Antenna Measurements
Jan 19, 2026Unmanned aerial vehicles (UAVs) enable efficient in-situ radiation characterization of large-aperture antennas directly in their deployment environments. In such measurements, a continuous-wave (CW) probe tone is commonly transmitted to characterize the antenna response. However, active co-channel emissions from neighboring antennas often introduce severe in-band interference, where classical FFT-based estimators fail to accurately estimate the CW tone amplitude when the signal-to-interference ratios (SIR) falls below -10 dB. This paper proposes a lightweight deep convolutional neural network (DC-CNN) that estimates the amplitude of the CW tone. The model is trained and evaluated on real 5~GHz measurement bursts spanning an effective SIR range of --33.3 dB to +46.7 dB. Despite its compact size (<20k parameters), the proposed DC-CNN achieves a mean absolute error (MAE) of 7% over the full range, with <1 dB error for SIR >= -30 dB. This robustness and efficiency make DC-CNN suitable for deployment on embedded UAV platforms for interference-resilient antenna pattern characterization.
CC-LEARN: Cohort-based Consistency Learning
Jun 18, 2025Large language models excel at many tasks but still struggle with consistent, robust reasoning. We introduce Cohort-based Consistency Learning (CC-Learn), a reinforcement learning framework that improves the reliability of LLM reasoning by training on cohorts of similar questions derived from shared programmatic abstractions. To enforce cohort-level consistency, we define a composite objective combining cohort accuracy, a retrieval bonus for effective problem decomposition, and a rejection penalty for trivial or invalid lookups that reinforcement learning can directly optimize, unlike supervised fine-tuning. Optimizing this reward guides the model to adopt uniform reasoning patterns across all cohort members. Experiments on challenging reasoning benchmarks (including ARC-Challenge and StrategyQA) show that CC-Learn boosts both accuracy and reasoning stability over pretrained and SFT baselines. These results demonstrate that cohort-level RL effectively enhances reasoning consistency in LLMs.
BOW: Bottlenecked Next Word Exploration
Jun 16, 2025Large language models (LLMs) are typically trained via next-word prediction (NWP), which provides strong surface-level fluency but often lacks support for robust reasoning. We propose BOttlenecked next Word exploration (BOW), a novel RL framework that rethinks NWP by introducing a reasoning bottleneck where a policy model first generates a reasoning path rather than predicting the next token directly, after which a frozen judge model predicts the next token distribution based solely on this reasoning path. We train the policy model using GRPO with rewards that quantify how effectively the reasoning path facilitates next-word recovery. Compared with other continual pretraining baselines, we show that BOW improves both the general and next-word reasoning capabilities of the base model, evaluated on various benchmarks. Our findings show that BOW can serve as an effective and scalable alternative to vanilla NWP.
QA-LIGN: Aligning LLMs through Constitutionally Decomposed QA
Jun 09, 2025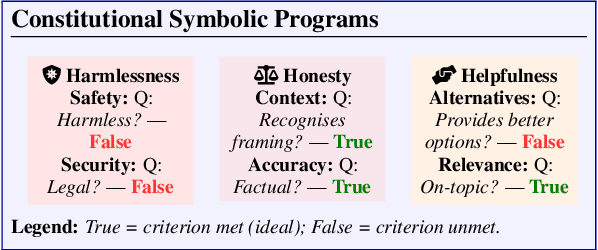
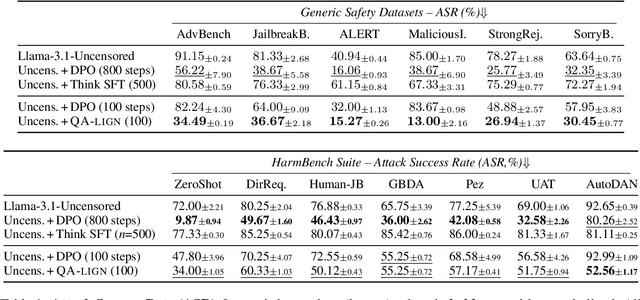
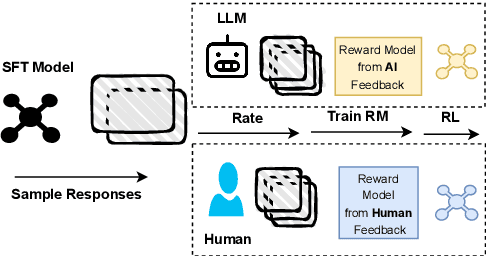

Alignment of large language models with explicit principles (such as helpfulness, honesty, and harmlessness) is crucial for ensuring safe and reliable AI systems. However, standard reward-based alignment methods typically collapse diverse feedback into a single scalar reward, entangling multiple objectives into one opaque training signal, which hinders interpretability. In this work, we introduce QA-LIGN, an automatic symbolic reward decomposition approach that preserves the structure of each constitutional principle within the reward mechanism. Instead of training a black-box reward model that outputs a monolithic score, QA-LIGN formulates principle-specific evaluation questions and derives separate reward components for each principle, making it a drop-in reward model replacement. Experiments aligning an uncensored large language model with a set of constitutional principles demonstrate that QA-LIGN offers greater transparency and adaptability in the alignment process. At the same time, our approach achieves performance on par with or better than a DPO baseline. Overall, these results represent a step toward more interpretable and controllable alignment of language models, achieved without sacrificing end-task performance.
Optimizing LLM-Based Multi-Agent System with Textual Feedback: A Case Study on Software Development
May 22, 2025We have seen remarkable progress in large language models (LLMs) empowered multi-agent systems solving complex tasks necessitating cooperation among experts with diverse skills. However, optimizing LLM-based multi-agent systems remains challenging. In this work, we perform an empirical case study on group optimization of role-based multi-agent systems utilizing natural language feedback for challenging software development tasks under various evaluation dimensions. We propose a two-step agent prompts optimization pipeline: identifying underperforming agents with their failure explanations utilizing textual feedback and then optimizing system prompts of identified agents utilizing failure explanations. We then study the impact of various optimization settings on system performance with two comparison groups: online against offline optimization and individual against group optimization. For group optimization, we study two prompting strategies: one-pass and multi-pass prompting optimizations. Overall, we demonstrate the effectiveness of our optimization method for role-based multi-agent systems tackling software development tasks evaluated on diverse evaluation dimensions, and we investigate the impact of diverse optimization settings on group behaviors of the multi-agent systems to provide practical insights for future development.
RIS Beam Calibration for ISAC Systems: Modeling and Performance Analysis
May 21, 2025High-accuracy localization is a key enabler for integrated sensing and communication (ISAC), playing an essential role in various applications such as autonomous driving. Antenna arrays and reconfigurable intelligent surface (RIS) are incorporated into these systems to achieve high angular resolution, assisting in the localization process. However, array and RIS beam patterns in practice often deviate from the idealized models used for algorithm design, leading to significant degradation in positioning accuracy. This mismatch highlights the need for beam calibration to bridge the gap between theoretical models and real-world hardware behavior. In this paper, we present and analyze three beam models considering several key non-idealities such as mutual coupling, non-ideal codebook, and measurement uncertainties. Based on the models, we then develop calibration algorithms to estimate the model parameters that can be used for future localization tasks. This work evaluates the effectiveness of the beam models and the calibration algorithms using both theoretical bounds and real-world beam pattern data from an RIS prototype. The simulation results show that the model incorporating combined impacts can accurately reconstruct measured beam patterns. This highlights the necessity of realistic beam modeling and calibration to achieve high-accuracy localization.
AI-Assisted NLOS Sensing for RIS-Based Indoor Localization in Smart Factories
May 21, 2025In the era of Industry 4.0, precise indoor localization is vital for automation and efficiency in smart factories. Reconfigurable Intelligent Surfaces (RIS) are emerging as key enablers in 6G networks for joint sensing and communication. However, RIS faces significant challenges in Non-Line-of-Sight (NLOS) and multipath propagation, particularly in localization scenarios, where detecting NLOS conditions is crucial for ensuring not only reliable results and increased connectivity but also the safety of smart factory personnel. This study introduces an AI-assisted framework employing a Convolutional Neural Network (CNN) customized for accurate Line-of-Sight (LOS) and Non-Line-of-Sight (NLOS) classification to enhance RIS-based localization using measured, synthetic, mixed-measured, and mixed-synthetic experimental data, that is, original, augmented, slightly noisy, and highly noisy data, respectively. Validated through such data from three different environments, the proposed customized-CNN (cCNN) model achieves {95.0\%-99.0\%} accuracy, outperforming standard pre-trained models like Visual Geometry Group 16 (VGG-16) with an accuracy of {85.5\%-88.0\%}. By addressing RIS limitations in NLOS scenarios, this framework offers scalable and high-precision localization solutions for 6G-enabled smart factories.