 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit Trait Inference for Multi-Agent Coordination
Apr 22, 2026LLM-based multi-agent systems (MAS) show promise on complex tasks but remain prone to coordination failures such as goal drift, error cascades, and misaligned behaviors. We propose Explicit Trait Inference (ETI), a psychologically grounded method for improving coordination. ETI enables agents to infer and track partner characteristics along two established psychological dimensions--warmth (e.g., trust) and competence (e.g., skill)--from interaction histories to guide decisions. We evaluate ETI in controlled settings (economic games), where it reduces payoff loss by 45-77%, and in more realistic, complex multi-agent settings (MultiAgentBench), where it improves performance by 3-29% depending on the scenario and model, relative to a CoT baseline. Additional analysis shows that gains are closely linked to trait inference: ETI profiles predict agents' actions, and informative profiles drive improvements. These results highlight ETI as a lightweight and robust mechanism for improving coordination in diverse multi-agent settings, and provide the first systematic evidence that LLM agents can (i) reliably infer others' traits from interaction histories and (ii) leverage structured awareness of others' traits for coordination.
Supplement Generation Training for Enhancing Agentic Task Performance
Apr 22, 2026Training large foundation models for agentic tasks is increasingly impractical due to the high computational costs, long iteration cycles, and rapid obsolescence as new models are continuously released. Instead of post-training massive models for every new task or domain, we propose Supplement Generation Training (SGT), a more efficient and sustainable strategy. SGT trains a smaller LLM to generate useful supplemental text that, when appended to the original input, helps the larger LLM solve the task more effectively. These lightweight models can dynamically adapt supplements to task requirements, improving performance without modifying the underlying large models. This approach decouples task-specific optimization from large foundation models and enables more flexible, cost-effective deployment of LLM-powered agents in real-world applications.
Optimizing LLM-Based Multi-Agent System with Textual Feedback: A Case Study on Software Development
May 22, 2025We have seen remarkable progress in large language models (LLMs) empowered multi-agent systems solving complex tasks necessitating cooperation among experts with diverse skills. However, optimizing LLM-based multi-agent systems remains challenging. In this work, we perform an empirical case study on group optimization of role-based multi-agent systems utilizing natural language feedback for challenging software development tasks under various evaluation dimensions. We propose a two-step agent prompts optimization pipeline: identifying underperforming agents with their failure explanations utilizing textual feedback and then optimizing system prompts of identified agents utilizing failure explanations. We then study the impact of various optimization settings on system performance with two comparison groups: online against offline optimization and individual against group optimization. For group optimization, we study two prompting strategies: one-pass and multi-pass prompting optimizations. Overall, we demonstrate the effectiveness of our optimization method for role-based multi-agent systems tackling software development tasks evaluated on diverse evaluation dimensions, and we investigate the impact of diverse optimization settings on group behaviors of the multi-agent systems to provide practical insights for future development.
MemInsight: Autonomous Memory Augmentation for LLM Agents
Mar 27, 2025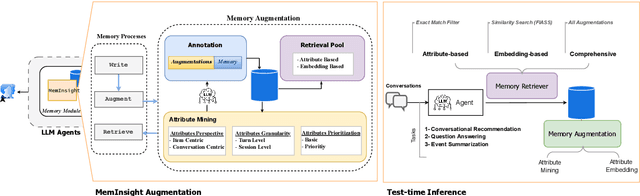
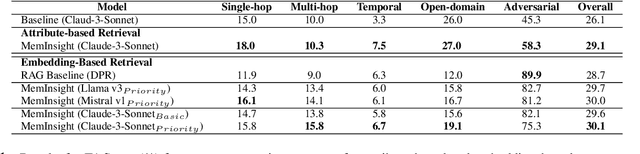
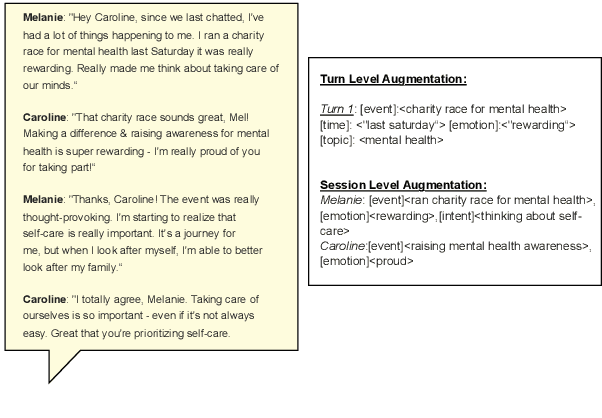

Large language model (LLM) agents have evolved to intelligently process information, make decisions, and interact with users or tools. A key capability is the integration of long-term memory capabilities, enabling these agents to draw upon historical interactions and knowledge. However, the growing memory size and need for semantic structuring pose significant challenges. In this work, we propose an autonomous memory augmentation approach, MemInsight, to enhance semantic data representation and retrieval mechanisms. By leveraging autonomous augmentation to historical interactions, LLM agents are shown to deliver more accurate and contextualized responses. We empirically validate the efficacy of our proposed approach in three task scenarios; conversational recommendation, question answering and event summarization. On the LLM-REDIAL dataset, MemInsight boosts persuasiveness of recommendations by up to 14%. Moreover, it outperforms a RAG baseline by 34% in recall for LoCoMo retrieval. Our empirical results show the potential of MemInsight to enhance the contextual performance of LLM agents across multiple tasks.
A Study on Leveraging Search and Self-Feedback for Agent Reasoning
Feb 17, 2025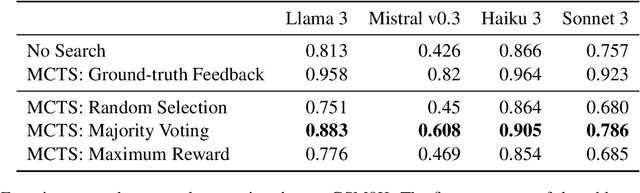
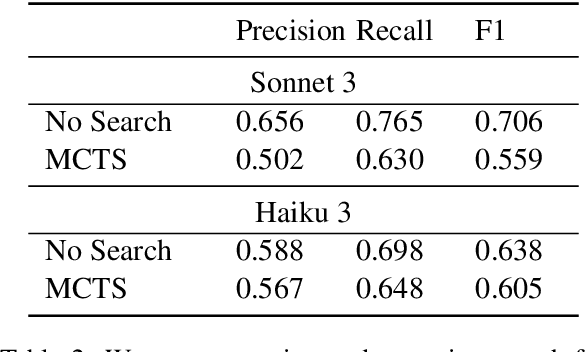

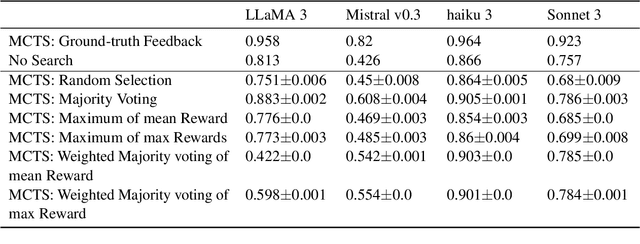
Recent works have demonstrated that incorporating search during inference can significantly improve reasoning capabilities of language agents. Some approaches may make use of the ground truth or rely on model's own generated feedback. The search algorithm uses this feedback to then produce values that will update its criterion for exploring and exploiting various reasoning paths. In this study, we investigate how search and model's self-feedback can be leveraged for reasoning tasks. First, we explore differences in ground-truth feedback and self-feedback during search for math reasoning. Second, we observe limitations in applying search techniques to more complex tasks like tool-calling and design domain-specific approaches to address these gaps. Our experiments reveal challenges related to generalization when solely relying on self-feedback during search. For search to work effectively, either access to the ground-truth is needed or feedback mechanisms need to be carefully designed for the specific task.
TReMu: Towards Neuro-Symbolic Temporal Reasoning for LLM-Agents with Memory in Multi-Session Dialogues
Feb 03, 2025

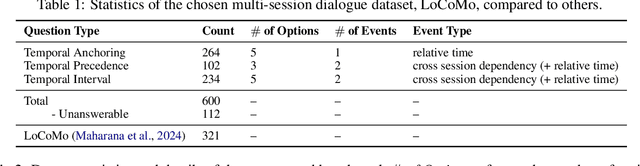
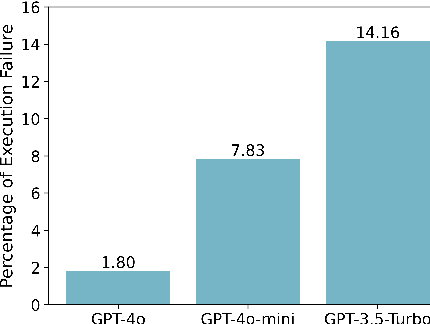
Temporal reasoning in multi-session dialogues presents a significant challenge which has been under-studied in previous temporal reasoning benchmarks. To bridge this gap, we propose a new evaluation task for temporal reasoning in multi-session dialogues and introduce an approach to construct a new benchmark by augmenting dialogues from LoCoMo and creating multi-choice QAs. Furthermore, we present TReMu, a new framework aimed at enhancing the temporal reasoning capabilities of LLM-agents in this context. Specifically, the framework employs \textit{time-aware memorization} through timeline summarization, generating retrievable memory by summarizing events in each dialogue session with their inferred dates. Additionally, we integrate \textit{neuro-symbolic temporal reasoning}, where LLMs generate Python code to perform temporal calculations and select answers. Experimental evaluations on popular LLMs demonstrate that our benchmark is challenging, and the proposed framework significantly improves temporal reasoning performance compared to baseline methods, raising from 29.83 on GPT-4o via standard prompting to 77.67 via our approach and highlighting its effectiveness in addressing temporal reasoning in multi-session dialogues.
Towards Effective GenAI Multi-Agent Collaboration: Design and Evaluation for Enterprise Applications
Dec 06, 2024AI agents powered by large language models (LLMs) have shown strong capabilities in problem solving. Through combining many intelligent agents, multi-agent collaboration has emerged as a promising approach to tackle complex, multi-faceted problems that exceed the capabilities of single AI agents. However, designing the collaboration protocols and evaluating the effectiveness of these systems remains a significant challenge, especially for enterprise applications. This report addresses these challenges by presenting a comprehensive evaluation of coordination and routing capabilities in a novel multi-agent collaboration framework. We evaluate two key operational modes: (1) a coordination mode enabling complex task completion through parallel communication and payload referencing, and (2) a routing mode for efficient message forwarding between agents. We benchmark on a set of handcrafted scenarios from three enterprise domains, which are publicly released with the report. For coordination capabilities, we demonstrate the effectiveness of inter-agent communication and payload referencing mechanisms, achieving end-to-end goal success rates of 90%. Our analysis yields several key findings: multi-agent collaboration enhances goal success rates by up to 70% compared to single-agent approaches in our benchmarks; payload referencing improves performance on code-intensive tasks by 23%; latency can be substantially reduced with a routing mechanism that selectively bypasses agent orchestration. These findings offer valuable guidance for enterprise deployments of multi-agent systems and advance the development of scalable, efficient multi-agent collaboration frameworks.
RoundTable: Investigating Group Decision-Making Mechanism in Multi-Agent Collaboration
Nov 11, 2024This study investigates the efficacy of Multi-Agent Systems in eliciting cross-agent communication and enhancing collective intelligence through group decision-making in a decentralized setting. Unlike centralized mechanisms, where a fixed hierarchy governs social choice, decentralized group decision-making allows agents to engage in joint deliberation. Our research focuses on the dynamics of communication and decision-making within various social choice methods. By applying different voting rules in various environments, we find that moderate decision flexibility yields better outcomes. Additionally, exploring the linguistic features of agent-to-agent conversations reveals indicators of effective collaboration, offering insights into communication patterns that facilitate or hinder collaboration. Finally, we propose various methods for determining the optimal stopping point in multi-agent collaborations based on linguistic cues. Our findings contribute to a deeper understanding of how decentralized decision-making and group conversation shape multi-agent collaboration, with implications for the design of more effective MAS environments.
Inference time LLM alignment in single and multidomain preference spectrum
Oct 24, 2024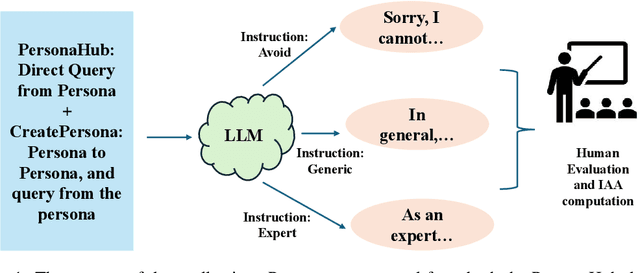
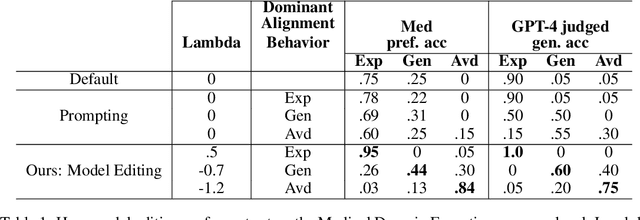
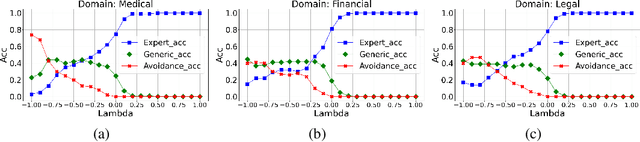
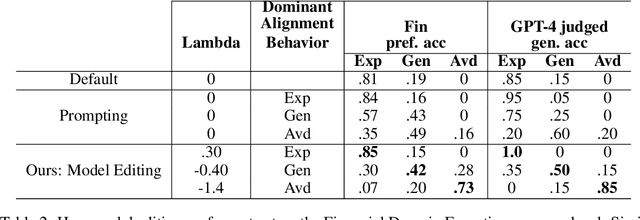
Aligning Large Language Models (LLM) to address subjectivity and nuanced preference levels requires adequate flexibility and control, which can be a resource-intensive and time-consuming procedure. Existing training-time alignment methods require full re-training when a change is needed and inference-time ones typically require access to the reward model at each inference step. To address these limitations, we introduce inference-time model alignment method that learns encoded representations of preference dimensions, called \textit{Alignment Vectors} (AV). These representations are computed by subtraction of the base model from the aligned model as in model editing enabling dynamically adjusting the model behavior during inference through simple linear operations. Even though the preference dimensions can span various granularity levels, here we focus on three gradual response levels across three specialized domains: medical, legal, and financial, exemplifying its practical potential. This new alignment paradigm introduces adjustable preference knobs during inference, allowing users to tailor their LLM outputs while reducing the inference cost by half compared to the prompt engineering approach. Additionally, we find that AVs are transferable across different fine-tuning stages of the same model, demonstrating their flexibility. AVs also facilitate multidomain, diverse preference alignment, making the process 12x faster than the retraining approach.
CERET: Cost-Effective Extrinsic Refinement for Text Generation
Jun 08, 2024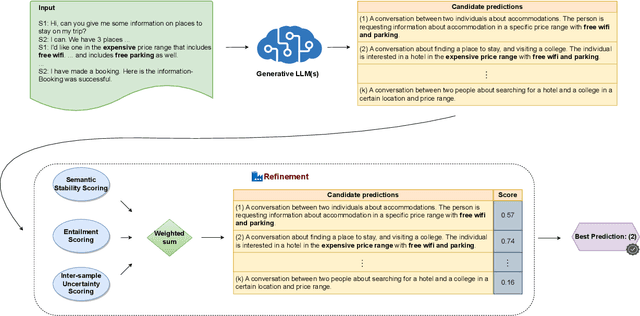

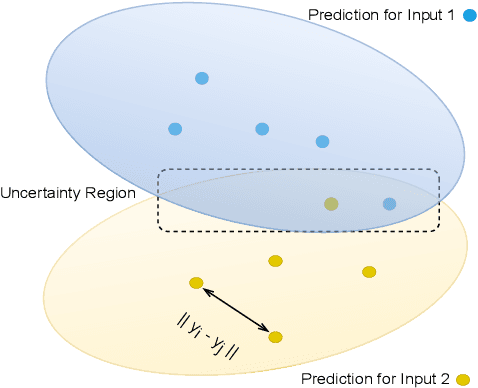
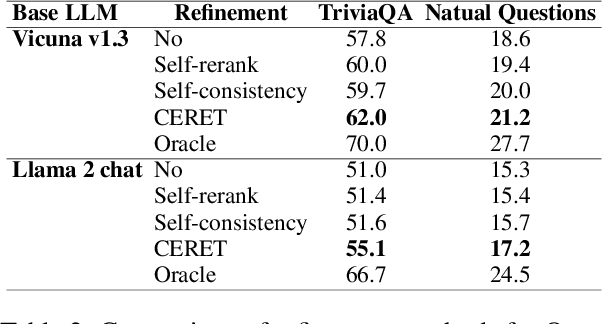
Large Language Models (LLMs) are powerful models for generation tasks, but they may not generate good quality outputs in their first attempt. Apart from model fine-tuning, existing approaches to improve prediction accuracy and quality typically involve LLM self-improvement / self-reflection that incorporate feedback from models themselves. Despite their effectiveness, these methods are hindered by their high computational cost and lack of scalability. In this work, we propose CERET, a method for refining text generations by considering semantic stability, entailment and inter-sample uncertainty measures. Experimental results show that CERET outperforms Self-consistency and Self-rerank baselines consistently under various task setups, by ~1.6% in Rouge-1 for abstractive summarization and ~3.5% in hit rate for question answering. Compared to LLM Self-rerank method, our approach only requires 9.4% of its latency and is more cost-effective.