 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on Leveraging Search and Self-Feedback for Agent Reasoning
Paper and Code
Feb 17, 2025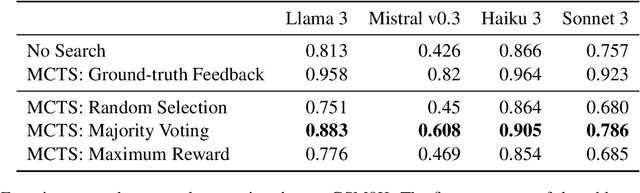
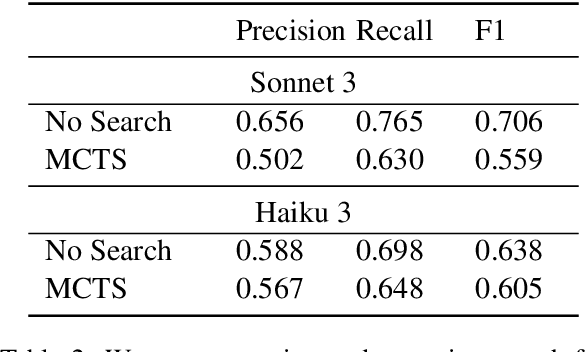

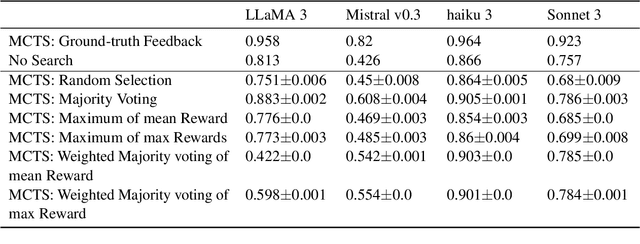
Recent works have demonstrated that incorporating search during inference can significantly improve reasoning capabilities of language agents. Some approaches may make use of the ground truth or rely on model's own generated feedback. The search algorithm uses this feedback to then produce values that will update its criterion for exploring and exploiting various reasoning paths. In this study, we investigate how search and model's self-feedback can be leveraged for reasoning tasks. First, we explore differences in ground-truth feedback and self-feedback during search for math reasoning. Second, we observe limitations in applying search techniques to more complex tasks like tool-calling and design domain-specific approaches to address these gaps. Our experiments reveal challenges related to generalization when solely relying on self-feedback during search. For search to work effectively, either access to the ground-truth is needed or feedback mechanisms need to be carefully designed for the specific task.