 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMT-OSC: Path for LLMs that Get Lost in Multi-Turn Conversation
Apr 09, 2026Large language models (LLMs) suffer significant performance degradation when user instructions and context are distributed over multiple conversational turns, yet multi-turn (MT) interactions dominate chat interfaces. The routine approach of appending full chat history to prompts rapidly exhausts context windows, leading to increased latency, higher computational costs, and diminishing returns as conversations extend. We introduce MT-OSC, a One-off Sequential Condensation framework that efficiently and automatically condenses chat history in the background without disrupting the user experience. MT-OSC employs a Condenser Agent that uses a few-shot inference-based Condenser and a lightweight Decider to selectively retain essential information, reducing token counts by up to 72% in 10-turn dialogues. Evaluated across 13 state-of-the-art LLMs and diverse multi-turn benchmarks, MT-OSC consistently narrows the multi-turn performance gap - yielding improved or preserved accuracy across datasets while remaining robust to distractors and irrelevant turns. Our results establish MT-OSC as a scalable solution for multi-turn chats, enabling richer context within constrained input spaces, reducing latency and operational cost, while balancing performance.
MemInsight: Autonomous Memory Augmentation for LLM Agents
Mar 27, 2025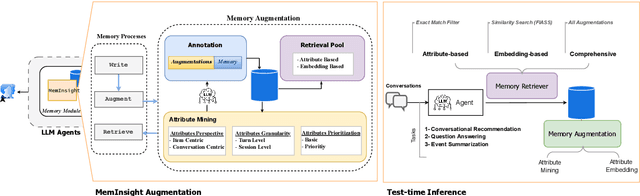
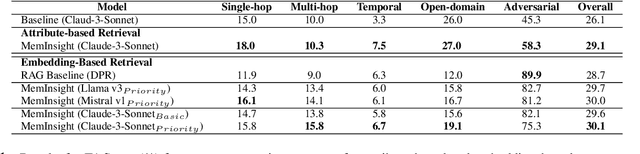
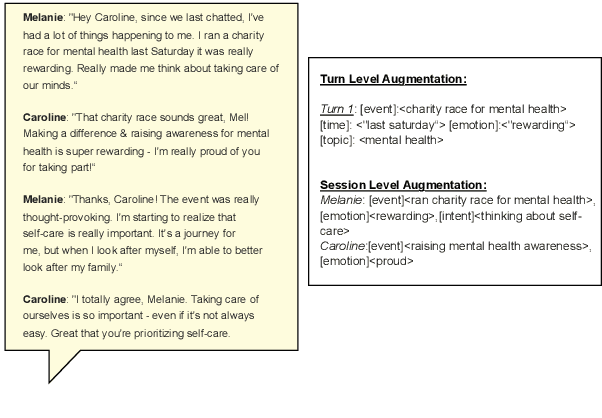

Large language model (LLM) agents have evolved to intelligently process information, make decisions, and interact with users or tools. A key capability is the integration of long-term memory capabilities, enabling these agents to draw upon historical interactions and knowledge. However, the growing memory size and need for semantic structuring pose significant challenges. In this work, we propose an autonomous memory augmentation approach, MemInsight, to enhance semantic data representation and retrieval mechanisms. By leveraging autonomous augmentation to historical interactions, LLM agents are shown to deliver more accurate and contextualized responses. We empirically validate the efficacy of our proposed approach in three task scenarios; conversational recommendation, question answering and event summarization. On the LLM-REDIAL dataset, MemInsight boosts persuasiveness of recommendations by up to 14%. Moreover, it outperforms a RAG baseline by 34% in recall for LoCoMo retrieval. Our empirical results show the potential of MemInsight to enhance the contextual performance of LLM agents across multiple tasks.
A Study on Leveraging Search and Self-Feedback for Agent Reasoning
Feb 17, 2025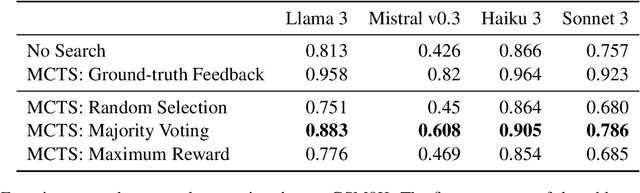
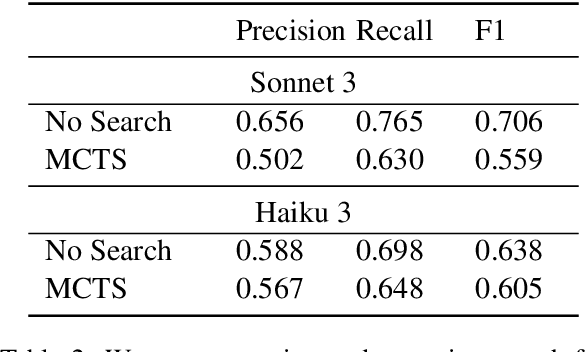

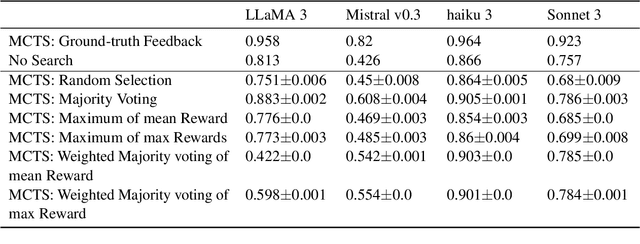
Recent works have demonstrated that incorporating search during inference can significantly improve reasoning capabilities of language agents. Some approaches may make use of the ground truth or rely on model's own generated feedback. The search algorithm uses this feedback to then produce values that will update its criterion for exploring and exploiting various reasoning paths. In this study, we investigate how search and model's self-feedback can be leveraged for reasoning tasks. First, we explore differences in ground-truth feedback and self-feedback during search for math reasoning. Second, we observe limitations in applying search techniques to more complex tasks like tool-calling and design domain-specific approaches to address these gaps. Our experiments reveal challenges related to generalization when solely relying on self-feedback during search. For search to work effectively, either access to the ground-truth is needed or feedback mechanisms need to be carefully designed for the specific task.
Towards Effective GenAI Multi-Agent Collaboration: Design and Evaluation for Enterprise Applications
Dec 06, 2024AI agents powered by large language models (LLMs) have shown strong capabilities in problem solving. Through combining many intelligent agents, multi-agent collaboration has emerged as a promising approach to tackle complex, multi-faceted problems that exceed the capabilities of single AI agents. However, designing the collaboration protocols and evaluating the effectiveness of these systems remains a significant challenge, especially for enterprise applications. This report addresses these challenges by presenting a comprehensive evaluation of coordination and routing capabilities in a novel multi-agent collaboration framework. We evaluate two key operational modes: (1) a coordination mode enabling complex task completion through parallel communication and payload referencing, and (2) a routing mode for efficient message forwarding between agents. We benchmark on a set of handcrafted scenarios from three enterprise domains, which are publicly released with the report. For coordination capabilities, we demonstrate the effectiveness of inter-agent communication and payload referencing mechanisms, achieving end-to-end goal success rates of 90%. Our analysis yields several key findings: multi-agent collaboration enhances goal success rates by up to 70% compared to single-agent approaches in our benchmarks; payload referencing improves performance on code-intensive tasks by 23%; latency can be substantially reduced with a routing mechanism that selectively bypasses agent orchestration. These findings offer valuable guidance for enterprise deployments of multi-agent systems and advance the development of scalable, efficient multi-agent collaboration frameworks.
MegaWika: Millions of reports and their sources across 50 diverse languages
Jul 13, 2023To foster the development of new models for collaborative AI-assisted report generation, we introduce MegaWika, consisting of 13 million Wikipedia articles in 50 diverse languages, along with their 71 million referenced source materials. We process this dataset for a myriad of applications, going beyond the initial Wikipedia citation extraction and web scraping of content, including translating non-English articles for cross-lingual applications and providing FrameNet parses for automated semantic analysis. MegaWika is the largest resource for sentence-level report generation and the only report generation dataset that is multilingual. We manually analyze the quality of this resource through a semantically stratified sample. Finally, we provide baseline results and trained models for crucial steps in automated report generation: cross-lingual question answering and citation retrieval.
InteractiveIE: Towards Assessing the Strength of Human-AI Collaboration in Improving the Performance of Information Extraction
May 24, 2023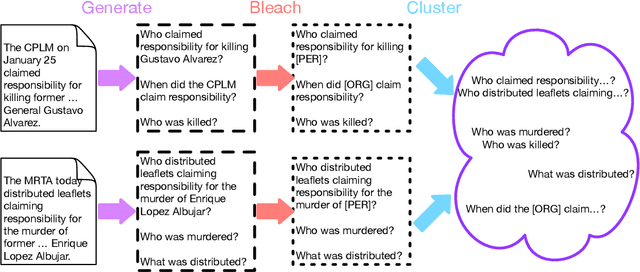



Learning template based information extraction from documents is a crucial yet difficult task. Prior template-based IE approaches assume foreknowledge of the domain templates; however, real-world IE do not have pre-defined schemas and it is a figure-out-as you go phenomena. To quickly bootstrap templates in a real-world setting, we need to induce template slots from documents with zero or minimal supervision. Since the purpose of question answering intersect with the goal of information extraction, we use automatic question generation to induce template slots from the documents and investigate how a tiny amount of a proxy human-supervision on-the-fly (termed as InteractiveIE) can further boost the performance. Extensive experiments on biomedical and legal documents, where obtaining training data is expensive, reveal encouraging trends of performance improvement using InteractiveIE over AI-only baseline.
Adaptive Active Learning for Coreference Resolution
Apr 15, 2021

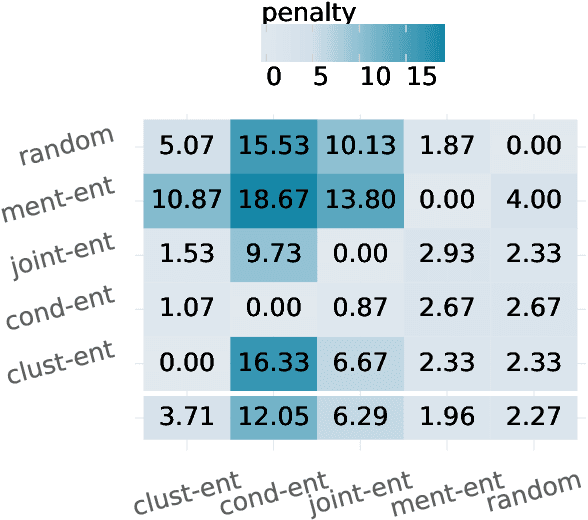
Training coreference resolution models require comprehensively labeled data. A model trained on one dataset may not successfully transfer to new domains. This paper investigates an approach to active learning for coreference resolution that feeds discrete annotations to an incremental clustering model. The recent developments in incremental coreference resolution allow for a novel approach to active learning in this setting. Through this new framework, we analyze important factors in data acquisition, like sources of model uncertainty and balancing reading and labeling costs. We explore different settings through simulated labeling with gold data. By lowering the data barrier for coreference, coreference resolvers can rapidly adapt to a series of previously unconsidered domains.
Cold-start Active Learning through Self-supervised Language Modeling
Oct 22, 2020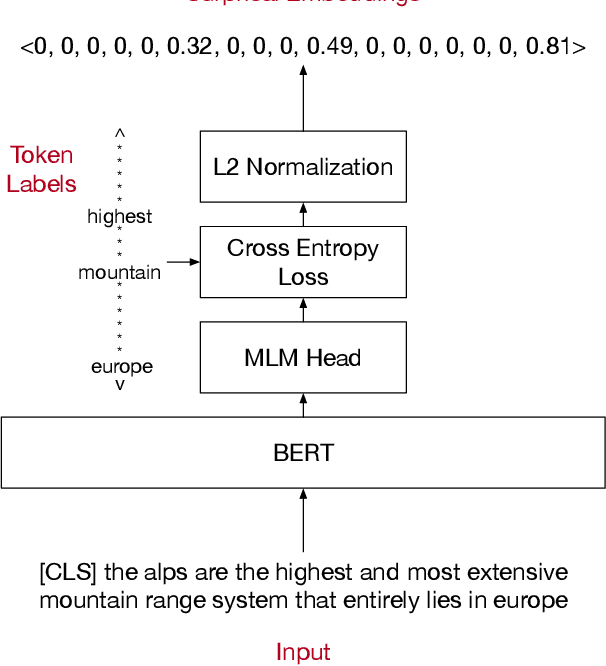
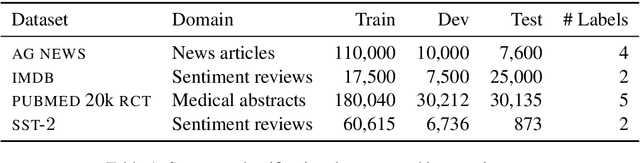
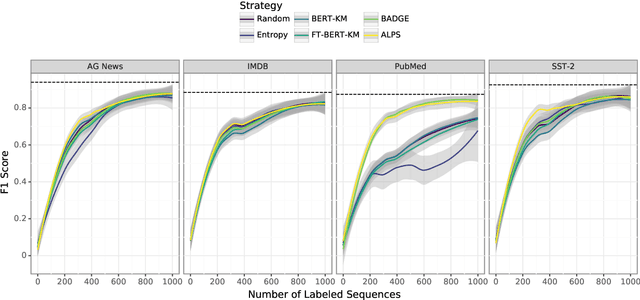

Active learning strives to reduce annotation costs by choosing the most critical examples to label. Typically, the active learning strategy is contingent on the classification model. For instance, uncertainty sampling depends on poorly calibrated model confidence scores. In the cold-start setting, active learning is impractical because of model instability and data scarcity. Fortunately, modern NLP provides an additional source of information: pre-trained language models. The pre-training loss can find examples that surprise the model and should be labeled for efficient fine-tuning. Therefore, we treat the language modeling loss as a proxy for classification uncertainty. With BERT, we develop a simple strategy based on the masked language modeling loss that minimizes labeling costs for text classification. Compared to other baselines, our approach reaches higher accuracy within less sampling iterations and computation time.
Interactive Refinement of Cross-Lingual Word Embeddings
Nov 08, 2019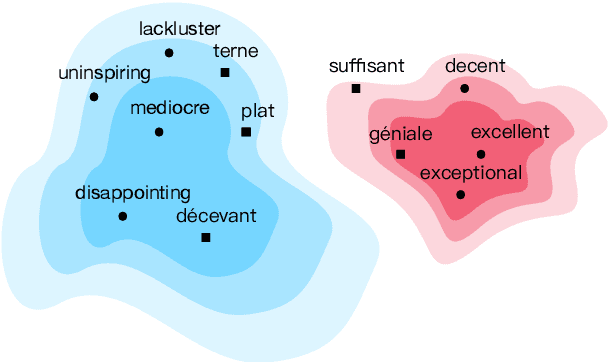



Cross-lingual word embeddings transfer knowledge between languages: models trained for a high-resource language can be used in a low-resource language. These embeddings are usually trained on general-purpose corpora but used for a domain-specific task. We introduce CLIME, an interactive system that allows a user to quickly adapt cross-lingual word embeddings for a given classification problem. First, words in the vocabulary are ranked by their salience to the downstream task. Then, salient keywords are displayed on an interface. Users mark the similarity between each keyword and its nearest neighbors in the embedding space. Finally, CLIME updates the embeddings using the annotations. We experiment clime on a cross-lingual text classification benchmark for four low-resource languages: Ilocano, Sinhalese, Tigrinya, and Uyghur. Embeddings refined by CLIME capture more nuanced word semantics and have higher test accuracy than the original embeddings. CLIME also improves test accuracy faster than an active learning baseline, and a simple combination of CLIME with active learning has the highest test accuracy.