 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping Sign Language Annotations with Sign Language Models
Apr 08, 2026AI-driven sign language interpretation is limited by a lack of high-quality annotated data. New datasets including ASL STEM Wiki and FLEURS-ASL contain professional interpreters and 100s of hours of data but remain only partially annotated and thus underutilized, in part due to the prohibitive costs of annotating at this scale. In this work, we develop a pseudo-annotation pipeline that takes signed video and English as input and outputs a ranked set of likely annotations, including time intervals, for glosses, fingerspelled words, and sign classifiers. Our pipeline uses sparse predictions from our fingerspelling recognizer and isolated sign recognizer (ISR), along with a K-Shot LLM approach, to estimate these annotations. In service of this pipeline, we establish simple yet effective baseline fingerspelling and ISR models, achieving state-of-the-art on FSBoard (6.7% CER) and on ASL Citizen datasets (74% top-1 accuracy). To validate and provide a gold-standard benchmark, a professional interpreter annotated nearly 500 videos from ASL STEM Wiki with sequence-level gloss labels containing glosses, classifiers, and fingerspelling signs. These human annotations and over 300 hours of pseudo-annotations are being released in supplemental material.
Hierarchical Instance Tracking to Balance Privacy Preservation with Accessible Information
Dec 10, 2025

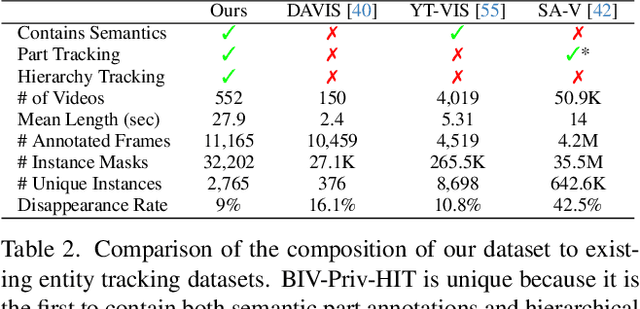
We propose a novel task, hierarchical instance tracking, which entails tracking all instances of predefined categories of objects and parts, while maintaining their hierarchical relationships. We introduce the first benchmark dataset supporting this task, consisting of 2,765 unique entities that are tracked in 552 videos and belong to 40 categories (across objects and parts). Evaluation of seven variants of four models tailored to our novel task reveals the new dataset is challenging. Our dataset is available at https://vizwiz.org/tasks-and-datasets/hierarchical-instance-tracking/
Prompting Whisper for Improved Verbatim Transcription and End-to-end Miscue Detection
May 29, 2025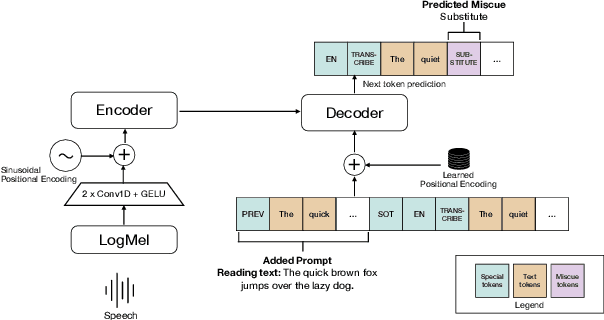



Identifying mistakes (i.e., miscues) made while reading aloud is commonly approached post-hoc by comparing automatic speech recognition (ASR) transcriptions to the target reading text. However, post-hoc methods perform poorly when ASR inaccurately transcribes verbatim speech. To improve on current methods for reading error annotation, we propose a novel end-to-end architecture that incorporates the target reading text via prompting and is trained for both improved verbatim transcription and direct miscue detection. Our contributions include: first, demonstrating that incorporating reading text through prompting benefits verbatim transcription performance over fine-tuning, and second, showing that it is feasible to augment speech recognition tasks for end-to-end miscue detection. We conducted two case studies -- children's read-aloud and adult atypical speech -- and found that our proposed strategies improve verbatim transcription and miscue detection compared to current state-of-the-art.
BIV-Priv-Seg: Locating Private Content in Images Taken by People With Visual Impairments
Jul 25, 2024
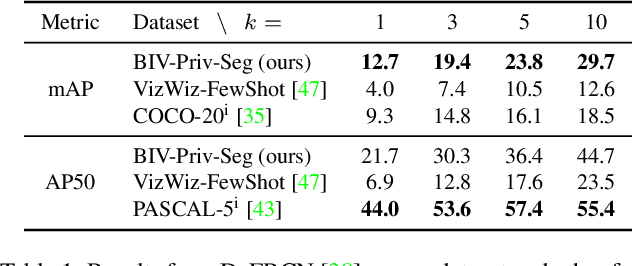


Individuals who are blind or have low vision (BLV) are at a heightened risk of sharing private information if they share photographs they have taken. To facilitate developing technologies that can help preserve privacy, we introduce BIV-Priv-Seg, the first localization dataset originating from people with visual impairments that shows private content. It contains 1,028 images with segmentation annotations for 16 private object categories. We first characterize BIV-Priv-Seg and then evaluate modern models' performance for locating private content in the dataset. We find modern models struggle most with locating private objects that are not salient, small, and lack text as well as recognizing when private content is absent from an image. We facilitate future extensions by sharing our new dataset with the evaluation server at https://vizwiz.org/tasks-and-datasets/object-localization.
Latent Phrase Matching for Dysarthric Speech
Jun 08, 2023



Many consumer speech recognition systems are not tuned for people with speech disabilities, resulting in poor recognition and user experience, especially for severe speech differences. Recent studies have emphasized interest in personalized speech models from people with atypical speech patterns. We propose a query-by-example-based personalized phrase recognition system that is trained using small amounts of speech, is language agnostic, does not assume a traditional pronunciation lexicon, and generalizes well across speech difference severities. On an internal dataset collected from 32 people with dysarthria, this approach works regardless of severity and shows a 60% improvement in recall relative to a commercial speech recognition system. On the public EasyCall dataset of dysarthric speech, our approach improves accuracy by 30.5%. Performance degrades as the number of phrases increases, but consistently outperforms ASR systems when trained with 50 unique phrases.
ProtoSound: A Personalized and Scalable Sound Recognition System for Deaf and Hard-of-Hearing Users
Feb 22, 2022

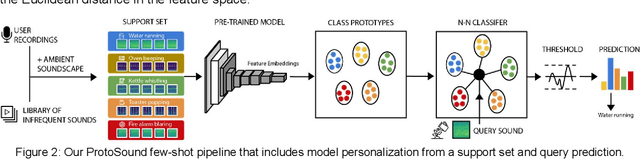
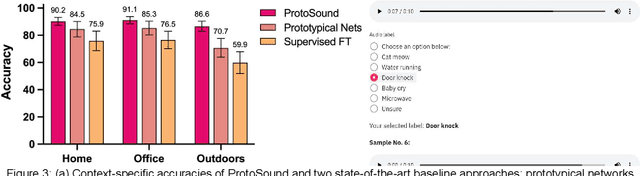
Recent advances have enabled automatic sound recognition systems for deaf and hard of hearing (DHH) users on mobile devices. However, these tools use pre-trained, generic sound recognition models, which do not meet the diverse needs of DHH users. We introduce ProtoSound, an interactive system for customizing sound recognition models by recording a few examples, thereby enabling personalized and fine-grained categories. ProtoSound is motivated by prior work examining sound awareness needs of DHH people and by a survey we conducted with 472 DHH participants. To evaluate ProtoSound, we characterized performance on two real-world sound datasets, showing significant improvement over state-of-the-art (e.g., +9.7% accuracy on the first dataset). We then deployed ProtoSound's end-user training and real-time recognition through a mobile application and recruited 19 hearing participants who listened to the real-world sounds and rated the accuracy across 56 locations (e.g., homes, restaurants, parks). Results show that ProtoSound personalized the model on-device in real-time and accurately learned sounds across diverse acoustic contexts. We close by discussing open challenges in personalizable sound recognition, including the need for better recording interfaces and algorithmic improvements.
Nonverbal Sound Detection for Disordered Speech
Feb 15, 2022
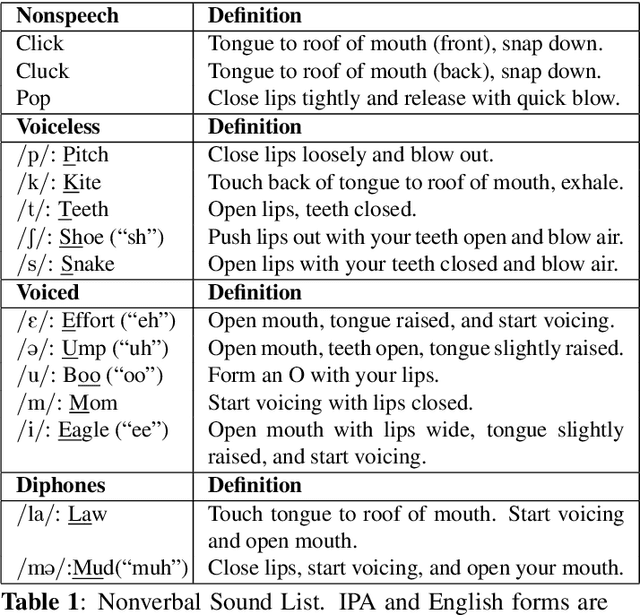


Voice assistants have become an essential tool for people with various disabilities because they enable complex phone- or tablet-based interactions without the need for fine-grained motor control, such as with touchscreens. However, these systems are not tuned for the unique characteristics of individuals with speech disorders, including many of those who have a motor-speech disorder, are deaf or hard of hearing, have a severe stutter, or are minimally verbal. We introduce an alternative voice-based input system which relies on sound event detection using fifteen nonverbal mouth sounds like "pop," "click," or "eh." This system was designed to work regardless of ones' speech abilities and allows full access to existing technology. In this paper, we describe the design of a dataset, model considerations for real-world deployment, and efforts towards model personalization. Our fully-supervised model achieves segment-level precision and recall of 88.6% and 88.4% on an internal dataset of 710 adults, while achieving 0.31 false positives per hour on aggressors such as speech. Five-shot personalization enables satisfactory performance in 84.5% of cases where the generic model fails.
Interactive Refinement of Cross-Lingual Word Embeddings
Nov 08, 2019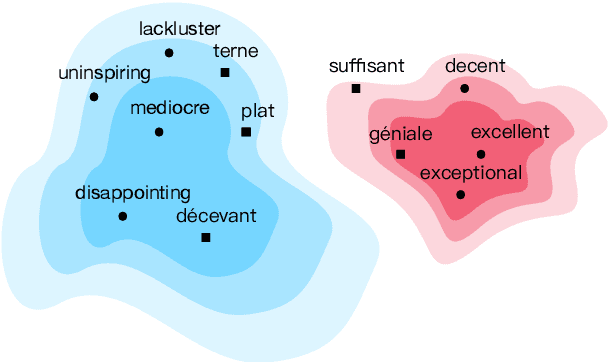



Cross-lingual word embeddings transfer knowledge between languages: models trained for a high-resource language can be used in a low-resource language. These embeddings are usually trained on general-purpose corpora but used for a domain-specific task. We introduce CLIME, an interactive system that allows a user to quickly adapt cross-lingual word embeddings for a given classification problem. First, words in the vocabulary are ranked by their salience to the downstream task. Then, salient keywords are displayed on an interface. Users mark the similarity between each keyword and its nearest neighbors in the embedding space. Finally, CLIME updates the embeddings using the annotations. We experiment clime on a cross-lingual text classification benchmark for four low-resource languages: Ilocano, Sinhalese, Tigrinya, and Uyghur. Embeddings refined by CLIME capture more nuanced word semantics and have higher test accuracy than the original embeddings. CLIME also improves test accuracy faster than an active learning baseline, and a simple combination of CLIME with active learning has the highest test accuracy.
Why Didn't You Listen to Me? Comparing User Control of Human-in-the-Loop Topic Models
Jun 04, 2019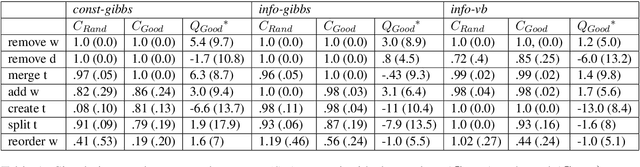
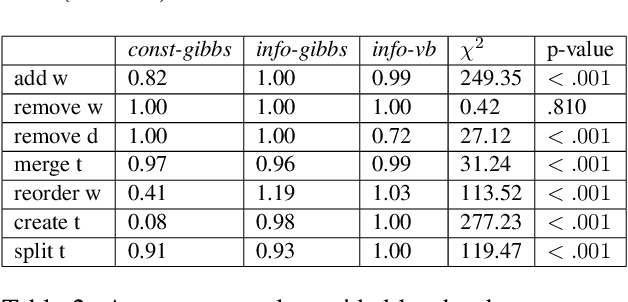
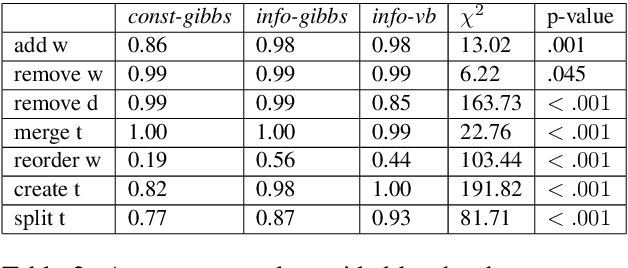
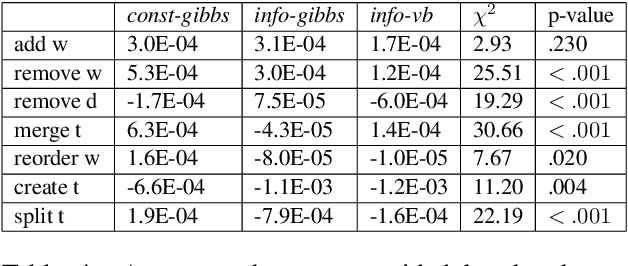
To address the lack of comparative evaluation of Human-in-the-Loop Topic Modeling (HLTM) systems, we implement and evaluate three contrasting HLTM modeling approaches using simulation experiments. These approaches extend previously proposed frameworks, including constraints and informed prior-based methods. Users should have a sense of control in HLTM systems, so we propose a control metric to measure whether refinement operations' results match users' expectations. Informed prior-based methods provide better control than constraints, but constraints yield higher quality topics.