 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Instance Tracking to Balance Privacy Preservation with Accessible Information
Dec 10, 2025

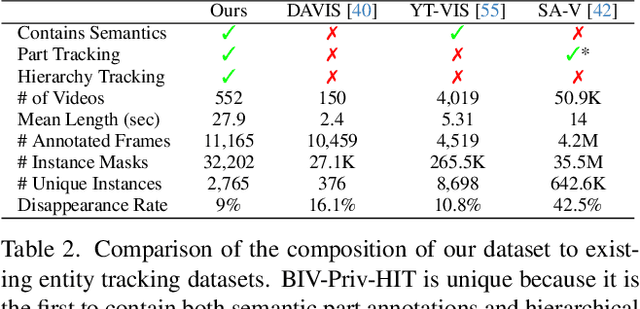
We propose a novel task, hierarchical instance tracking, which entails tracking all instances of predefined categories of objects and parts, while maintaining their hierarchical relationships. We introduce the first benchmark dataset supporting this task, consisting of 2,765 unique entities that are tracked in 552 videos and belong to 40 categories (across objects and parts). Evaluation of seven variants of four models tailored to our novel task reveals the new dataset is challenging. Our dataset is available at https://vizwiz.org/tasks-and-datasets/hierarchical-instance-tracking/
Signals of Provenance: Practices & Challenges of Navigating Indicators in AI-Generated Media for Sighted and Blind Individuals
May 21, 2025AI-Generated (AIG) content has become increasingly widespread by recent advances in generative models and the easy-to-use tools that have significantly lowered the technical barriers for producing highly realistic audio, images, and videos through simple natural language prompts. In response, platforms are adopting provable provenance with platforms recommending AIG to be self-disclosed and signaled to users. However, these indicators may be often missed, especially when they rely solely on visual cues and make them ineffective to users with different sensory abilities. To address the gap, we conducted semi-structured interviews (N=28) with 15 sighted and 13 BLV participants to examine their interaction with AIG content through self-disclosed AI indicators. Our findings reveal diverse mental models and practices, highlighting different strengths and weaknesses of content-based (e.g., title, description) and menu-aided (e.g., AI labels) indicators. While sighted participants leveraged visual and audio cues, BLV participants primarily relied on audio and existing assistive tools, limiting their ability to identify AIG. Across both groups, they frequently overlooked menu-aided indicators deployed by platforms and rather interacted with content-based indicators such as title and comments. We uncovered usability challenges stemming from inconsistent indicator placement, unclear metadata, and cognitive overload. These issues were especially critical for BLV individuals due to the insufficient accessibility of interface elements. We provide practical recommendations and design implications for future AIG indicators across several dimensions.
Personhood Credentials: Human-Centered Design Recommendation Balancing Security, Usability, and Trust
Feb 22, 2025



Building on related concepts, like, decentralized identifiers (DIDs), proof of personhood, anonymous credentials, personhood credentials (PHCs) emerged as an alternative approach, enabling individuals to verify to digital service providers that they are a person without disclosing additional information. However, new technologies might introduce some friction due to users misunderstandings and mismatched expectations. Despite their growing importance, limited research has been done on users perceptions and preferences regarding PHCs. To address this gap, we conducted competitive analysis, and semi-structured online user interviews with 23 participants from US and EU to provide concrete design recommendations for PHCs that incorporate user needs, adoption rules, and preferences. Our study -- (a)surfaces how people reason about unknown privacy and security guarantees of PHCs compared to current verification methods -- (b) presents the impact of several factors on how people would like to onboard and manage PHCs, including, trusted issuers (e.g. gov), ground truth data to issue PHC (e.g biometrics, physical id), and issuance system (e.g. centralized vs decentralized). In a think-aloud conceptual design session, participants recommended -- conceptualized design, such as periodic biometrics verification, time-bound credentials, visually interactive human-check, and supervision of government for issuance system. We propose actionable designs reflecting users preferences.
BIV-Priv-Seg: Locating Private Content in Images Taken by People With Visual Impairments
Jul 25, 2024
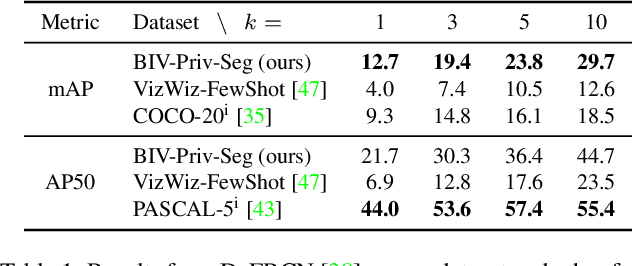


Individuals who are blind or have low vision (BLV) are at a heightened risk of sharing private information if they share photographs they have taken. To facilitate developing technologies that can help preserve privacy, we introduce BIV-Priv-Seg, the first localization dataset originating from people with visual impairments that shows private content. It contains 1,028 images with segmentation annotations for 16 private object categories. We first characterize BIV-Priv-Seg and then evaluate modern models' performance for locating private content in the dataset. We find modern models struggle most with locating private objects that are not salient, small, and lack text as well as recognizing when private content is absent from an image. We facilitate future extensions by sharing our new dataset with the evaluation server at https://vizwiz.org/tasks-and-datasets/object-localization.