 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Instance Tracking to Balance Privacy Preservation with Accessible Information
Dec 10, 2025

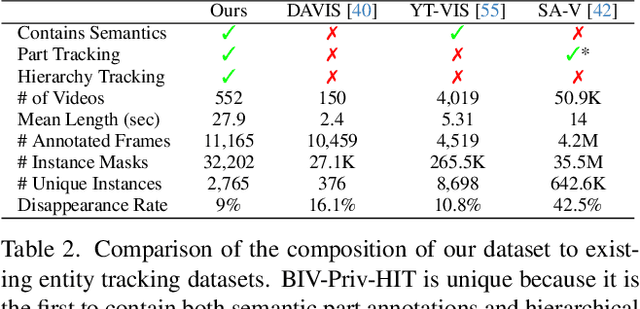
We propose a novel task, hierarchical instance tracking, which entails tracking all instances of predefined categories of objects and parts, while maintaining their hierarchical relationships. We introduce the first benchmark dataset supporting this task, consisting of 2,765 unique entities that are tracked in 552 videos and belong to 40 categories (across objects and parts). Evaluation of seven variants of four models tailored to our novel task reveals the new dataset is challenging. Our dataset is available at https://vizwiz.org/tasks-and-datasets/hierarchical-instance-tracking/
EditScribe: Non-Visual Image Editing with Natural Language Verification Loops
Aug 13, 2024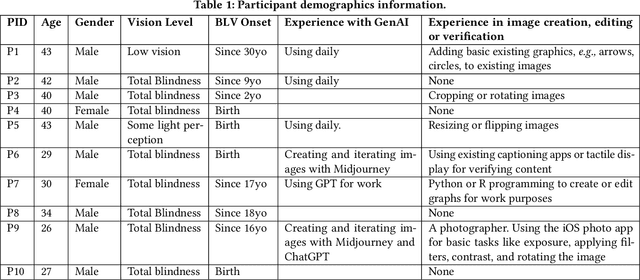



Image editing is an iterative process that requires precise visual evaluation and manipulation for the output to match the editing intent. However, current image editing tools do not provide accessible interaction nor sufficient feedback for blind and low vision individuals to achieve this level of control. To address this, we developed EditScribe, a prototype system that makes image editing accessible using natural language verification loops powered by large multimodal models. Using EditScribe, the user first comprehends the image content through initial general and object descriptions, then specifies edit actions using open-ended natural language prompts. EditScribe performs the image edit, and provides four types of verification feedback for the user to verify the performed edit, including a summary of visual changes, AI judgement, and updated general and object descriptions. The user can ask follow-up questions to clarify and probe into the edits or verification feedback, before performing another edit. In a study with ten blind or low-vision users, we found that EditScribe supported participants to perform and verify image edit actions non-visually. We observed different prompting strategies from participants, and their perceptions on the various types of verification feedback. Finally, we discuss the implications of leveraging natural language verification loops to make visual authoring non-visually accessible.
BIV-Priv-Seg: Locating Private Content in Images Taken by People With Visual Impairments
Jul 25, 2024
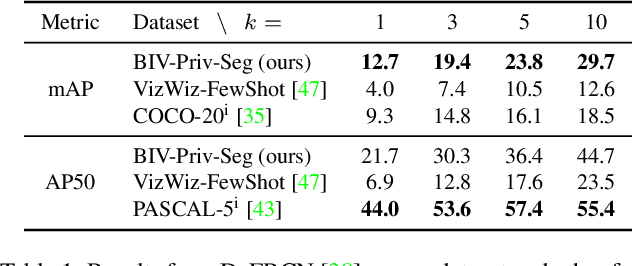


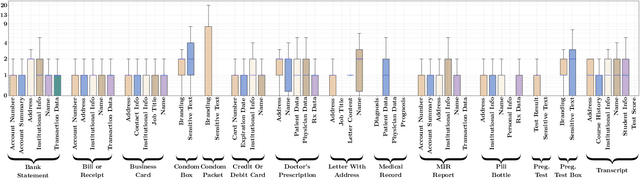
Individuals who are blind or have low vision (BLV) are at a heightened risk of sharing private information if they share photographs they have taken. To facilitate developing technologies that can help preserve privacy, we introduce BIV-Priv-Seg, the first localization dataset originating from people with visual impairments that shows private content. It contains 1,028 images with segmentation annotations for 16 private object categories. We first characterize BIV-Priv-Seg and then evaluate modern models' performance for locating private content in the dataset. We find modern models struggle most with locating private objects that are not salient, small, and lack text as well as recognizing when private content is absent from an image. We facilitate future extensions by sharing our new dataset with the evaluation server at https://vizwiz.org/tasks-and-datasets/object-localization.