 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Instance Tracking to Balance Privacy Preservation with Accessible Information
Dec 10, 2025

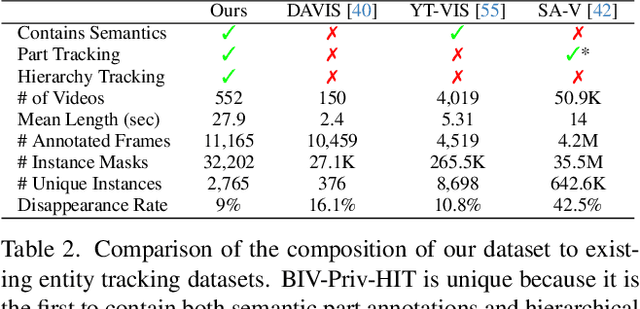
We propose a novel task, hierarchical instance tracking, which entails tracking all instances of predefined categories of objects and parts, while maintaining their hierarchical relationships. We introduce the first benchmark dataset supporting this task, consisting of 2,765 unique entities that are tracked in 552 videos and belong to 40 categories (across objects and parts). Evaluation of seven variants of four models tailored to our novel task reveals the new dataset is challenging. Our dataset is available at https://vizwiz.org/tasks-and-datasets/hierarchical-instance-tracking/
Logit-Based Losses Limit the Effectiveness of Feature Knowledge Distillation
Nov 18, 2025Knowledge distillation (KD) methods can transfer knowledge of a parameter-heavy teacher model to a light-weight student model. The status quo for feature KD methods is to utilize loss functions based on logits (i.e., pre-softmax class scores) and intermediate layer features (i.e., latent representations). Unlike previous approaches, we propose a feature KD framework for training the student's backbone using feature-based losses exclusively (i.e., without logit-based losses such as cross entropy). Leveraging recent discoveries about the geometry of latent representations, we introduce a knowledge quality metric for identifying which teacher layers provide the most effective knowledge for distillation. Experiments on three image classification datasets with four diverse student-teacher pairs, spanning convolutional neural networks and vision transformers, demonstrate our KD method achieves state-of-the-art performance, delivering top-1 accuracy boosts of up to 15% over standard approaches. We publically share our code to facilitate future work at https://github.com/Thegolfingocto/KD_wo_CE.
PartStickers: Generating Parts of Objects for Rapid Prototyping
Apr 07, 2025Design prototyping involves creating mockups of products or concepts to gather feedback and iterate on ideas. While prototyping often requires specific parts of objects, such as when constructing a novel creature for a video game, existing text-to-image methods tend to only generate entire objects. To address this, we propose a novel task and method of ``part sticker generation", which entails generating an isolated part of an object on a neutral background. Experiments demonstrate our method outperforms state-of-the-art baselines with respect to realism and text alignment, while preserving object-level generation capabilities. We publicly share our code and models to encourage community-wide progress on this new task: https://partsticker.github.io.
Accounting for Focus Ambiguity in Visual Questions
Jan 04, 2025



No existing work on visual question answering explicitly accounts for ambiguity regarding where the content described in the question is located in the image. To fill this gap, we introduce VQ-FocusAmbiguity, the first VQA dataset that visually grounds each region described in the question that is necessary to arrive at the answer. We then provide an analysis showing how our dataset for visually grounding `questions' is distinct from visually grounding `answers', and characterize the properties of the questions and segmentations provided in our dataset. Finally, we benchmark modern models for two novel tasks: recognizing whether a visual question has focus ambiguity and localizing all plausible focus regions within the image. Results show that the dataset is challenging for modern models. To facilitate future progress on these tasks, we publicly share the dataset with an evaluation server at https://focusambiguity.github.io/.
Long-Form Answers to Visual Questions from Blind and Low Vision People
Aug 12, 2024



Vision language models can now generate long-form answers to questions about images - long-form visual question answers (LFVQA). We contribute VizWiz-LF, a dataset of long-form answers to visual questions posed by blind and low vision (BLV) users. VizWiz-LF contains 4.2k long-form answers to 600 visual questions, collected from human expert describers and six VQA models. We develop and annotate functional roles of sentences of LFVQA and demonstrate that long-form answers contain information beyond the question answer such as explanations and suggestions. We further conduct automatic and human evaluations with BLV and sighted people to evaluate long-form answers. BLV people perceive both human-written and generated long-form answers to be plausible, but generated answers often hallucinate incorrect visual details, especially for unanswerable visual questions (e.g., blurry or irrelevant images). To reduce hallucinations, we evaluate the ability of VQA models to abstain from answering unanswerable questions across multiple prompting strategies.
BIV-Priv-Seg: Locating Private Content in Images Taken by People With Visual Impairments
Jul 25, 2024
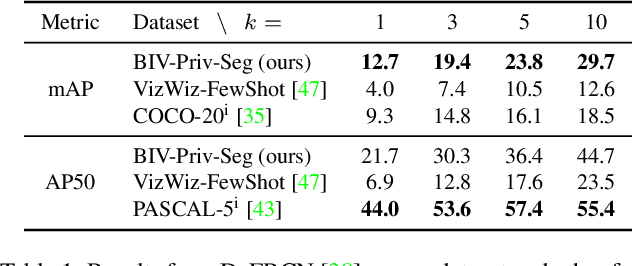


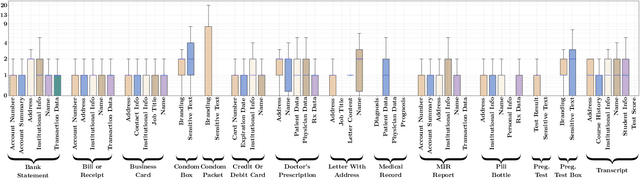
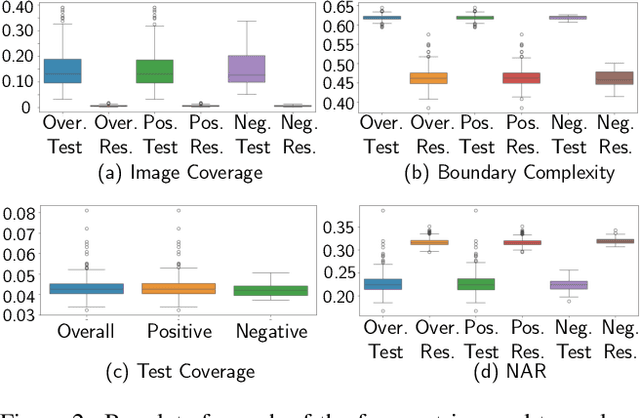
Individuals who are blind or have low vision (BLV) are at a heightened risk of sharing private information if they share photographs they have taken. To facilitate developing technologies that can help preserve privacy, we introduce BIV-Priv-Seg, the first localization dataset originating from people with visual impairments that shows private content. It contains 1,028 images with segmentation annotations for 16 private object categories. We first characterize BIV-Priv-Seg and then evaluate modern models' performance for locating private content in the dataset. We find modern models struggle most with locating private objects that are not salient, small, and lack text as well as recognizing when private content is absent from an image. We facilitate future extensions by sharing our new dataset with the evaluation server at https://vizwiz.org/tasks-and-datasets/object-localization.
SPIN: Hierarchical Segmentation with Subpart Granularity in Natural Images
Jul 12, 2024Hierarchical segmentation entails creating segmentations at varying levels of granularity. We introduce the first hierarchical semantic segmentation dataset with subpart annotations for natural images, which we call SPIN (SubPartImageNet). We also introduce two novel evaluation metrics to evaluate how well algorithms capture spatial and semantic relationships across hierarchical levels. We benchmark modern models across three different tasks and analyze their strengths and weaknesses across objects, parts, and subparts. To facilitate community-wide progress, we publicly release our dataset at https://joshmyersdean.github.io/spin/index.html.
Collecting Consistently High Quality Object Tracks with Minimal Human Involvement by Using Self-Supervised Learning to Detect Tracker Errors
May 06, 2024We propose a hybrid framework for consistently producing high-quality object tracks by combining an automated object tracker with little human input. The key idea is to tailor a module for each dataset to intelligently decide when an object tracker is failing and so humans should be brought in to re-localize an object for continued tracking. Our approach leverages self-supervised learning on unlabeled videos to learn a tailored representation for a target object that is then used to actively monitor its tracked region and decide when the tracker fails. Since labeled data is not needed, our approach can be applied to novel object categories. Experiments on three datasets demonstrate our method outperforms existing approaches, especially for small, fast moving, or occluded objects.
Interpreting COVID Lateral Flow Tests' Results with Foundation Models
Apr 21, 2024

Lateral flow tests (LFTs) enable rapid, low-cost testing for health conditions including Covid, pregnancy, HIV, and malaria. Automated readers of LFT results can yield many benefits including empowering blind people to independently learn about their health and accelerating data entry for large-scale monitoring (e.g., for pandemics such as Covid) by using only a single photograph per LFT test. Accordingly, we explore the abilities of modern foundation vision language models (VLMs) in interpreting such tests. To enable this analysis, we first create a new labeled dataset with hierarchical segmentations of each LFT test and its nested test result window. We call this dataset LFT-Grounding. Next, we benchmark eight modern VLMs in zero-shot settings for analyzing these images. We demonstrate that current VLMs frequently fail to correctly identify the type of LFT test, interpret the test results, locate the nested result window of the LFT tests, and recognize LFT tests when they partially obfuscated. To facilitate community-wide progress towards automated LFT reading, we publicly release our dataset at https://iamstuti.github.io/lft_grounding_foundation_models/.
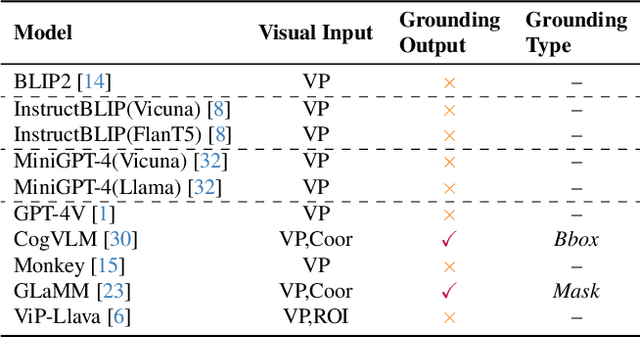
Fully Authentic Visual Question Answering Dataset from Online Communities
Nov 27, 2023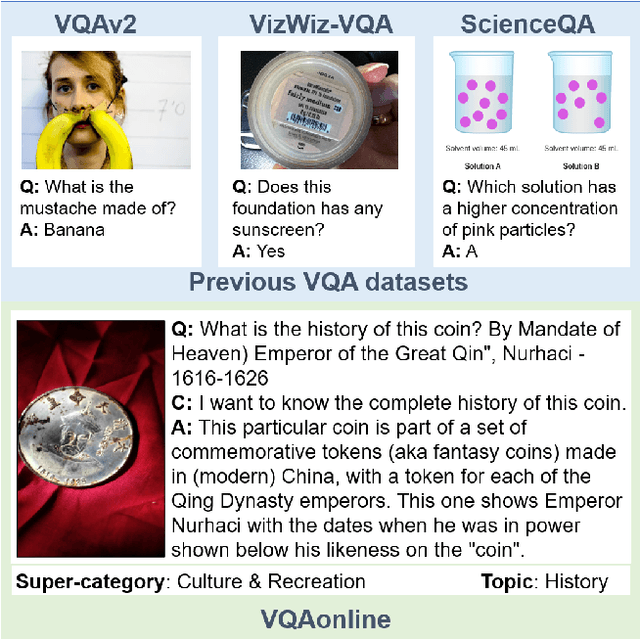
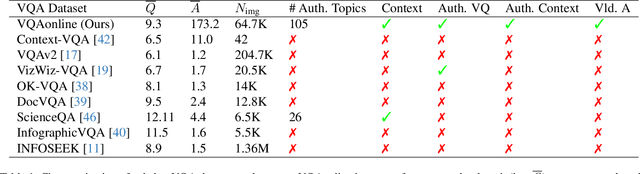
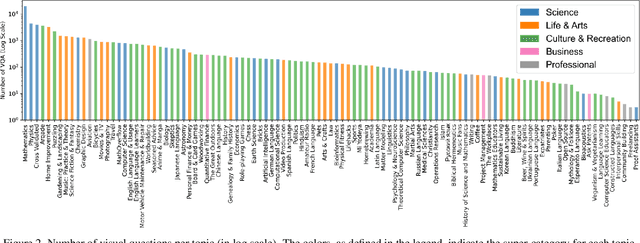
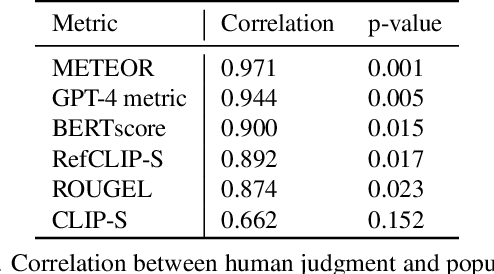
Visual Question Answering (VQA) entails answering questions about images. We introduce the first VQA dataset in which all contents originate from an authentic use case. Sourced from online question answering community forums, we call it VQAonline. We then characterize our dataset and how it relates to eight other VQA datasets. Observing that answers in our dataset tend to be much longer (e.g., with a mean of 173 words) and thus incompatible with standard VQA evaluation metrics, we next analyze which of the six popular metrics for longer text evaluation align best with human judgments. We then use the best-suited metrics to evaluate six state-of-the-art vision and language foundation models on VQAonline and reveal where they struggle most. We will release the dataset soon to facilitate future extensions.