 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting COVID Lateral Flow Tests' Results with Foundation Models
Paper and Code


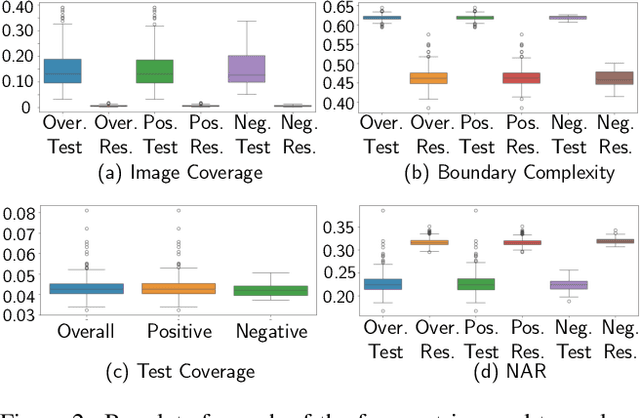
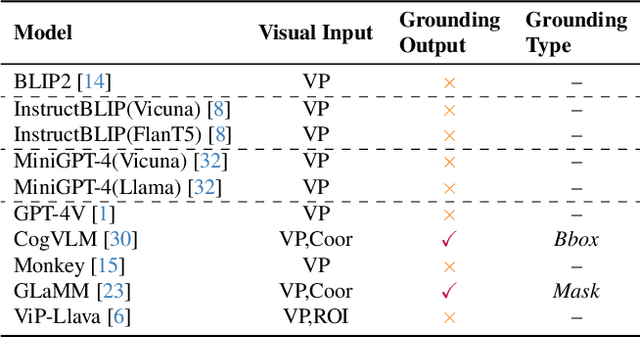
Lateral flow tests (LFTs) enable rapid, low-cost testing for health conditions including Covid, pregnancy, HIV, and malaria. Automated readers of LFT results can yield many benefits including empowering blind people to independently learn about their health and accelerating data entry for large-scale monitoring (e.g., for pandemics such as Covid) by using only a single photograph per LFT test. Accordingly, we explore the abilities of modern foundation vision language models (VLMs) in interpreting such tests. To enable this analysis, we first create a new labeled dataset with hierarchical segmentations of each LFT test and its nested test result window. We call this dataset LFT-Grounding. Next, we benchmark eight modern VLMs in zero-shot settings for analyzing these images. We demonstrate that current VLMs frequently fail to correctly identify the type of LFT test, interpret the test results, locate the nested result window of the LFT tests, and recognize LFT tests when they partially obfuscated. To facilitate community-wide progress towards automated LFT reading, we publicly release our dataset at https://iamstuti.github.io/lft_grounding_foundation_models/.