 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Instance Tracking to Balance Privacy Preservation with Accessible Information
Dec 10, 2025

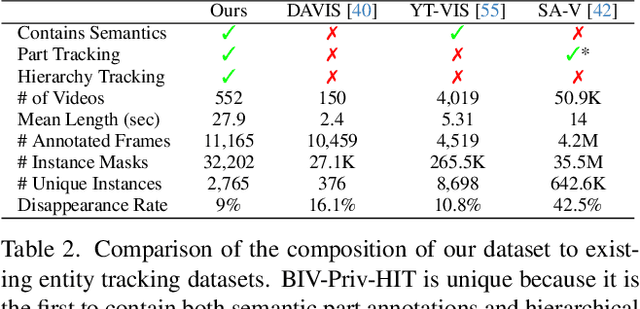
We propose a novel task, hierarchical instance tracking, which entails tracking all instances of predefined categories of objects and parts, while maintaining their hierarchical relationships. We introduce the first benchmark dataset supporting this task, consisting of 2,765 unique entities that are tracked in 552 videos and belong to 40 categories (across objects and parts). Evaluation of seven variants of four models tailored to our novel task reveals the new dataset is challenging. Our dataset is available at https://vizwiz.org/tasks-and-datasets/hierarchical-instance-tracking/
SPIN: Hierarchical Segmentation with Subpart Granularity in Natural Images
Jul 12, 2024Hierarchical segmentation entails creating segmentations at varying levels of granularity. We introduce the first hierarchical semantic segmentation dataset with subpart annotations for natural images, which we call SPIN (SubPartImageNet). We also introduce two novel evaluation metrics to evaluate how well algorithms capture spatial and semantic relationships across hierarchical levels. We benchmark modern models across three different tasks and analyze their strengths and weaknesses across objects, parts, and subparts. To facilitate community-wide progress, we publicly release our dataset at https://joshmyersdean.github.io/spin/index.html.
Interpreting COVID Lateral Flow Tests' Results with Foundation Models
Apr 21, 2024

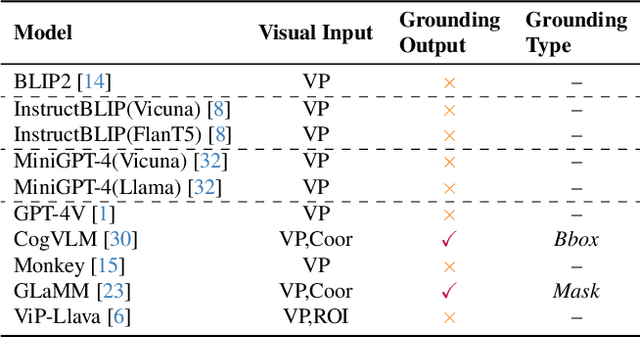
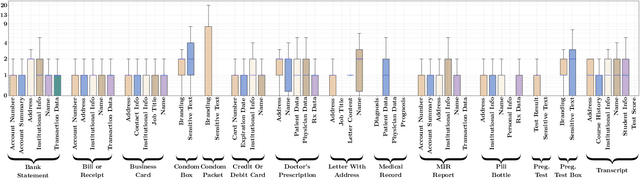
Lateral flow tests (LFTs) enable rapid, low-cost testing for health conditions including Covid, pregnancy, HIV, and malaria. Automated readers of LFT results can yield many benefits including empowering blind people to independently learn about their health and accelerating data entry for large-scale monitoring (e.g., for pandemics such as Covid) by using only a single photograph per LFT test. Accordingly, we explore the abilities of modern foundation vision language models (VLMs) in interpreting such tests. To enable this analysis, we first create a new labeled dataset with hierarchical segmentations of each LFT test and its nested test result window. We call this dataset LFT-Grounding. Next, we benchmark eight modern VLMs in zero-shot settings for analyzing these images. We demonstrate that current VLMs frequently fail to correctly identify the type of LFT test, interpret the test results, locate the nested result window of the LFT tests, and recognize LFT tests when they partially obfuscated. To facilitate community-wide progress towards automated LFT reading, we publicly release our dataset at https://iamstuti.github.io/lft_grounding_foundation_models/.
Salient Object Detection for Images Taken by People With Vision Impairments
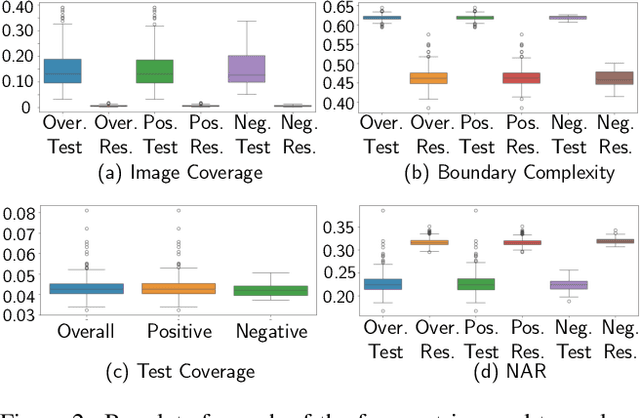
Jan 12, 2023Salient object detection is the task of producing a binary mask for an image that deciphers which pixels belong to the foreground object versus background. We introduce a new salient object detection dataset using images taken by people who are visually impaired who were seeking to better understand their surroundings, which we call VizWiz-SalientObject. Compared to seven existing datasets, VizWiz-SalientObject is the largest (i.e., 32,000 human-annotated images) and contains unique characteristics including a higher prevalence of text in the salient objects (i.e., in 68\% of images) and salient objects that occupy a larger ratio of the images (i.e., on average, $\sim$50\% coverage). We benchmarked seven modern salient object detection methods on our dataset and found they struggle most with images featuring salient objects that are large, have less complex boundaries, and lack text as well as for lower quality images. We invite the broader community to work on our new dataset challenge by publicly sharing the dataset at https://vizwiz.org/tasks-and-datasets/salient-object .