 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Abstractions for Verifying Properties of Kolmogorov-Arnold Networks (KANs)
Feb 06, 2026We present a novel approach for verifying properties of Kolmogorov-Arnold Networks (KANs), a class of neural networks characterized by nonlinear, univariate activation functions typically implemented as piecewise polynomial splines or Gaussian processes. Our method creates mathematical ``abstractions'' by replacing each KAN unit with a piecewise affine (PWA) function, providing both local and global error estimates between the original network and its approximation. These abstractions enable property verification by encoding the problem as a Mixed Integer Linear Program (MILP), determining whether outputs satisfy specified properties when inputs belong to a given set. A critical challenge lies in balancing the number of pieces in the PWA approximation: too many pieces add binary variables that make verification computationally intractable, while too few pieces create excessive error margins that yield uninformative bounds. Our key contribution is a systematic framework that exploits KAN structure to find optimal abstractions. By combining dynamic programming at the unit level with a knapsack optimization across the network, we minimize the total number of pieces while guaranteeing specified error bounds. This approach determines the optimal approximation strategy for each unit while maintaining overall accuracy requirements. Empirical evaluation across multiple KAN benchmarks demonstrates that the upfront analysis costs of our method are justified by superior verification results.
Salient Object Detection for Images Taken by People With Vision Impairments
Jan 12, 2023Salient object detection is the task of producing a binary mask for an image that deciphers which pixels belong to the foreground object versus background. We introduce a new salient object detection dataset using images taken by people who are visually impaired who were seeking to better understand their surroundings, which we call VizWiz-SalientObject. Compared to seven existing datasets, VizWiz-SalientObject is the largest (i.e., 32,000 human-annotated images) and contains unique characteristics including a higher prevalence of text in the salient objects (i.e., in 68\% of images) and salient objects that occupy a larger ratio of the images (i.e., on average, $\sim$50\% coverage). We benchmarked seven modern salient object detection methods on our dataset and found they struggle most with images featuring salient objects that are large, have less complex boundaries, and lack text as well as for lower quality images. We invite the broader community to work on our new dataset challenge by publicly sharing the dataset at https://vizwiz.org/tasks-and-datasets/salient-object .
The Birds Need Attention Too: Analysing usage of Self Attention in identifying bird calls in soundscapes
Nov 14, 2022Birds are vital parts of ecosystems across the world and are an excellent measure of the quality of life on earth. Many bird species are endangered while others are already extinct. Ecological efforts in understanding and monitoring bird populations are important to conserve their habitat and species, but this mostly relies on manual methods in rough terrains. Recent advances in Machine Learning and Deep Learning have made automatic bird recognition in diverse environments possible. Birdcall recognition till now has been performed using convolutional neural networks. In this work, we try and understand how self-attention can aid in this endeavor. With that we build an pre-trained Attention-based Spectrogram Transformer baseline for BirdCLEF 2022 and compare the results against the pre-trained Convolution-based baseline. Our results show that the transformer models outperformed the convolutional model and we further validate our results by building baselines and analyzing the results for the previous year BirdCLEF 2021 challenge. Source code available at https://github.com/ck090/BirdCLEF-22
Identifying Missing Component in the Bechdel Test Using Principal Component Analysis Method
Jun 19, 2019


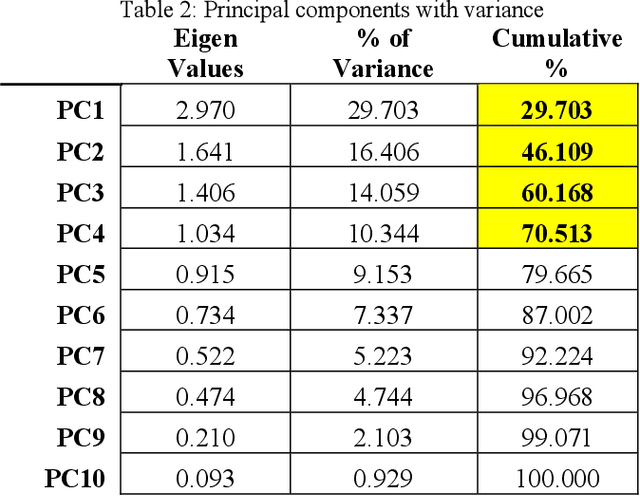
A lot has been said and discussed regarding the rationale and significance of the Bechdel Score. It became a digital sensation in 2013 when Swedish cinemas began to showcase the Bechdel test score of a film alongside its rating. The test has drawn criticism from experts and the film fraternity regarding its use to rate the female presence in a movie. The pundits believe that the score is too simplified and the underlying criteria of a film to pass the test must include 1) at least two women, 2) who have at least one dialogue, 3) about something other than a man, is egregious. In this research, we have considered a few more parameters which highlight how we represent females in film, like the number of female dialogues in a movie, dialogue genre, and part of speech tags in the dialogue. The parameters were missing in the existing criteria to calculate the Bechdel score. The research aims to analyze 342 movies scripts to test a hypothesis if these extra parameters, above with the current Bechdel criteria, are significant in calculating the female representation score. The result of the Principal Component Analysis method concludes that the female dialogue content is a key component and should be considered while measuring the representation of women in a work of fiction.