 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Than the Final Answer: Improving Visual Extraction and Logical Consistency in Vision-Language Models
Dec 13, 2025Reinforcement learning from verifiable rewards (RLVR) has recently been extended from text-only LLMs to vision-language models (VLMs) to elicit long-chain multimodal reasoning. However, RLVR-trained VLMs still exhibit two persistent failure modes: inaccurate visual extraction (missing or hallucinating details) and logically inconsistent chains-of-thought, largely because verifiable signals supervise only the final answer. We propose PeRL-VL (Perception and Reasoning Learning for Vision-Language Models), a decoupled framework that separately improves visual perception and textual reasoning on top of RLVR. For perception, PeRL-VL introduces a VLM-based description reward that scores the model's self-generated image descriptions for faithfulness and sufficiency. For reasoning, PeRL-VL adds a text-only Reasoning SFT stage on logic-rich chain-of-thought data, enhancing coherence and logical consistency independently of vision. Across diverse multimodal benchmarks, PeRL-VL improves average Pass@1 accuracy from 63.3% (base Qwen2.5-VL-7B) to 68.8%, outperforming standard RLVR, text-only reasoning SFT, and naive multimodal distillation from GPT-4o.
Multi-Target Position Error Bound and Power Allocation Scheme for Cell-Free mMIMO-OTFS ISAC Systems
Apr 14, 2025



This paper investigates multi-target position estimation in cell-free massive multiple-input multiple-output (CF mMIMO) architectures, where orthogonal time frequency and space (OTFS) is used as an integrated sensing and communication (ISAC) signal. Closed-form expressions for the Cram\'{e}r-Rao lower bound and the positioning error bound (PEB) in multi-target position estimation are derived, providing quantitative evaluations of sensing performance. To enhance the overall performance of the ISAC system, a power allocation algorithm is developed to maximize the minimum user communication signal-to-interference-plus-noise ratio while ensuring a specified sensing PEB requirement. The results validate the proposed PEB expression and its approximation, clearly illustrating the coordination gain enabled by ISAC. Further, the superiority of using the multi-static CF mMIMO architecture over traditional cellular ISAC is demonstrated, and the advantages of OTFS signals in high-mobility scenarios are highlighted.
SPIN: Hierarchical Segmentation with Subpart Granularity in Natural Images
Jul 12, 2024Hierarchical segmentation entails creating segmentations at varying levels of granularity. We introduce the first hierarchical semantic segmentation dataset with subpart annotations for natural images, which we call SPIN (SubPartImageNet). We also introduce two novel evaluation metrics to evaluate how well algorithms capture spatial and semantic relationships across hierarchical levels. We benchmark modern models across three different tasks and analyze their strengths and weaknesses across objects, parts, and subparts. To facilitate community-wide progress, we publicly release our dataset at https://joshmyersdean.github.io/spin/index.html.
Power Allocation for Cell-Free Massive MIMO ISAC Systems with OTFS Signal
May 30, 2024Applying integrated sensing and communication (ISAC) to a cell-free massive multiple-input multiple-output (CF mMIMO) architecture has attracted increasing attention. This approach equips CF mMIMO networks with sensing capabilities and resolves the problem of unreliable service at cell edges in conventional cellular networks. However, existing studies on CF-ISAC systems have focused on the application of traditional integrated signals. To address this limitation, this study explores the employment of the orthogonal time frequency space (OTFS) signal as a representative of innovative signals in the CF-ISAC system, and the system's overall performance is optimized and evaluated. A universal downlink spectral efficiency (SE) expression is derived regarding multi-antenna access points (APs) and optional sensing beams. To streamline the analysis and optimization of the CF-ISAC system with the OTFS signal, we introduce a lower bound on the achievable SE that is applicable to OTFS-signal-based systems. Based on this, a power allocation algorithm is proposed to maximize the minimum communication signal-to-interference-plus-noise ratio (SINR) of users while guaranteeing a specified sensing SINR value and meeting the per-AP power constraints. The results demonstrate the tightness of the proposed lower bound and the efficiency of the proposed algorithm. Finally, the superiority of using the OTFS signals is verified by a 13-fold expansion of the SE performance gap over the application of orthogonal frequency division multiplexing signals. These findings could guide the future deployment of the CF-ISAC systems, particularly in the field of millimeter waves with a large bandwidth.
VIXEN: Visual Text Comparison Network for Image Difference Captioning
Mar 14, 2024
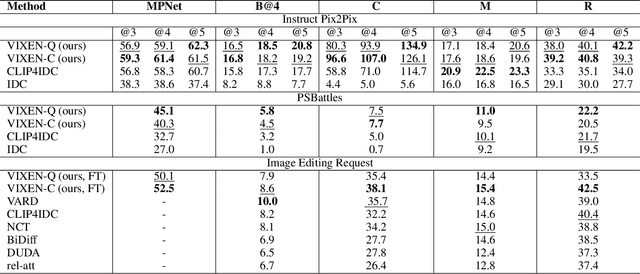
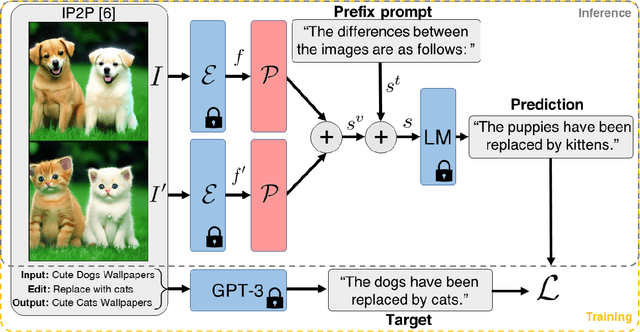
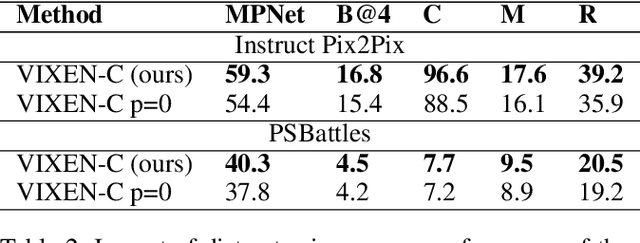
We present VIXEN - a technique that succinctly summarizes in text the visual differences between a pair of images in order to highlight any content manipulation present. Our proposed network linearly maps image features in a pairwise manner, constructing a soft prompt for a pretrained large language model. We address the challenge of low volume of training data and lack of manipulation variety in existing image difference captioning (IDC) datasets by training on synthetically manipulated images from the recent InstructPix2Pix dataset generated via prompt-to-prompt editing framework. We augment this dataset with change summaries produced via GPT-3. We show that VIXEN produces state-of-the-art, comprehensible difference captions for diverse image contents and edit types, offering a potential mitigation against misinformation disseminated via manipulated image content. Code and data are available at http://github.com/alexblck/vixen
Interactive Segmentation for Diverse Gesture Types Without Context
Jul 20, 2023Interactive segmentation entails a human marking an image to guide how a model either creates or edits a segmentation. Our work addresses limitations of existing methods: they either only support one gesture type for marking an image (e.g., either clicks or scribbles) or require knowledge of the gesture type being employed, and require specifying whether marked regions should be included versus excluded in the final segmentation. We instead propose a simplified interactive segmentation task where a user only must mark an image, where the input can be of any gesture type without specifying the gesture type. We support this new task by introducing the first interactive segmentation dataset with multiple gesture types as well as a new evaluation metric capable of holistically evaluating interactive segmentation algorithms. We then analyze numerous interactive segmentation algorithms, including ones adapted for our novel task. While we observe promising performance overall, we also highlight areas for future improvement. To facilitate further extensions of this work, we publicly share our new dataset at https://github.com/joshmyersdean/dig.
Layered Depth Refinement with Mask Guidance
Jun 07, 2022
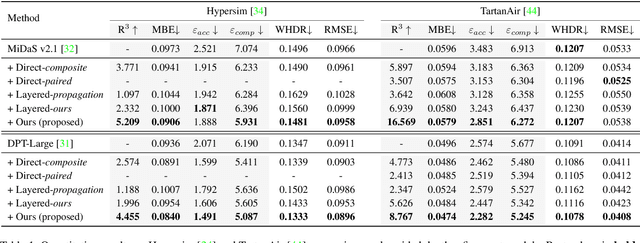
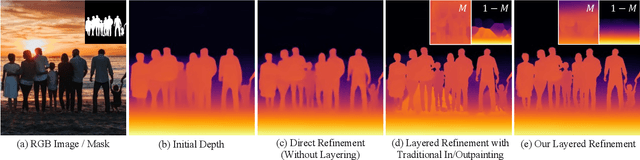
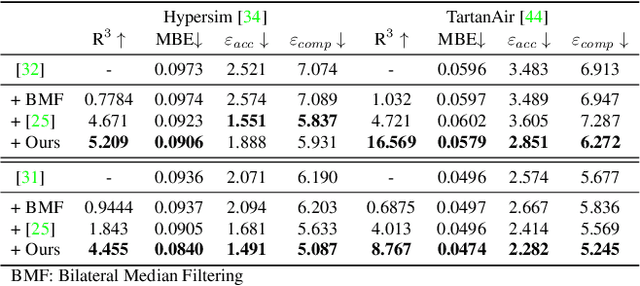
Depth maps are used in a wide range of applications from 3D rendering to 2D image effects such as Bokeh. However, those predicted by single image depth estimation (SIDE) models often fail to capture isolated holes in objects and/or have inaccurate boundary regions. Meanwhile, high-quality masks are much easier to obtain, using commercial auto-masking tools or off-the-shelf methods of segmentation and matting or even by manual editing. Hence, in this paper, we formulate a novel problem of mask-guided depth refinement that utilizes a generic mask to refine the depth prediction of SIDE models. Our framework performs layered refinement and inpainting/outpainting, decomposing the depth map into two separate layers signified by the mask and the inverse mask. As datasets with both depth and mask annotations are scarce, we propose a self-supervised learning scheme that uses arbitrary masks and RGB-D datasets. We empirically show that our method is robust to different types of masks and initial depth predictions, accurately refining depth values in inner and outer mask boundary regions. We further analyze our model with an ablation study and demonstrate results on real applications. More information can be found at https://sooyekim.github.io/MaskDepth/ .
Verifying the Causes of Adversarial Examples
Oct 19, 2020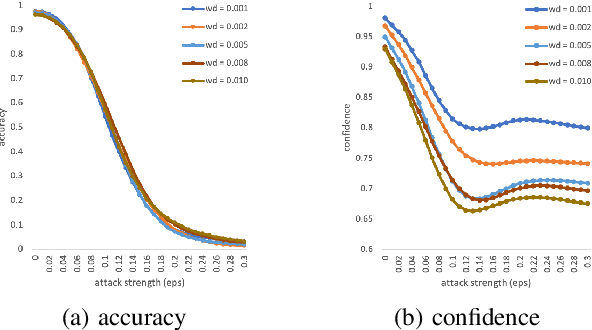
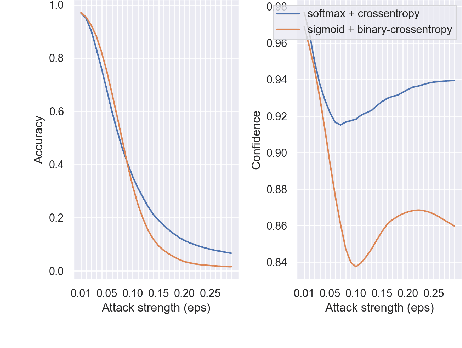
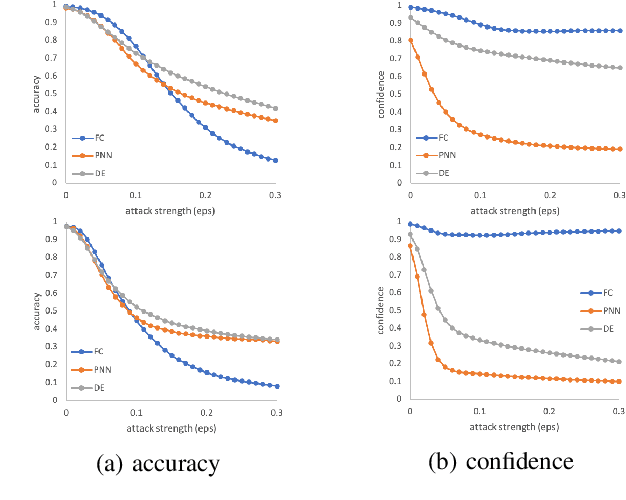
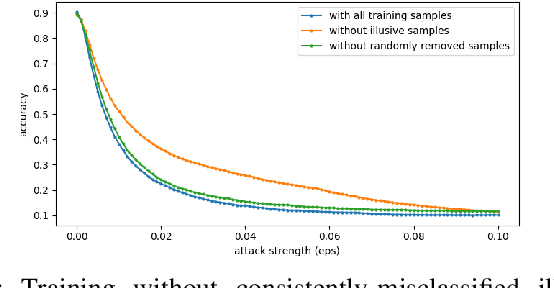
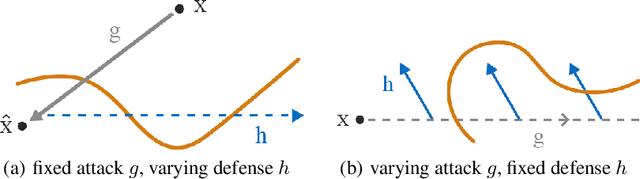
The robustness of neural networks is challenged by adversarial examples that contain almost imperceptible perturbations to inputs, which mislead a classifier to incorrect outputs in high confidence. Limited by the extreme difficulty in examining a high-dimensional image space thoroughly, research on explaining and justifying the causes of adversarial examples falls behind studies on attacks and defenses. In this paper, we present a collection of potential causes of adversarial examples and verify (or partially verify) them through carefully-designed controlled experiments. The major causes of adversarial examples include model linearity, one-sum constraint, and geometry of the categories. To control the effect of those causes, multiple techniques are applied such as $L_2$ normalization, replacement of loss functions, construction of reference datasets, and novel models using multi-layer perceptron probabilistic neural networks (MLP-PNN) and density estimation (DE). Our experiment results show that geometric factors tend to be more direct causes and statistical factors magnify the phenomenon, especially for assigning high prediction confidence. We believe this paper will inspire more studies to rigorously investigate the root causes of adversarial examples, which in turn provide useful guidance on designing more robust models.
An Adaptive View of Adversarial Robustness from Test-time Smoothing Defense
Nov 26, 2019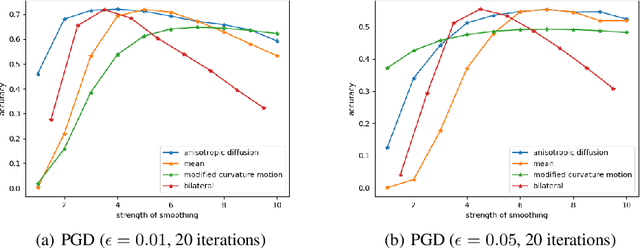

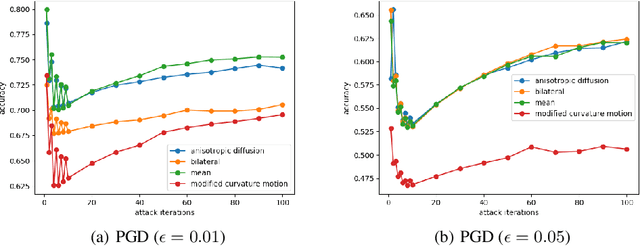
The safety and robustness of learning-based decision-making systems are under threats from adversarial examples, as imperceptible perturbations can mislead neural networks to completely different outputs. In this paper, we present an adaptive view of the issue via evaluating various test-time smoothing defense against white-box untargeted adversarial examples. Through controlled experiments with pretrained ResNet-152 on ImageNet, we first illustrate the non-monotonic relation between adversarial attacks and smoothing defenses. Then at the dataset level, we observe large variance among samples and show that it is easy to inflate accuracy (even to 100%) or build large-scale (i.e., with size ~10^4) subsets on which a designated method outperforms others by a large margin. Finally at the sample level, as different adversarial examples require different degrees of defense, the potential advantages of iterative methods are also discussed. We hope this paper reveal useful behaviors of test-time defenses, which could help improve the evaluation process for adversarial robustness in the future.
Towards an Understanding of Neural Networks in Natural-Image Spaces
Jan 27, 2018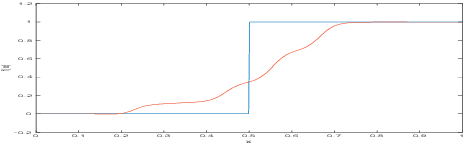



Two major uncertainties, dataset bias and perturbation, prevail in state-of-the-art AI algorithms with deep neural networks. In this paper, we present an intuitive explanation for these issues as well as an interpretation of the performance of deep networks in a natural-image space. The explanation consists of two parts: the philosophy of neural networks and a hypothetic model of natural-image spaces. Following the explanation, we slightly improve the accuracy of a CIFAR-10 classifier by introducing an additional "random-noise" category during training. We hope this paper will stimulate discussion in the community regarding the topological and geometric properties of natural-image spaces to which deep networks are applied.