 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLANET v2.0: A comprehensive Protein-Ligand Affinity Prediction Model Based on Mixture Density Network
Jan 12, 2026Drug discovery represents a time-consuming and financially intensive process, and virtual screening can accelerate it. Scoring functions, as one of the tools guiding virtual screening, have their precision closely tied to screening efficiency. In our previous study, we developed a graph neural network model called PLANET (Protein-Ligand Affinity prediction NETwork), but it suffers from the defect in representing protein-ligand contact maps. Incorrect binding modes inevitably lead to poor affinity predictions, so accurate prediction of the protein-ligand contact map is desired to improve PLANET. In this study, we have proposed PLANET v2.0 as an upgraded version. The model is trained via multi-objective training strategy and incorporates the Mixture Density Network to predict binding modes. Except for the probability density distributions of non-covalent interactions, we innovatively employ another Gaussian mixture model to describe the relationship between distance and energy of each interaction pair and predict protein-ligand affinity like calculating the mathematical expectation. As on the CASF-2016 benchmark, PLANET v2.0 demonstrates excellent scoring power, ranking power, and docking power. The screening power of PLANET v2.0 gets notably improved compared to PLANET and Glide SP and it demonstrates robust validation on a commercial ultra-large-scale dataset. Given its efficiency and accuracy, PLANET v2.0 can hopefully become one of the practical tools for virtual screening workflows. PLANET v2.0 is freely available at https://www.pdbbind-plus.org.cn/planetv2.
LLMs for Supply Chain Management
May 24, 2025The development of large language models (LLMs) has provided new tools for research in supply chain management (SCM). In this paper, we introduce a retrieval-augmented generation (RAG) framework that dynamically integrates external knowledge into the inference process, and develop a domain-specialized SCM LLM, which demonstrates expert-level competence by passing standardized SCM examinations and beer game tests. We further employ the use of LLMs to conduct horizontal and vertical supply chain games, in order to analyze competition and cooperation within supply chains. Our experiments show that RAG significantly improves performance on SCM tasks. Moreover, game-theoretic analysis reveals that the LLM can reproduce insights from the classical SCM literature, while also uncovering novel behaviors and offering fresh perspectives on phenomena such as the bullwhip effect. This paper opens the door for exploring cooperation and competition for complex supply chain network through the lens of LLMs.
SpecRouter: Adaptive Routing for Multi-Level Speculative Decoding in Large Language Models
May 12, 2025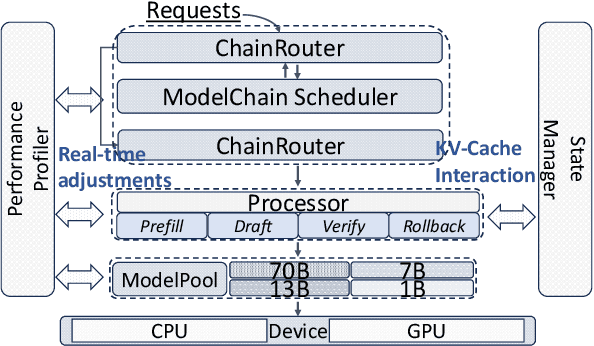
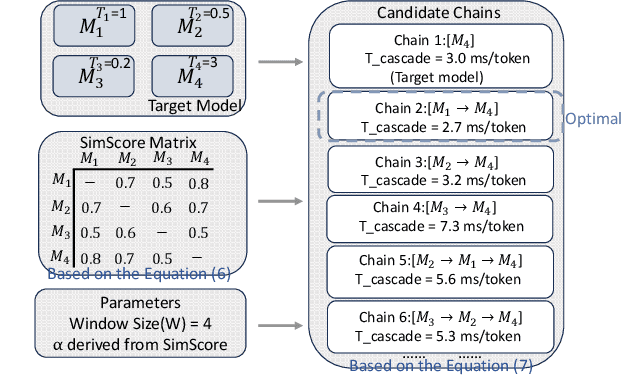
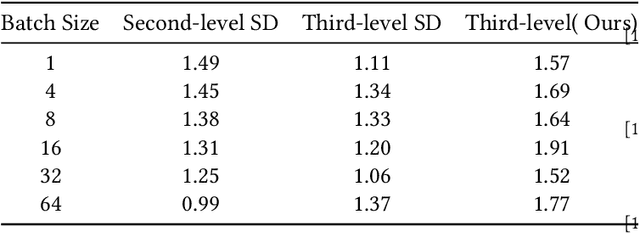
Large Language Models (LLMs) present a critical trade-off between inference quality and computational cost: larger models offer superior capabilities but incur significant latency, while smaller models are faster but less powerful. Existing serving strategies often employ fixed model scales or static two-stage speculative decoding, failing to dynamically adapt to the varying complexities of user requests or fluctuations in system performance. This paper introduces \systemname{}, a novel framework that reimagines LLM inference as an adaptive routing problem solved through multi-level speculative decoding. \systemname{} dynamically constructs and optimizes inference "paths" (chains of models) based on real-time feedback, addressing the limitations of static approaches. Our contributions are threefold: (1) An \textbf{adaptive model chain scheduling} mechanism that leverages performance profiling (execution times) and predictive similarity metrics (derived from token distribution divergence) to continuously select the optimal sequence of draft and verifier models, minimizing predicted latency per generated token. (2) A \textbf{multi-level collaborative verification} framework where intermediate models within the selected chain can validate speculative tokens, reducing the verification burden on the final, most powerful target model. (3) A \textbf{synchronized state management} system providing efficient, consistent KV cache handling across heterogeneous models in the chain, including precise, low-overhead rollbacks tailored for asynchronous batch processing inherent in multi-level speculation. Preliminary experiments demonstrate the validity of our method.
Multi-Target Position Error Bound and Power Allocation Scheme for Cell-Free mMIMO-OTFS ISAC Systems
Apr 14, 2025This paper investigates multi-target position estimation in cell-free massive multiple-input multiple-output (CF mMIMO) architectures, where orthogonal time frequency and space (OTFS) is used as an integrated sensing and communication (ISAC) signal. Closed-form expressions for the Cram\'{e}r-Rao lower bound and the positioning error bound (PEB) in multi-target position estimation are derived, providing quantitative evaluations of sensing performance. To enhance the overall performance of the ISAC system, a power allocation algorithm is developed to maximize the minimum user communication signal-to-interference-plus-noise ratio while ensuring a specified sensing PEB requirement. The results validate the proposed PEB expression and its approximation, clearly illustrating the coordination gain enabled by ISAC. Further, the superiority of using the multi-static CF mMIMO architecture over traditional cellular ISAC is demonstrated, and the advantages of OTFS signals in high-mobility scenarios are highlighted.
TritonBench: Benchmarking Large Language Model Capabilities for Generating Triton Operators
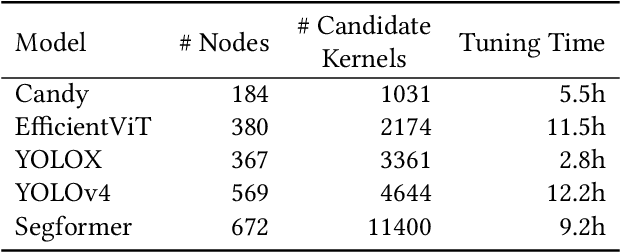
Feb 20, 2025Triton, a high-level Python-like language designed for building efficient GPU kernels, is widely adopted in deep learning frameworks due to its portability, flexibility, and accessibility. However, programming and parallel optimization still require considerable trial and error from Triton developers. Despite advances in large language models (LLMs) for conventional code generation, these models struggle to generate accurate, performance-optimized Triton code, as they lack awareness of its specifications and the complexities of GPU programming. More critically, there is an urgent need for systematic evaluations tailored to Triton. In this work, we introduce TritonBench, the first comprehensive benchmark for Triton operator generation. TritonBench features two evaluation channels: a curated set of 184 real-world operators from GitHub and a collection of operators aligned with PyTorch interfaces. Unlike conventional code benchmarks prioritizing functional correctness, TritonBench also profiles efficiency performance on widely deployed GPUs aligned with industry applications. Our study reveals that current state-of-the-art code LLMs struggle to generate efficient Triton operators, highlighting a significant gap in high-performance code generation. TritonBench will be available at https://github.com/thunlp/TritonBench.
COMET:Combined Matrix for Elucidating Targets
Dec 03, 2024



Identifying the interaction targets of bioactive compounds is a foundational element for deciphering their pharmacological effects. Target prediction algorithms equip researchers with an effective tool to rapidly scope and explore potential targets. Here, we introduce the COMET, a multi-technological modular target prediction tool that provides comprehensive predictive insights, including similar active compounds, three-dimensional predicted binding modes, and probability scores, all within an average processing time of less than 10 minutes per task. With meticulously curated data, the COMET database encompasses 990,944 drug-target interaction pairs and 45,035 binding pockets, enabling predictions for 2,685 targets, which span confirmed and exploratory therapeutic targets for human diseases. In comparative testing using datasets from ChEMBL and BindingDB, COMET outperformed five other well-known algorithms, offering nearly an 80% probability of accurately identifying at least one true target within the top 15 predictions for a given compound. COMET also features a user-friendly web server, accessible freely at https://www.pdbbind-plus.org.cn/comet.
ARIC: An Activity Recognition Dataset in Classroom Surveillance Images
Oct 16, 2024



The application of activity recognition in the ``AI + Education" field is gaining increasing attention. However, current work mainly focuses on the recognition of activities in manually captured videos and a limited number of activity types, with little attention given to recognizing activities in surveillance images from real classrooms. Activity recognition in classroom surveillance images faces multiple challenges, such as class imbalance and high activity similarity. To address this gap, we constructed a novel multimodal dataset focused on classroom surveillance image activity recognition called ARIC (Activity Recognition In Classroom). The ARIC dataset has advantages of multiple perspectives, 32 activity categories, three modalities, and real-world classroom scenarios. In addition to the general activity recognition tasks, we also provide settings for continual learning and few-shot continual learning. We hope that the ARIC dataset can act as a facilitator for future analysis and research for open teaching scenarios. You can download preliminary data from https://ivipclab.github.io/publication_ARIC/ARIC.
Optimal Kernel Orchestration for Tensor Programs with Korch
Jun 13, 2024


Kernel orchestration is the task of mapping the computation defined in different operators of a deep neural network (DNN) to the execution of GPU kernels on modern hardware platforms. Prior approaches optimize kernel orchestration by greedily applying operator fusion, which fuses the computation of multiple operators into a single kernel, and miss a variety of optimization opportunities in kernel orchestration. This paper presents Korch, a tensor program optimizer that discovers optimal kernel orchestration strategies for tensor programs. Instead of directly fusing operators, Korch first applies operator fission to decompose tensor operators into a small set of basic tensor algebra primitives. This decomposition enables a diversity of fine-grained, inter-operator optimizations. Next, Korch optimizes kernel orchestration by formalizing it as a constrained optimization problem, leveraging an off-the-shelf binary linear programming solver to discover an optimal orchestration strategy, and generating an executable that can be directly deployed on modern GPU platforms. Evaluation on a variety of DNNs shows that Korch outperforms existing tensor program optimizers by up to 1.7x on V100 GPUs and up to 1.6x on A100 GPUs. Korch is publicly available at https://github.com/humuyan/Korch.
* Fix some typos in the ASPLOS version
PowerFusion: A Tensor Compiler with Explicit Data Movement Description and Instruction-level Graph IR
Jul 11, 2023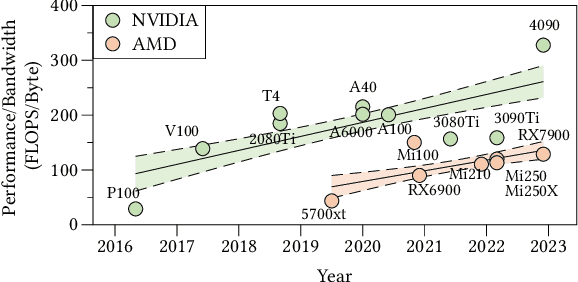
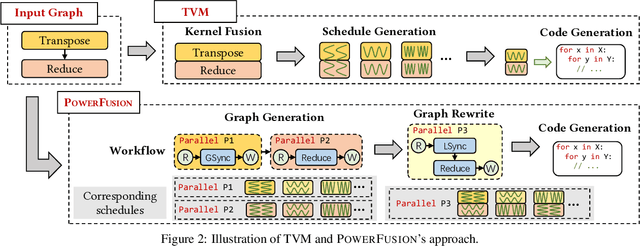
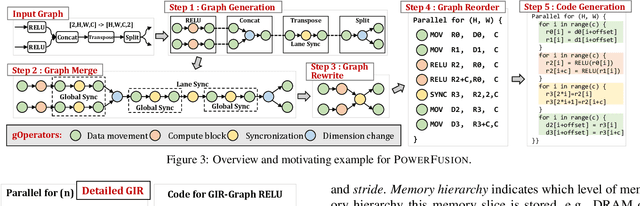
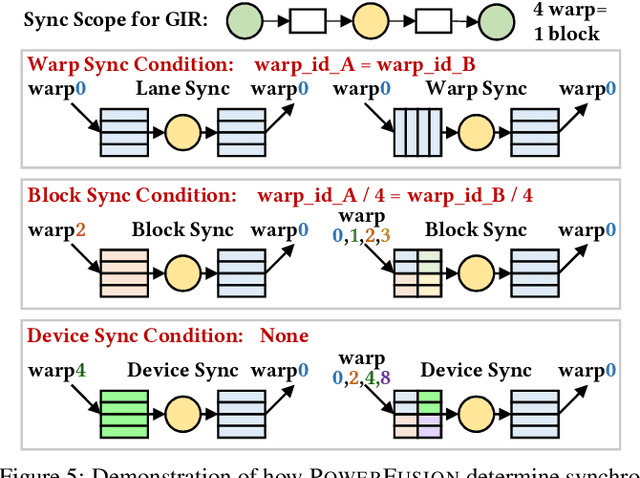
Deep neural networks (DNNs) are of critical use in different domains. To accelerate DNN computation, tensor compilers are proposed to generate efficient code on different domain-specific accelerators. Existing tensor compilers mainly focus on optimizing computation efficiency. However, memory access is becoming a key performance bottleneck because the computational performance of accelerators is increasing much faster than memory performance. The lack of direct description of memory access and data dependence in current tensor compilers' intermediate representation (IR) brings significant challenges to generate memory-efficient code. In this paper, we propose IntelliGen, a tensor compiler that can generate high-performance code for memory-intensive operators by considering both computation and data movement optimizations. IntelliGen represent a DNN program using GIR, which includes primitives indicating its computation, data movement, and parallel strategies. This information will be further composed as an instruction-level dataflow graph to perform holistic optimizations by searching different memory access patterns and computation operations, and generating memory-efficient code on different hardware. We evaluate IntelliGen on NVIDIA GPU, AMD GPU, and Cambricon MLU, showing speedup up to 1.97x, 2.93x, and 16.91x(1.28x, 1.23x, and 2.31x on average), respectively, compared to current most performant frameworks.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.