 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Kernel Orchestration for Tensor Programs with Korch
Jun 13, 2024


Kernel orchestration is the task of mapping the computation defined in different operators of a deep neural network (DNN) to the execution of GPU kernels on modern hardware platforms. Prior approaches optimize kernel orchestration by greedily applying operator fusion, which fuses the computation of multiple operators into a single kernel, and miss a variety of optimization opportunities in kernel orchestration. This paper presents Korch, a tensor program optimizer that discovers optimal kernel orchestration strategies for tensor programs. Instead of directly fusing operators, Korch first applies operator fission to decompose tensor operators into a small set of basic tensor algebra primitives. This decomposition enables a diversity of fine-grained, inter-operator optimizations. Next, Korch optimizes kernel orchestration by formalizing it as a constrained optimization problem, leveraging an off-the-shelf binary linear programming solver to discover an optimal orchestration strategy, and generating an executable that can be directly deployed on modern GPU platforms. Evaluation on a variety of DNNs shows that Korch outperforms existing tensor program optimizers by up to 1.7x on V100 GPUs and up to 1.6x on A100 GPUs. Korch is publicly available at https://github.com/humuyan/Korch.
* Fix some typos in the ASPLOS version
OLLIE: Derivation-based Tensor Program Optimizer
Aug 02, 2022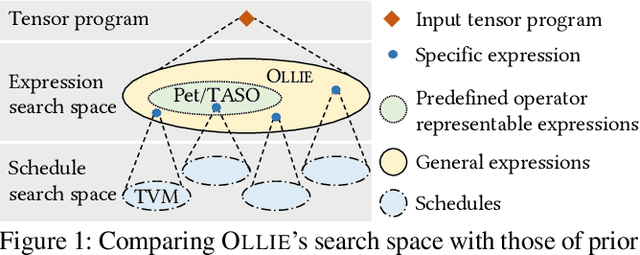
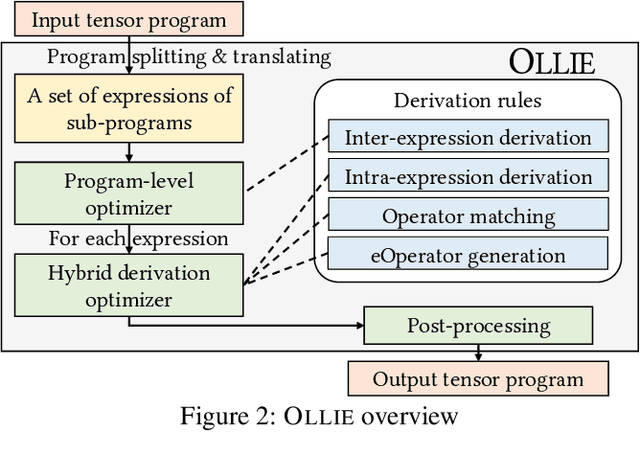
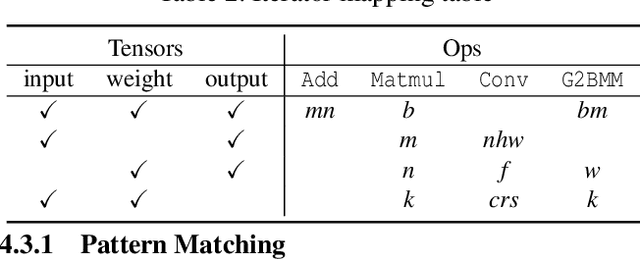
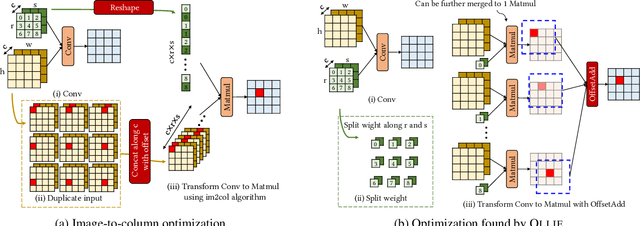
Boosting the runtime performance of deep neural networks (DNNs) is critical due to their wide adoption in real-world tasks. Existing approaches to optimizing the tensor algebra expression of a DNN only consider expressions representable by a fixed set of predefined operators, missing possible optimization opportunities between general expressions. We propose OLLIE, the first derivation-based tensor program optimizer. OLLIE optimizes tensor programs by leveraging transformations between general tensor algebra expressions, enabling a significantly larger expression search space that includes those supported by prior work as special cases. OLLIE uses a hybrid derivation-based optimizer that effectively combines explorative and guided derivations to quickly discover highly optimized expressions. Evaluation on seven DNNs shows that OLLIE can outperform existing optimizers by up to 2.73$\times$ (1.46$\times$ on average) on an A100 GPU and up to 2.68$\times$ (1.51$\times$) on a V100 GPU, respectively.