 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
Jan 12, 2026While Mixture-of-Experts (MoE) scales capacity via conditional computation, Transformers lack a native primitive for knowledge lookup, forcing them to inefficiently simulate retrieval through computation. To address this, we introduce conditional memory as a complementary sparsity axis, instantiated via Engram, a module that modernizes classic $N$-gram embedding for O(1) lookup. By formulating the Sparsity Allocation problem, we uncover a U-shaped scaling law that optimizes the trade-off between neural computation (MoE) and static memory (Engram). Guided by this law, we scale Engram to 27B parameters, achieving superior performance over a strictly iso-parameter and iso-FLOPs MoE baseline. Most notably, while the memory module is expected to aid knowledge retrieval (e.g., MMLU +3.4; CMMLU +4.0), we observe even larger gains in general reasoning (e.g., BBH +5.0; ARC-Challenge +3.7) and code/math domains~(HumanEval +3.0; MATH +2.4). Mechanistic analyses reveal that Engram relieves the backbone's early layers from static reconstruction, effectively deepening the network for complex reasoning. Furthermore, by delegating local dependencies to lookups, it frees up attention capacity for global context, substantially boosting long-context retrieval (e.g., Multi-Query NIAH: 84.2 to 97.0). Finally, Engram establishes infrastructure-aware efficiency: its deterministic addressing enables runtime prefetching from host memory, incurring negligible overhead. We envision conditional memory as an indispensable modeling primitive for next-generation sparse models.
PowerFusion: A Tensor Compiler with Explicit Data Movement Description and Instruction-level Graph IR
Jul 11, 2023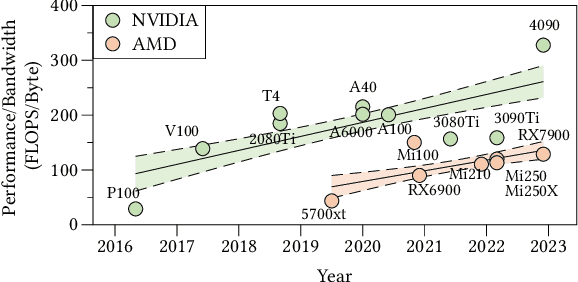
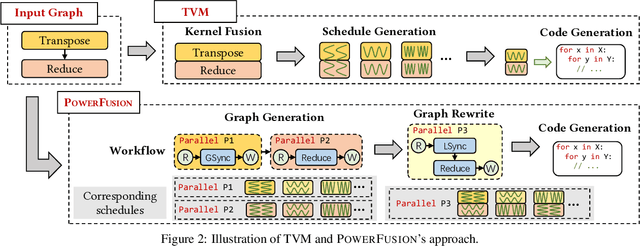
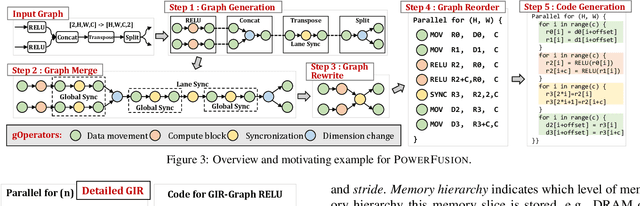
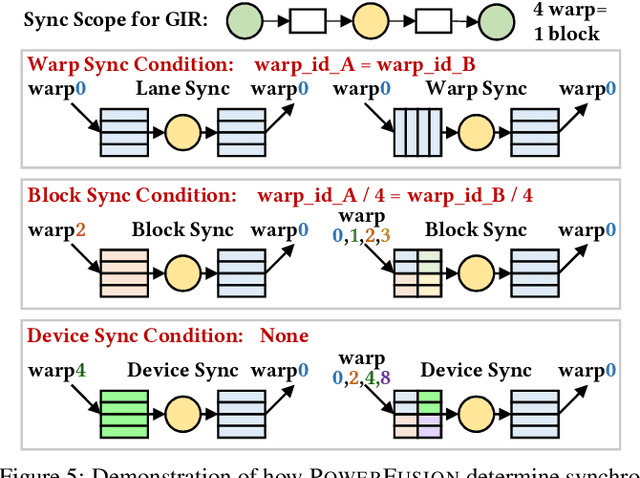
Deep neural networks (DNNs) are of critical use in different domains. To accelerate DNN computation, tensor compilers are proposed to generate efficient code on different domain-specific accelerators. Existing tensor compilers mainly focus on optimizing computation efficiency. However, memory access is becoming a key performance bottleneck because the computational performance of accelerators is increasing much faster than memory performance. The lack of direct description of memory access and data dependence in current tensor compilers' intermediate representation (IR) brings significant challenges to generate memory-efficient code. In this paper, we propose IntelliGen, a tensor compiler that can generate high-performance code for memory-intensive operators by considering both computation and data movement optimizations. IntelliGen represent a DNN program using GIR, which includes primitives indicating its computation, data movement, and parallel strategies. This information will be further composed as an instruction-level dataflow graph to perform holistic optimizations by searching different memory access patterns and computation operations, and generating memory-efficient code on different hardware. We evaluate IntelliGen on NVIDIA GPU, AMD GPU, and Cambricon MLU, showing speedup up to 1.97x, 2.93x, and 16.91x(1.28x, 1.23x, and 2.31x on average), respectively, compared to current most performant frameworks.
ReFresh: Reducing Memory Access from Exploiting Stable Historical Embeddings for Graph Neural Network Training
Jan 19, 2023


A key performance bottleneck when training graph neural network (GNN) models on large, real-world graphs is loading node features onto a GPU. Due to limited GPU memory, expensive data movement is necessary to facilitate the storage of these features on alternative devices with slower access (e.g. CPU memory). Moreover, the irregularity of graph structures contributes to poor data locality which further exacerbates the problem. Consequently, existing frameworks capable of efficiently training large GNN models usually incur a significant accuracy degradation because of the inevitable shortcuts involved. To address these limitations, we instead propose ReFresh, a general-purpose GNN mini-batch training framework that leverages a historical cache for storing and reusing GNN node embeddings instead of re-computing them through fetching raw features at every iteration. Critical to its success, the corresponding cache policy is designed, using a combination of gradient-based and staleness criteria, to selectively screen those embeddings which are relatively stable and can be cached, from those that need to be re-computed to reduce estimation errors and subsequent downstream accuracy loss. When paired with complementary system enhancements to support this selective historical cache, ReFresh is able to accelerate the training speed on large graph datasets such as ogbn-papers100M and MAG240M by 4.6x up to 23.6x and reduce the memory access by 64.5% (85.7% higher than a raw feature cache), with less than 1% influence on test accuracy.
OLLIE: Derivation-based Tensor Program Optimizer
Aug 02, 2022
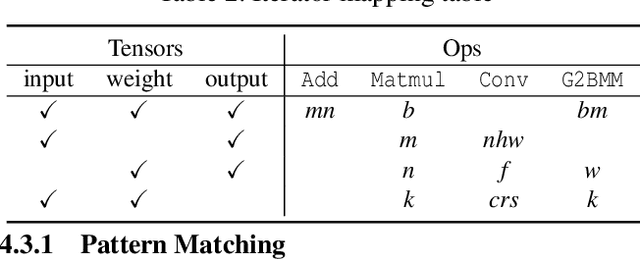
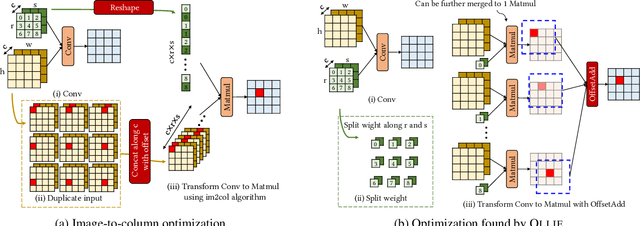
Boosting the runtime performance of deep neural networks (DNNs) is critical due to their wide adoption in real-world tasks. Existing approaches to optimizing the tensor algebra expression of a DNN only consider expressions representable by a fixed set of predefined operators, missing possible optimization opportunities between general expressions. We propose OLLIE, the first derivation-based tensor program optimizer. OLLIE optimizes tensor programs by leveraging transformations between general tensor algebra expressions, enabling a significantly larger expression search space that includes those supported by prior work as special cases. OLLIE uses a hybrid derivation-based optimizer that effectively combines explorative and guided derivations to quickly discover highly optimized expressions. Evaluation on seven DNNs shows that OLLIE can outperform existing optimizers by up to 2.73$\times$ (1.46$\times$ on average) on an A100 GPU and up to 2.68$\times$ (1.51$\times$) on a V100 GPU, respectively.