 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Federated Learning from Partial Decryption Verifiable Threshold Multi-Client Functional Encryption
Nov 17, 2025



In federated learning, multiple parties can cooperate to train the model without directly exchanging their own private data, but the gradient leakage problem still threatens the privacy security and model integrity. Although the existing scheme uses threshold cryptography to mitigate the inference attack, it can not guarantee the verifiability of the aggregation results, making the system vulnerable to the threat of poisoning attack. We construct a partial decryption verifiable threshold multi client function encryption scheme, and apply it to Federated learning to implement the federated learning verifiable threshold security aggregation protocol (VTSAFL). VTSAFL empowers clients to verify aggregation results, concurrently minimizing both computational and communication overhead. The size of the functional key and partial decryption results of the scheme are constant, which provides efficiency guarantee for large-scale deployment. The experimental results on MNIST dataset show that vtsafl can achieve the same accuracy as the existing scheme, while reducing the total training time by more than 40%, and reducing the communication overhead by up to 50%. This efficiency is critical for overcoming the resource constraints inherent in Internet of Things (IoT) devices.
Synthesize, Retrieve, and Propagate: A Unified Predictive Modeling Framework for Relational Databases
Aug 10, 2025Relational databases (RDBs) have become the industry standard for storing massive and heterogeneous data. However, despite the widespread use of RDBs across various fields, the inherent structure of relational databases hinders their ability to benefit from flourishing deep learning methods. Previous research has primarily focused on exploiting the unary dependency among multiple tables in a relational database using the primary key - foreign key relationships, either joining multiple tables into a single table or constructing a graph among them, which leaves the implicit composite relations among different tables and a substantial potential of improvement for predictive modeling unexplored. In this paper, we propose SRP, a unified predictive modeling framework that synthesizes features using the unary dependency, retrieves related information to capture the composite dependency, and propagates messages across a constructed graph to learn adjacent patterns for prediction on relation databases. By introducing a new retrieval mechanism into RDB, SRP is designed to fully capture both the unary and the composite dependencies within a relational database, thereby enhancing the receptive field of tabular data prediction. In addition, we conduct a comprehensive analysis on the components of SRP, offering a nuanced understanding of model behaviors and practical guidelines for future applications. Extensive experiments on five real-world datasets demonstrate the effectiveness of SRP and its potential applicability in industrial scenarios. The code is released at https://github.com/NingLi670/SRP.
Griffin: Towards a Graph-Centric Relational Database Foundation Model
May 08, 2025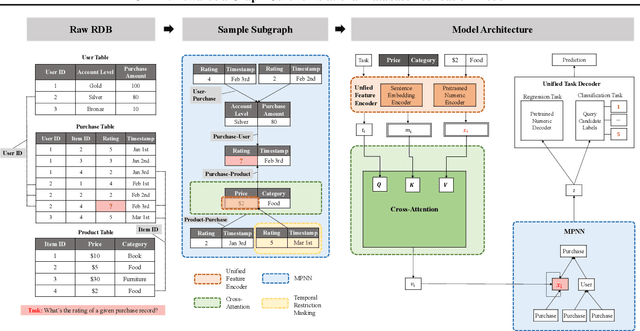
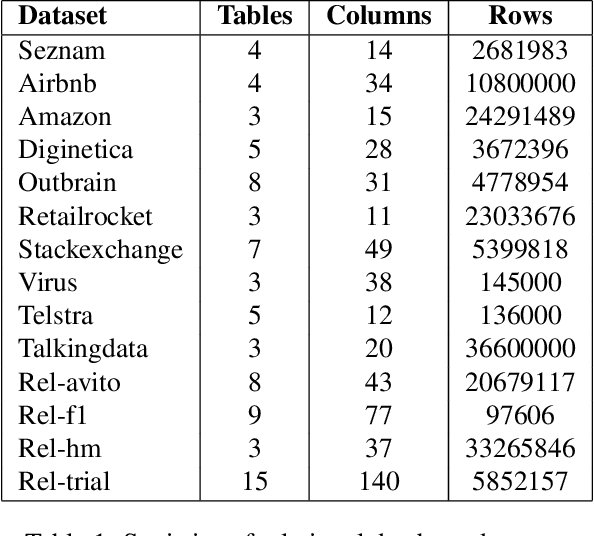
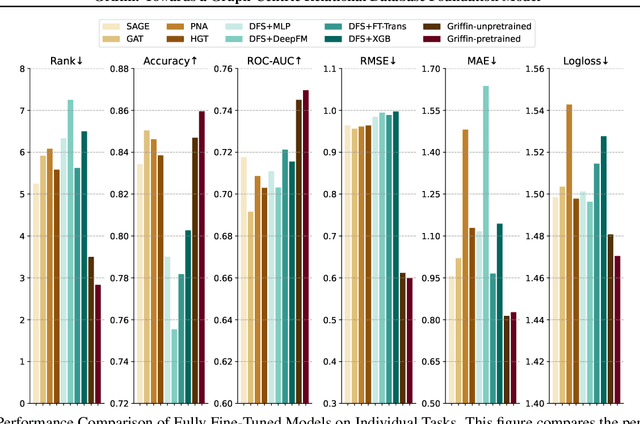

We introduce Griffin, the first foundation model attemptation designed specifically for Relational Databases (RDBs). Unlike previous smaller models focused on single RDB tasks, Griffin unifies the data encoder and task decoder to handle diverse tasks. Additionally, we enhance the architecture by incorporating a cross-attention module and a novel aggregator. Griffin utilizes pretraining on both single-table and RDB datasets, employing advanced encoders for categorical, numerical, and metadata features, along with innovative components such as cross-attention modules and enhanced message-passing neural networks (MPNNs) to capture the complexities of relational data. Evaluated on large-scale, heterogeneous, and temporal graphs extracted from RDBs across various domains (spanning over 150 million nodes), Griffin demonstrates superior or comparable performance to individually trained models, excels in low-data scenarios, and shows strong transferability with similarity and diversity in pretraining across new datasets and tasks, highlighting its potential as a universally applicable foundation model for RDBs. Code available at https://github.com/yanxwb/Griffin.
DF-GNN: Dynamic Fusion Framework for Attention Graph Neural Networks on GPUs
Nov 25, 2024



Attention Graph Neural Networks (AT-GNNs), such as GAT and Graph Transformer, have demonstrated superior performance compared to other GNNs. However, existing GNN systems struggle to efficiently train AT-GNNs on GPUs due to their intricate computation patterns. The execution of AT-GNN operations without kernel fusion results in heavy data movement and significant kernel launch overhead, while fixed thread scheduling in existing GNN kernel fusion strategies leads to sub-optimal performance, redundant computation and unbalanced workload. To address these challenges, we propose a dynamic kernel fusion framework, DF-GNN, for the AT-GNN family. DF-GNN introduces a dynamic bi-level thread scheduling strategy, enabling flexible adjustments to thread scheduling while retaining the benefits of shared memory within the fused kernel. DF-GNN tailors specific thread scheduling for operations in AT-GNNs and considers the performance bottleneck shift caused by the presence of super nodes. Additionally, DF-GNN is integrated with the PyTorch framework for high programmability. Evaluations across diverse GNN models and multiple datasets reveal that DF-GNN surpasses existing GNN kernel optimization works like cuGraph and dgNN, with speedups up to $7.0\times$ over the state-of-the-art non-fusion DGL sparse library. Moreover, it achieves an average speedup of $2.16\times$ in end-to-end training compared to the popular GNN computing framework DGL.
ELF-Gym: Evaluating Large Language Models Generated Features for Tabular Prediction
Oct 13, 2024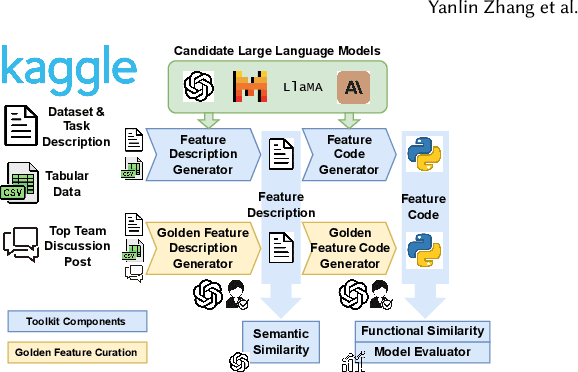
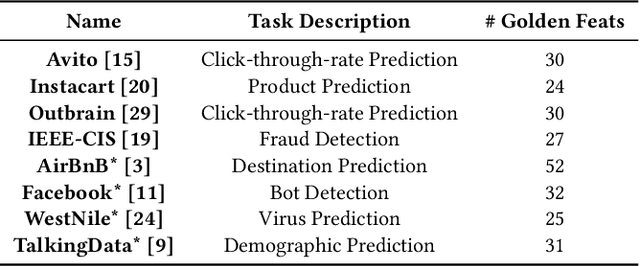
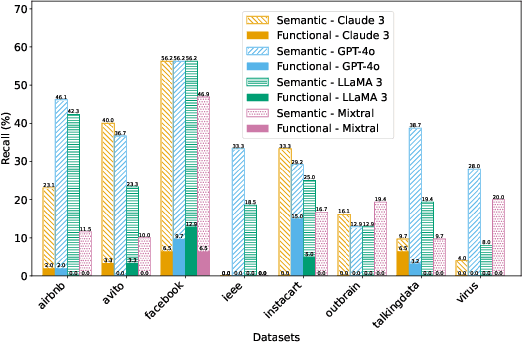
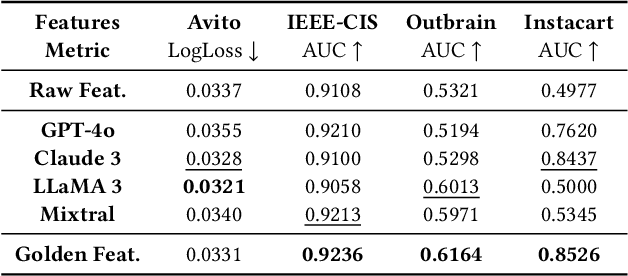
Crafting effective features is a crucial yet labor-intensive and domain-specific task within machine learning pipelines. Fortunately, recent advancements in Large Language Models (LLMs) have shown promise in automating various data science tasks, including feature engineering. But despite this potential, evaluations thus far are primarily based on the end performance of a complete ML pipeline, providing limited insight into precisely how LLMs behave relative to human experts in feature engineering. To address this gap, we propose ELF-Gym, a framework for Evaluating LLM-generated Features. We curated a new dataset from historical Kaggle competitions, including 251 "golden" features used by top-performing teams. ELF-Gym then quantitatively evaluates LLM-generated features by measuring their impact on downstream model performance as well as their alignment with expert-crafted features through semantic and functional similarity assessments. This approach provides a more comprehensive evaluation of disparities between LLMs and human experts, while offering valuable insights into specific areas where LLMs may have room for improvement. For example, using ELF-Gym we empirically demonstrate that, in the best-case scenario, LLMs can semantically capture approximately 56% of the golden features, but at the more demanding implementation level this overlap drops to 13%. Moreover, in other cases LLMs may fail completely, particularly on datasets that require complex features, indicating broad potential pathways for improvement.
Deep progressive reinforcement learning-based flexible resource scheduling framework for IRS and UAV-assisted MEC system
Aug 02, 2024



The intelligent reflection surface (IRS) and unmanned aerial vehicle (UAV)-assisted mobile edge computing (MEC) system is widely used in temporary and emergency scenarios. Our goal is to minimize the energy consumption of the MEC system by jointly optimizing UAV locations, IRS phase shift, task offloading, and resource allocation with a variable number of UAVs. To this end, we propose a Flexible REsource Scheduling (FRES) framework by employing a novel deep progressive reinforcement learning which includes the following innovations: Firstly, a novel multi-task agent is presented to deal with the mixed integer nonlinear programming (MINLP) problem. The multi-task agent has two output heads designed for different tasks, in which a classified head is employed to make offloading decisions with integer variables while a fitting head is applied to solve resource allocation with continuous variables. Secondly, a progressive scheduler is introduced to adapt the agent to the varying number of UAVs by progressively adjusting a part of neurons in the agent. This structure can naturally accumulate experiences and be immune to catastrophic forgetting. Finally, a light taboo search (LTS) is introduced to enhance the global search of the FRES. The numerical results demonstrate the superiority of the FRES framework which can make real-time and optimal resource scheduling even in dynamic MEC systems.
* 13 pages, 10 figures
DiskGNN: Bridging I/O Efficiency and Model Accuracy for Out-of-Core GNN Training
May 08, 2024



Graph neural networks (GNNs) are machine learning models specialized for graph data and widely used in many applications. To train GNNs on large graphs that exceed CPU memory, several systems store data on disk and conduct out-of-core processing. However, these systems suffer from either read amplification when reading node features that are usually smaller than a disk page or degraded model accuracy by treating the graph as disconnected partitions. To close this gap, we build a system called DiskGNN, which achieves high I/O efficiency and thus fast training without hurting model accuracy. The key technique used by DiskGNN is offline sampling, which helps decouple graph sampling from model computation. In particular, by conducting graph sampling beforehand, DiskGNN acquires the node features that will be accessed by model computation, and such information is utilized to pack the target node features contiguously on disk to avoid read amplification. Besides, \name{} also adopts designs including four-level feature store to fully utilize the memory hierarchy to cache node features and reduce disk access, batched packing to accelerate the feature packing process, and pipelined training to overlap disk access with other operations. We compare DiskGNN with Ginex and MariusGNN, which are state-of-the-art systems for out-of-core GNN training. The results show that DiskGNN can speed up the baselines by over 8x while matching their best model accuracy.
4DBInfer: A 4D Benchmarking Toolbox for Graph-Centric Predictive Modeling on Relational DBs
Apr 28, 2024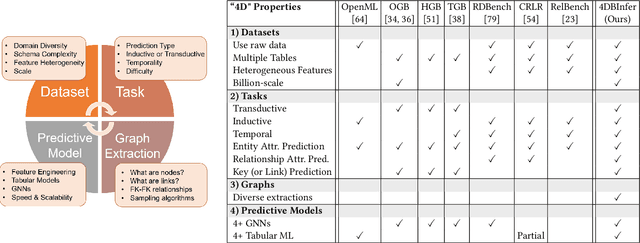
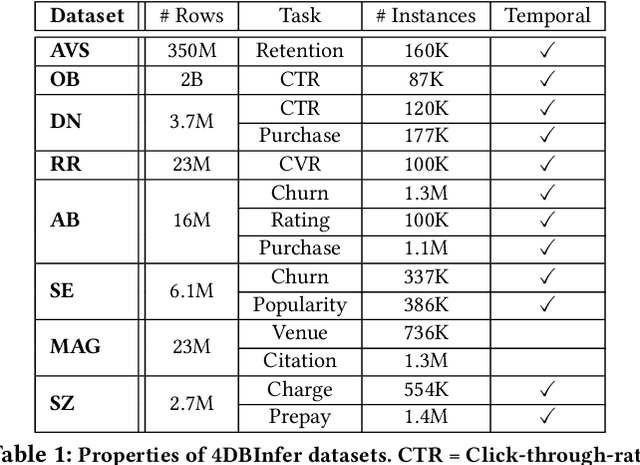
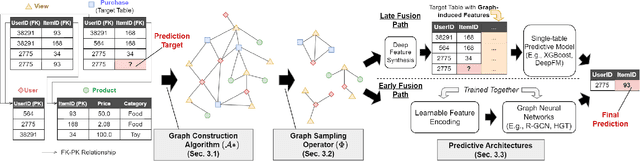
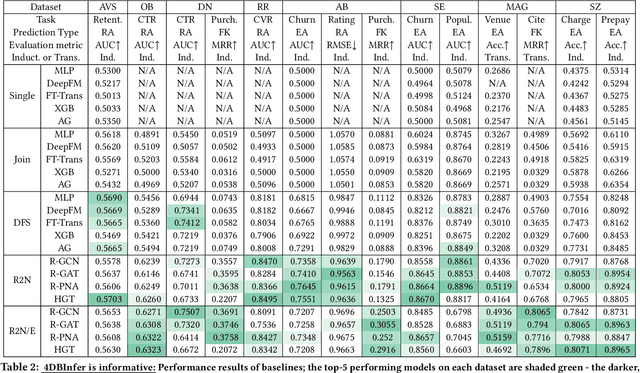
Although RDBs store vast amounts of rich, informative data spread across interconnected tables, the progress of predictive machine learning models as applied to such tasks arguably falls well behind advances in other domains such as computer vision or natural language processing. This deficit stems, at least in part, from the lack of established/public RDB benchmarks as needed for training and evaluation purposes. As a result, related model development thus far often defaults to tabular approaches trained on ubiquitous single-table benchmarks, or on the relational side, graph-based alternatives such as GNNs applied to a completely different set of graph datasets devoid of tabular characteristics. To more precisely target RDBs lying at the nexus of these two complementary regimes, we explore a broad class of baseline models predicated on: (i) converting multi-table datasets into graphs using various strategies equipped with efficient subsampling, while preserving tabular characteristics; and (ii) trainable models with well-matched inductive biases that output predictions based on these input subgraphs. Then, to address the dearth of suitable public benchmarks and reduce siloed comparisons, we assemble a diverse collection of (i) large-scale RDB datasets and (ii) coincident predictive tasks. From a delivery standpoint, we operationalize the above four dimensions (4D) of exploration within a unified, scalable open-source toolbox called 4DBInfer. We conclude by presenting evaluations using 4DBInfer, the results of which highlight the importance of considering each such dimension in the design of RDB predictive models, as well as the limitations of more naive approaches such as simply joining adjacent tables. Our source code is released at https://github.com/awslabs/multi-table-benchmark .
BloomGML: Graph Machine Learning through the Lens of Bilevel Optimization
Mar 07, 2024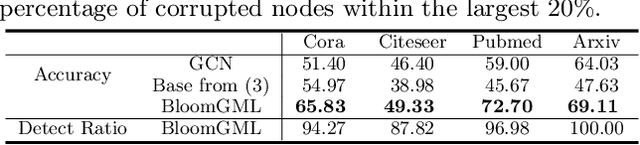


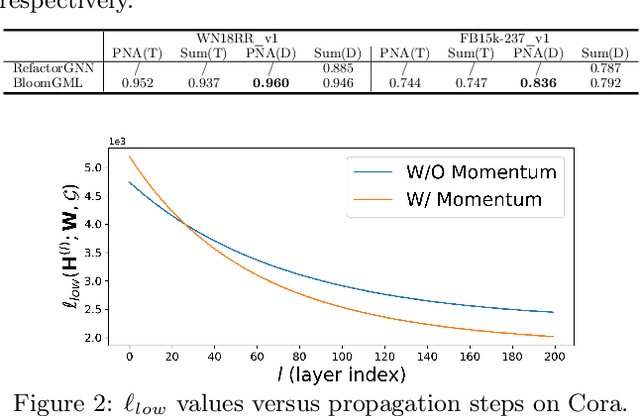
Bilevel optimization refers to scenarios whereby the optimal solution of a lower-level energy function serves as input features to an upper-level objective of interest. These optimal features typically depend on tunable parameters of the lower-level energy in such a way that the entire bilevel pipeline can be trained end-to-end. Although not generally presented as such, this paper demonstrates how a variety of graph learning techniques can be recast as special cases of bilevel optimization or simplifications thereof. In brief, building on prior work we first derive a more flexible class of energy functions that, when paired with various descent steps (e.g., gradient descent, proximal methods, momentum, etc.), form graph neural network (GNN) message-passing layers; critically, we also carefully unpack where any residual approximation error lies with respect to the underlying constituent message-passing functions. We then probe several simplifications of this framework to derive close connections with non-GNN-based graph learning approaches, including knowledge graph embeddings, various forms of label propagation, and efficient graph-regularized MLP models. And finally, we present supporting empirical results that demonstrate the versatility of the proposed bilevel lens, which we refer to as BloomGML, referencing that BiLevel Optimization Offers More Graph Machine Learning. Our code is available at https://github.com/amberyzheng/BloomGML. Let graph ML bloom.
GNNFlow: A Distributed Framework for Continuous Temporal GNN Learning on Dynamic Graphs
Nov 30, 2023



Graph Neural Networks (GNNs) play a crucial role in various fields. However, most existing deep graph learning frameworks assume pre-stored static graphs and do not support training on graph streams. In contrast, many real-world graphs are dynamic and contain time domain information. We introduce GNNFlow, a distributed framework that enables efficient continuous temporal graph representation learning on dynamic graphs on multi-GPU machines. GNNFlow introduces an adaptive time-indexed block-based data structure that effectively balances memory usage with graph update and sampling operation efficiency. It features a hybrid GPU-CPU graph data placement for rapid GPU-based temporal neighborhood sampling and kernel optimizations for enhanced sampling processes. A dynamic GPU cache for node and edge features is developed to maximize cache hit rates through reuse and restoration strategies. GNNFlow supports distributed training across multiple machines with static scheduling to ensure load balance. We implement GNNFlow based on DGL and PyTorch. Our experimental results show that GNNFlow provides up to 21.1x faster continuous learning than existing systems.