 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJano: Adaptive Diffusion Generation with Early-stage Convergence Awareness
Feb 28, 2026Diffusion models have achieved remarkable success in generative AI, yet their computational efficiency remains a significant challenge, particularly for Diffusion Transformers (DiTs) requiring intensive full-attention computation. While existing acceleration approaches focus on content-agnostic uniform optimization strategies, we observe that different regions in generated content exhibit heterogeneous convergence patterns during the denoising process. We present Jano, a training-free framework that leverages this insight for efficient region-aware generation. Jano introduces an early-stage complexity recognition algorithm that accurately identifies regional convergence requirements within initial denoising steps, coupled with an adaptive token scheduling runtime that optimizes computational resource allocation. Through comprehensive evaluation on state-of-the-art models, Jano achieves substantial acceleration (average 2.0 times speedup, up to 2.4 times) while preserving generation quality. Our work challenges conventional uniform processing assumptions and provides a practical solution for accelerating large-scale content generation. The source code of our implementation is available at https://github.com/chen-yy20/Jano.
FlowPrefill: Decoupling Preemption from Prefill Scheduling Granularity to Mitigate Head-of-Line Blocking in LLM Serving
Feb 18, 2026The growing demand for large language models (LLMs) requires serving systems to handle many concurrent requests with diverse service level objectives (SLOs). This exacerbates head-of-line (HoL) blocking during the compute-intensive prefill phase, where long-running requests monopolize resources and delay higher-priority ones, leading to widespread time-to-first-token (TTFT) SLO violations. While chunked prefill enables interruptibility, it introduces an inherent trade-off between responsiveness and throughput: reducing chunk size improves response latency but degrades computational efficiency, whereas increasing chunk size maximizes throughput but exacerbates blocking. This necessitates an adaptive preemption mechanism. However, dynamically balancing execution granularity against scheduling overheads remains a key challenge. In this paper, we propose FlowPrefill, a TTFT-goodput-optimized serving system that resolves this conflict by decoupling preemption granularity from scheduling frequency. To achieve adaptive prefill scheduling, FlowPrefill introduces two key innovations: 1) Operator-Level Preemption, which leverages operator boundaries to enable fine-grained execution interruption without the efficiency loss associated with fixed small chunking; and 2) Event-Driven Scheduling, which triggers scheduling decisions only upon request arrival or completion events, thereby supporting efficient preemption responsiveness while minimizing control-plane overhead. Evaluation on real-world production traces shows that FlowPrefill improves maximum goodput by up to 5.6$\times$ compared to state-of-the-art systems while satisfying heterogeneous SLOs.
Lethe: Layer- and Time-Adaptive KV Cache Pruning for Reasoning-Intensive LLM Serving
Nov 12, 2025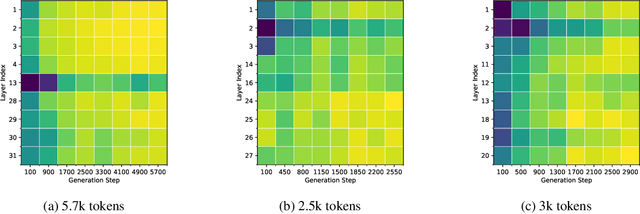
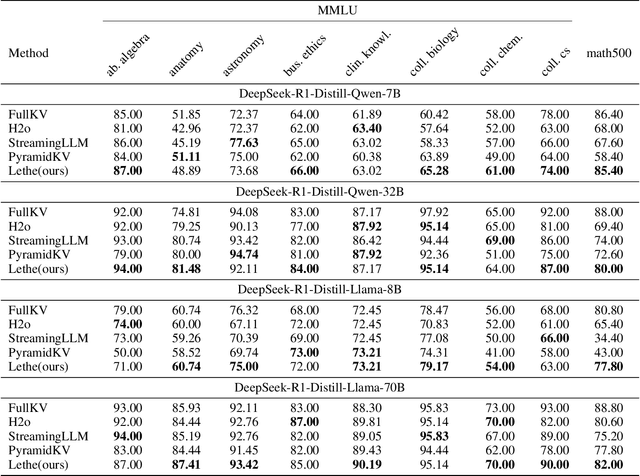
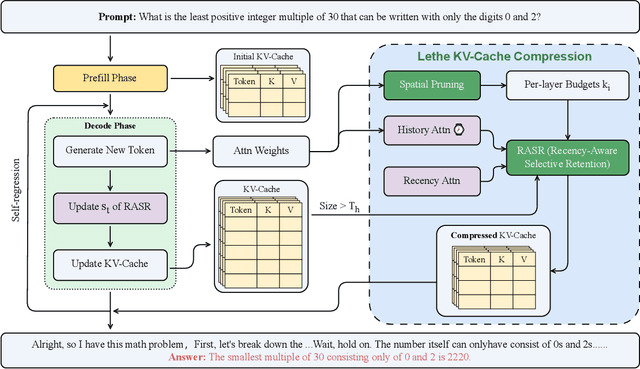

Generative reasoning with large language models (LLMs) often involves long decoding sequences, leading to substantial memory and latency overheads from accumulating key-value (KV) caches. While existing KV compression methods primarily focus on reducing prefill memory from long input sequences, they fall short in addressing the dynamic and layer-sensitive nature of long-form generation, which is central to reasoning tasks. We propose Lethe, a dynamic KV cache management framework that introduces adaptivity along both the spatial and temporal dimensions of decoding. Along the spatial dimension, Lethe performs layerwise sparsity-aware allocation, assigning token pruning budgets to each transformer layer based on estimated attention redundancy. Along the temporal dimension, Lethe conducts multi-round token pruning during generation, driven by a Recency-Aware Selective Retention} (RASR) mechanism. RASR extends traditional recency-based heuristics by also considering token relevance derived from evolving attention patterns, enabling informed decisions about which tokens to retain or evict. Empirical results demonstrate that Lethe achieves a favorable balance between efficiency and generation quality across diverse models and tasks, increases throughput by up to 2.56x.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
SpecRouter: Adaptive Routing for Multi-Level Speculative Decoding in Large Language Models
May 12, 2025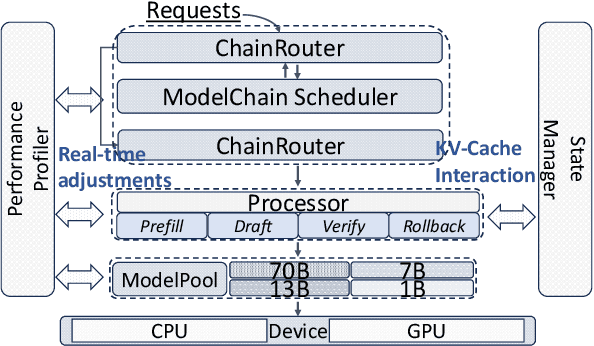
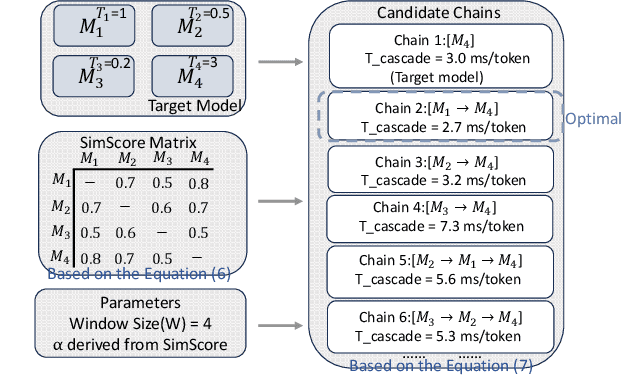
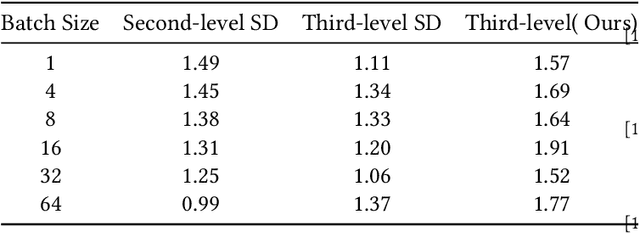
Large Language Models (LLMs) present a critical trade-off between inference quality and computational cost: larger models offer superior capabilities but incur significant latency, while smaller models are faster but less powerful. Existing serving strategies often employ fixed model scales or static two-stage speculative decoding, failing to dynamically adapt to the varying complexities of user requests or fluctuations in system performance. This paper introduces \systemname{}, a novel framework that reimagines LLM inference as an adaptive routing problem solved through multi-level speculative decoding. \systemname{} dynamically constructs and optimizes inference "paths" (chains of models) based on real-time feedback, addressing the limitations of static approaches. Our contributions are threefold: (1) An \textbf{adaptive model chain scheduling} mechanism that leverages performance profiling (execution times) and predictive similarity metrics (derived from token distribution divergence) to continuously select the optimal sequence of draft and verifier models, minimizing predicted latency per generated token. (2) A \textbf{multi-level collaborative verification} framework where intermediate models within the selected chain can validate speculative tokens, reducing the verification burden on the final, most powerful target model. (3) A \textbf{synchronized state management} system providing efficient, consistent KV cache handling across heterogeneous models in the chain, including precise, low-overhead rollbacks tailored for asynchronous batch processing inherent in multi-level speculation. Preliminary experiments demonstrate the validity of our method.
GS-Cache: A GS-Cache Inference Framework for Large-scale Gaussian Splatting Models
Feb 20, 2025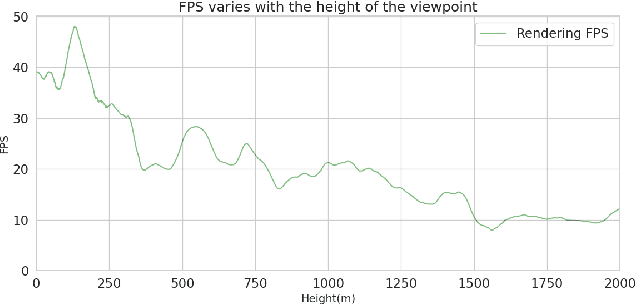
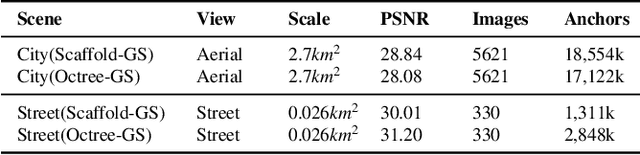
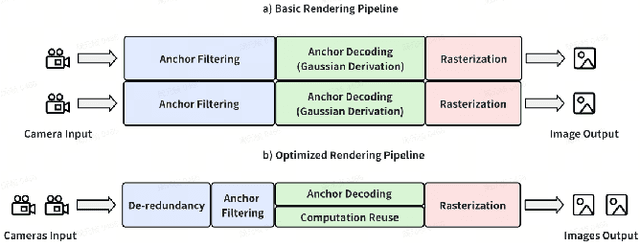
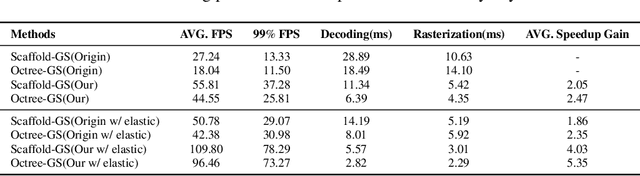
Rendering large-scale 3D Gaussian Splatting (3DGS) model faces significant challenges in achieving real-time, high-fidelity performance on consumer-grade devices. Fully realizing the potential of 3DGS in applications such as virtual reality (VR) requires addressing critical system-level challenges to support real-time, immersive experiences. We propose GS-Cache, an end-to-end framework that seamlessly integrates 3DGS's advanced representation with a highly optimized rendering system. GS-Cache introduces a cache-centric pipeline to eliminate redundant computations, an efficiency-aware scheduler for elastic multi-GPU rendering, and optimized CUDA kernels to overcome computational bottlenecks. This synergy between 3DGS and system design enables GS-Cache to achieve up to 5.35x performance improvement, 35% latency reduction, and 42% lower GPU memory usage, supporting 2K binocular rendering at over 120 FPS with high visual quality. By bridging the gap between 3DGS's representation power and the demands of VR systems, GS-Cache establishes a scalable and efficient framework for real-time neural rendering in immersive environments.
Optimal Kernel Orchestration for Tensor Programs with Korch
Jun 13, 2024


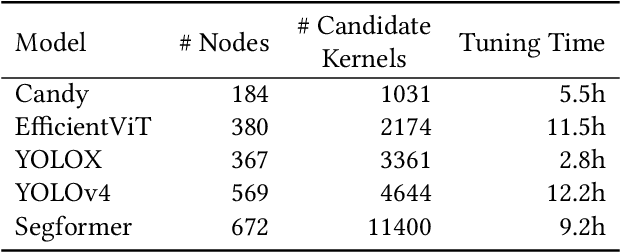
Kernel orchestration is the task of mapping the computation defined in different operators of a deep neural network (DNN) to the execution of GPU kernels on modern hardware platforms. Prior approaches optimize kernel orchestration by greedily applying operator fusion, which fuses the computation of multiple operators into a single kernel, and miss a variety of optimization opportunities in kernel orchestration. This paper presents Korch, a tensor program optimizer that discovers optimal kernel orchestration strategies for tensor programs. Instead of directly fusing operators, Korch first applies operator fission to decompose tensor operators into a small set of basic tensor algebra primitives. This decomposition enables a diversity of fine-grained, inter-operator optimizations. Next, Korch optimizes kernel orchestration by formalizing it as a constrained optimization problem, leveraging an off-the-shelf binary linear programming solver to discover an optimal orchestration strategy, and generating an executable that can be directly deployed on modern GPU platforms. Evaluation on a variety of DNNs shows that Korch outperforms existing tensor program optimizers by up to 1.7x on V100 GPUs and up to 1.6x on A100 GPUs. Korch is publicly available at https://github.com/humuyan/Korch.
* Fix some typos in the ASPLOS version
PowerFusion: A Tensor Compiler with Explicit Data Movement Description and Instruction-level Graph IR
Jul 11, 2023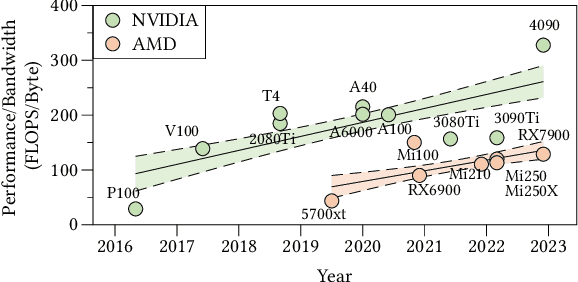
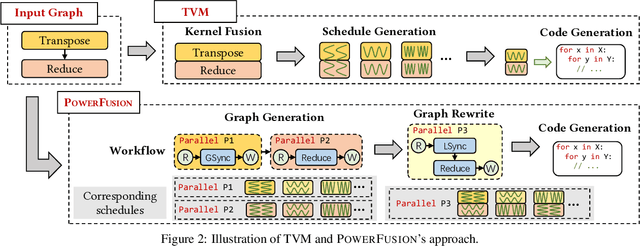
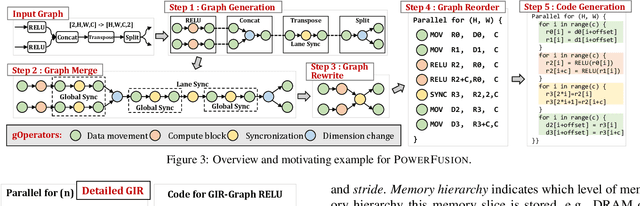
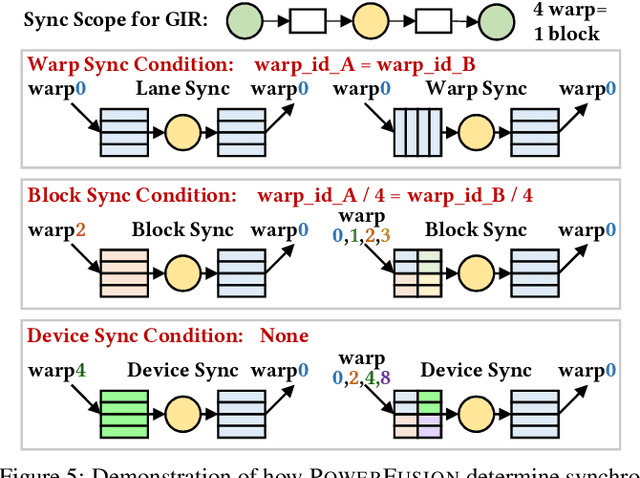
Deep neural networks (DNNs) are of critical use in different domains. To accelerate DNN computation, tensor compilers are proposed to generate efficient code on different domain-specific accelerators. Existing tensor compilers mainly focus on optimizing computation efficiency. However, memory access is becoming a key performance bottleneck because the computational performance of accelerators is increasing much faster than memory performance. The lack of direct description of memory access and data dependence in current tensor compilers' intermediate representation (IR) brings significant challenges to generate memory-efficient code. In this paper, we propose IntelliGen, a tensor compiler that can generate high-performance code for memory-intensive operators by considering both computation and data movement optimizations. IntelliGen represent a DNN program using GIR, which includes primitives indicating its computation, data movement, and parallel strategies. This information will be further composed as an instruction-level dataflow graph to perform holistic optimizations by searching different memory access patterns and computation operations, and generating memory-efficient code on different hardware. We evaluate IntelliGen on NVIDIA GPU, AMD GPU, and Cambricon MLU, showing speedup up to 1.97x, 2.93x, and 16.91x(1.28x, 1.23x, and 2.31x on average), respectively, compared to current most performant frameworks.
ReFresh: Reducing Memory Access from Exploiting Stable Historical Embeddings for Graph Neural Network Training
Jan 19, 2023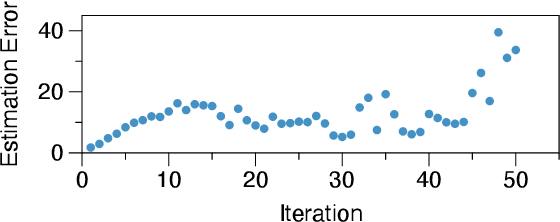


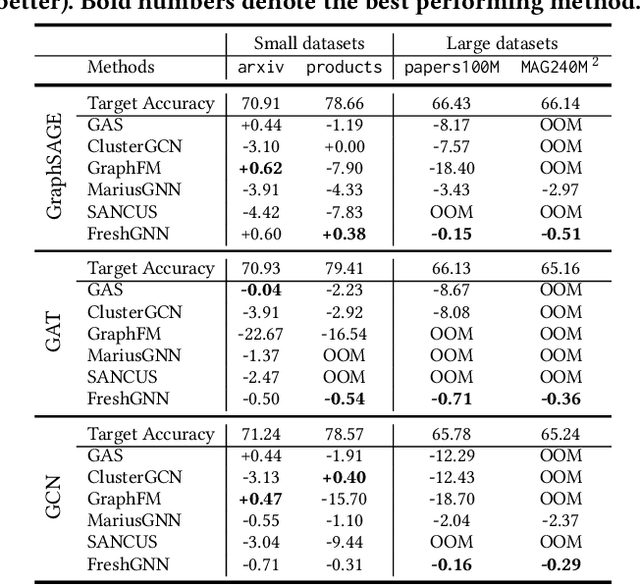
A key performance bottleneck when training graph neural network (GNN) models on large, real-world graphs is loading node features onto a GPU. Due to limited GPU memory, expensive data movement is necessary to facilitate the storage of these features on alternative devices with slower access (e.g. CPU memory). Moreover, the irregularity of graph structures contributes to poor data locality which further exacerbates the problem. Consequently, existing frameworks capable of efficiently training large GNN models usually incur a significant accuracy degradation because of the inevitable shortcuts involved. To address these limitations, we instead propose ReFresh, a general-purpose GNN mini-batch training framework that leverages a historical cache for storing and reusing GNN node embeddings instead of re-computing them through fetching raw features at every iteration. Critical to its success, the corresponding cache policy is designed, using a combination of gradient-based and staleness criteria, to selectively screen those embeddings which are relatively stable and can be cached, from those that need to be re-computed to reduce estimation errors and subsequent downstream accuracy loss. When paired with complementary system enhancements to support this selective historical cache, ReFresh is able to accelerate the training speed on large graph datasets such as ogbn-papers100M and MAG240M by 4.6x up to 23.6x and reduce the memory access by 64.5% (85.7% higher than a raw feature cache), with less than 1% influence on test accuracy.
GLM-130B: An Open Bilingual Pre-trained Model
Oct 05, 2022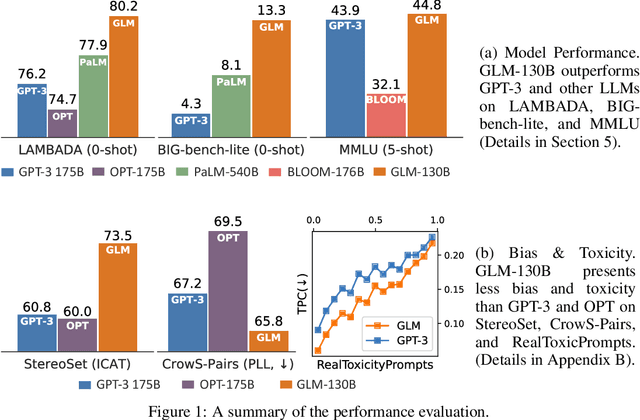
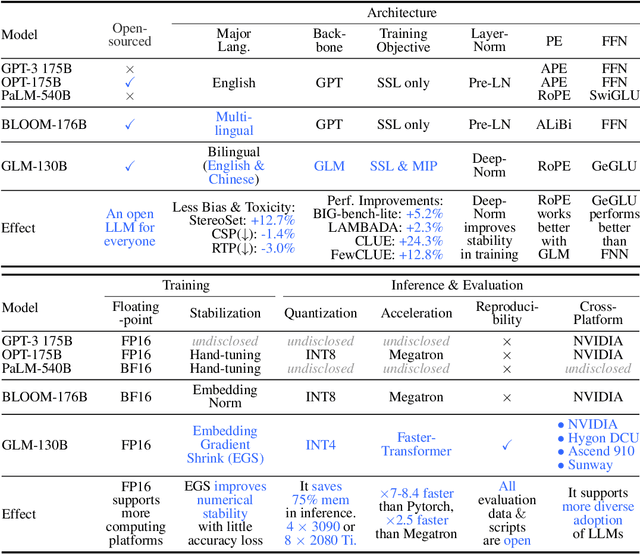

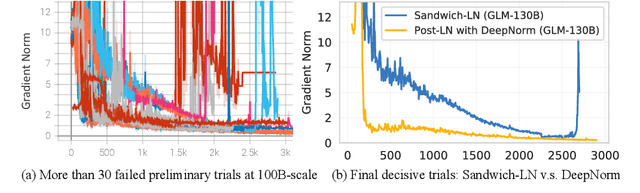
We introduce GLM-130B, a bilingual (English and Chinese) pre-trained language model with 130 billion parameters. It is an attempt to open-source a 100B-scale model at least as good as GPT-3 and unveil how models of such a scale can be successfully pre-trained. Over the course of this effort, we face numerous unexpected technical and engineering challenges, particularly on loss spikes and disconvergence. In this paper, we introduce the training process of GLM-130B including its design choices, training strategies for both efficiency and stability, and engineering efforts. The resultant GLM-130B model offers significant outperformance over GPT-3 175B on a wide range of popular English benchmarks while the performance advantage is not observed in OPT-175B and BLOOM-176B. It also consistently and significantly outperforms ERNIE TITAN 3.0 260B -- the largest Chinese language model -- across related benchmarks. Finally, we leverage a unique scaling property of GLM-130B to reach INT4 quantization, without quantization aware training and with almost no performance loss, making it the first among 100B-scale models. More importantly, the property allows its effective inference on 4$\times$RTX 3090 (24G) or 8$\times$RTX 2080 Ti (11G) GPUs, the most ever affordable GPUs required for using 100B-scale models. The GLM-130B model weights are publicly accessible and its code, training logs, related toolkit, and lessons learned are open-sourced at https://github.com/THUDM/GLM-130B .