 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Parallelism Pays Off: Cohesion-Aware Task Partitioning for Multi-Agent Coding
May 31, 2026Multi-agent Large Language Model (LLM) systems offer a way to decompose complex tasks, such as coding, through parallelization and context isolation. However, adding agents in practice introduces inter-agent communication overhead, which incurs extra cost and can sometimes offset the efficiency gains. We formalize multi-agent orchestration as a graph partitioning problem that captures the communication-to-computation trade-off: task decomposition can shorten critical-path computation, but cross-agent dependencies require costly context transfer. We instantiate this view in repository-level software engineering and present Cohesion-aware Coder (Co-Coder), which builds dependency graphs from static analysis, isolates structural hub files, partitions the graph via community detection, and executes the partition with a dependency-aware scheduler. Across 28 real-world tasks on DevEval and CodeProjectEval, Co-Coder advances the Pareto-frontier over sequential and file-based parallel baselines as well as Claude Code with Agent Teams, lifting pass rate by up to 14.0%, achieving up to a 2.10x wall-clock speedup, and reducing API cost by up to 35%, with the largest gains on the most dependency-dense projects. Co-coder demonstrates how cohesion-aware orchestration can make parallel coding agents both theoretically grounded and practically efficient, suggesting a broader design principle for multi-agent systems.
Resource-efficient Inference with Foundation Model Programs
Apr 09, 2025
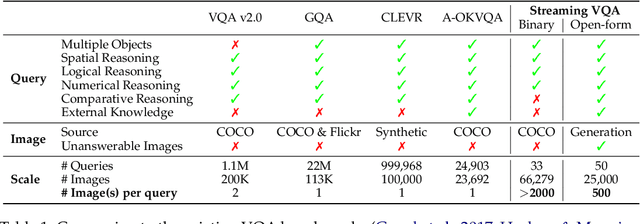
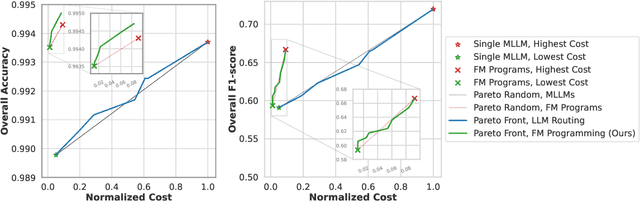
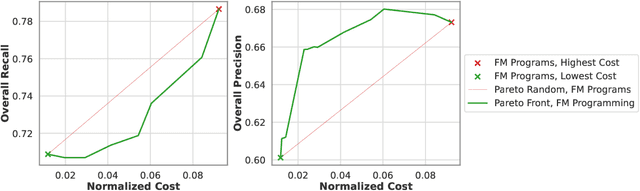
The inference-time resource costs of large language and vision models present a growing challenge in production deployments. We propose the use of foundation model programs, i.e., programs that can invoke foundation models with varying resource costs and performance, as an approach to this problem. Specifically, we present a method that translates a task into a program, then learns a policy for resource allocation that, on each input, selects foundation model "backends" for each program module. The policy uses smaller, cheaper backends to handle simpler subtasks, while allowing more complex subtasks to leverage larger, more capable models. We evaluate the method on two new "streaming" visual question-answering tasks in which a system answers a question on a sequence of inputs, receiving ground-truth feedback after each answer. Compared to monolithic multi-modal models, our implementation achieves up to 98% resource savings with minimal accuracy loss, demonstrating its potential for scalable and resource-efficient multi-modal inference.
Online Cascade Learning for Efficient Inference over Streams
Feb 07, 2024



Large Language Models (LLMs) have a natural role in answering complex queries about data streams, but the high computational cost of LLM inference makes them infeasible in many such tasks. We propose online cascade learning, the first approach to addressing this challenge. The objective here is to learn a "cascade" of models, starting with lower-capacity models (such as logistic regressors) and ending with a powerful LLM, along with a deferral policy that determines the model that is used on a given input. We formulate the task of learning cascades online as an imitation-learning problem and give a no-regret algorithm for the problem. Experimental results across four benchmarks show that our method parallels LLMs in accuracy while cutting down inference costs by as much as 90%, underscoring its efficacy and adaptability in stream processing.
Guiding the PLMs with Semantic Anchors as Intermediate Supervision: Towards Interpretable Semantic Parsing
Oct 04, 2022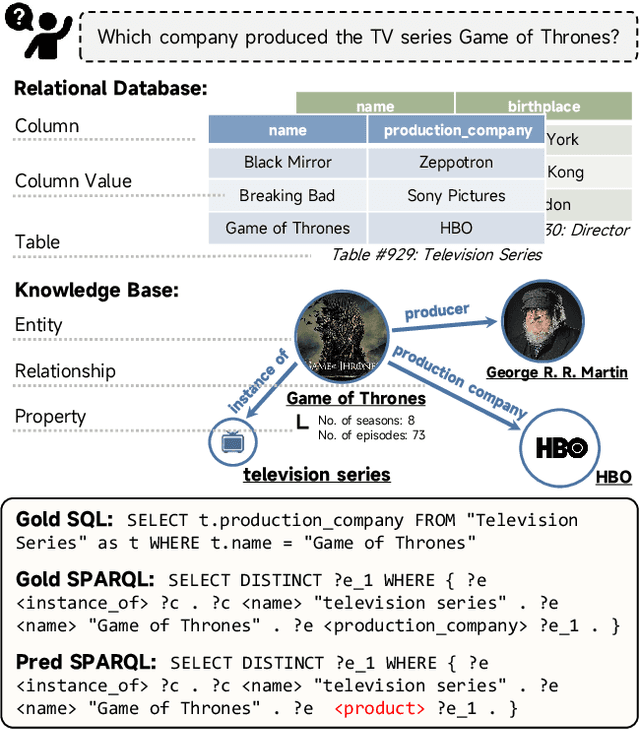
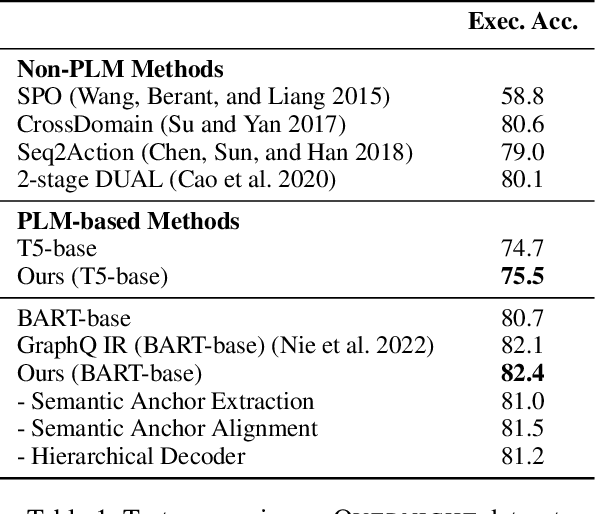
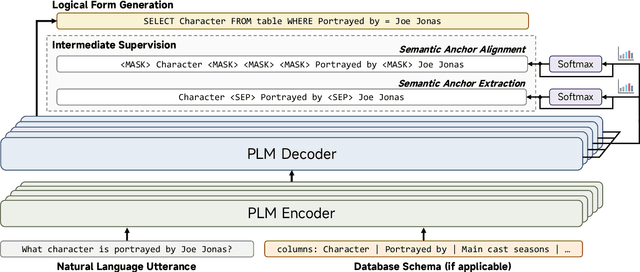
The recent prevalence of pretrained language models (PLMs) has dramatically shifted the paradigm of semantic parsing, where the mapping from natural language utterances to structured logical forms is now formulated as a Seq2Seq task. Despite the promising performance, previous PLM-based approaches often suffer from hallucination problems due to their negligence of the structural information contained in the sentence, which essentially constitutes the key semantics of the logical forms. Furthermore, most works treat PLM as a black box in which the generation process of the target logical form is hidden beneath the decoder modules, which greatly hinders the model's intrinsic interpretability. To address these two issues, we propose to incorporate the current PLMs with a hierarchical decoder network. By taking the first-principle structures as the semantic anchors, we propose two novel intermediate supervision tasks, namely Semantic Anchor Extraction and Semantic Anchor Alignment, for training the hierarchical decoders and probing the model intermediate representations in a self-adaptive manner alongside the fine-tuning process. We conduct intensive experiments on several semantic parsing benchmarks and demonstrate that our approach can consistently outperform the baselines. More importantly, by analyzing the intermediate representations of the hierarchical decoders, our approach also makes a huge step toward the intrinsic interpretability of PLMs in the domain of semantic parsing.
GraphQ IR: Unifying Semantic Parsing of Graph Query Language with Intermediate Representation
May 24, 2022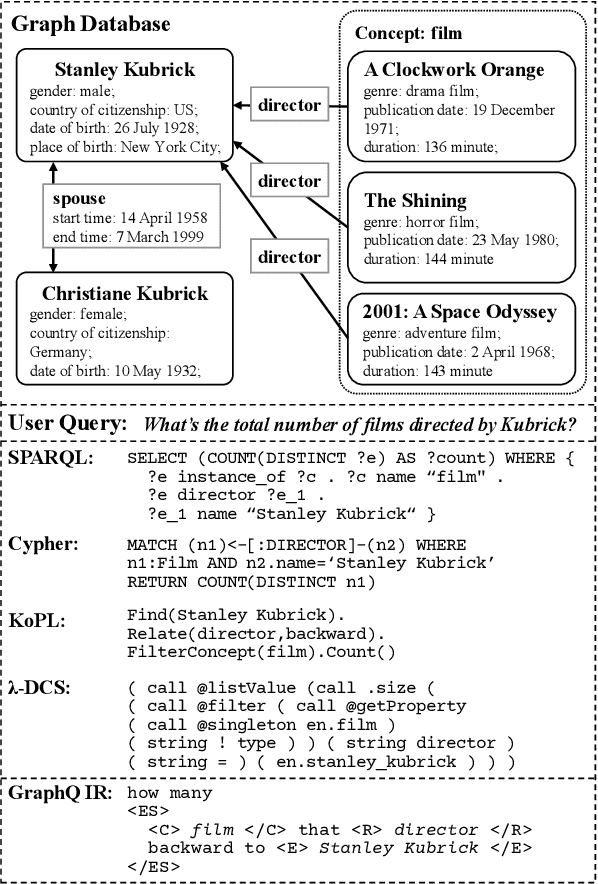

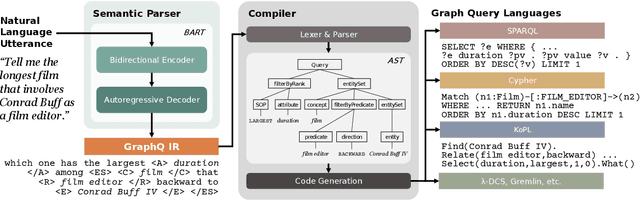
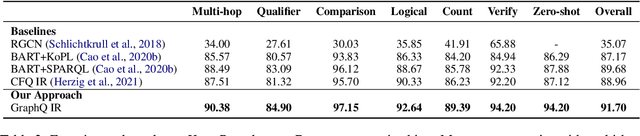
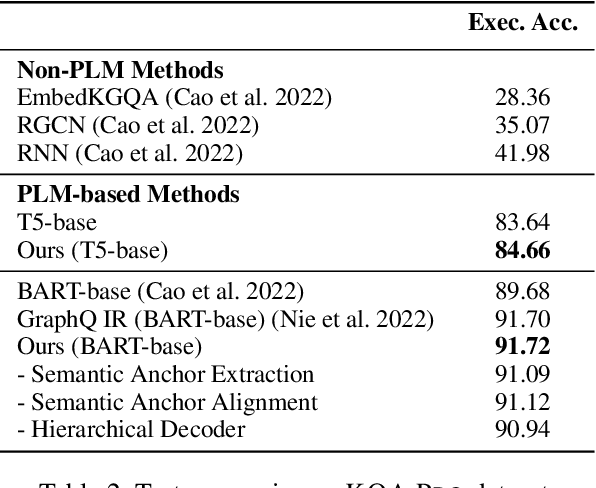
Subject to the semantic gap lying between natural and formal language, neural semantic parsing is typically bottlenecked by the paucity and imbalance of data. In this paper, we propose a unified intermediate representation (IR) for graph query languages, namely GraphQ IR. With the IR's natural-language-like representation that bridges the semantic gap and its formally defined syntax that maintains the graph structure, neural semantic parser can more effectively convert user queries into our GraphQ IR, which can be later automatically compiled into different downstream graph query languages. Extensive experiments show that our approach can consistently achieve state-of-the-art performance on benchmarks KQA Pro, Overnight and MetaQA. Evaluations under compositional generalization and few-shot learning settings also validate the promising generalization ability of GraphQ IR with at most 11% accuracy improvement.