 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Remote Labor Index: Measuring AI Automation of Remote Work
Oct 30, 2025AIs have made rapid progress on research-oriented benchmarks of knowledge and reasoning, but it remains unclear how these gains translate into economic value and automation. To measure this, we introduce the Remote Labor Index (RLI), a broadly multi-sector benchmark comprising real-world, economically valuable projects designed to evaluate end-to-end agent performance in practical settings. AI agents perform near the floor on RLI, with the highest-performing agent achieving an automation rate of 2.5%. These results help ground discussions of AI automation in empirical evidence, setting a common basis for tracking AI impacts and enabling stakeholders to proactively navigate AI-driven labor automation.
Resource-efficient Inference with Foundation Model Programs
Apr 09, 2025
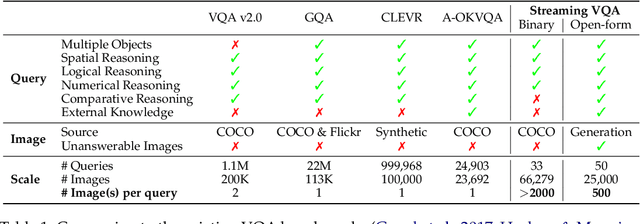
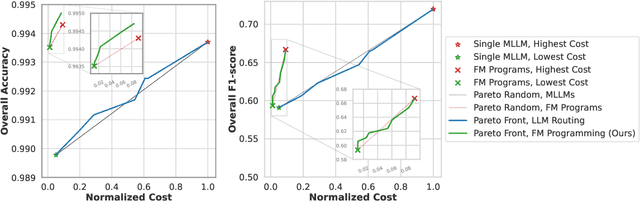
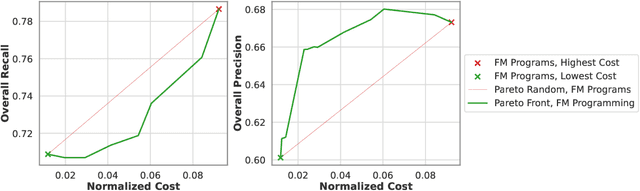
The inference-time resource costs of large language and vision models present a growing challenge in production deployments. We propose the use of foundation model programs, i.e., programs that can invoke foundation models with varying resource costs and performance, as an approach to this problem. Specifically, we present a method that translates a task into a program, then learns a policy for resource allocation that, on each input, selects foundation model "backends" for each program module. The policy uses smaller, cheaper backends to handle simpler subtasks, while allowing more complex subtasks to leverage larger, more capable models. We evaluate the method on two new "streaming" visual question-answering tasks in which a system answers a question on a sequence of inputs, receiving ground-truth feedback after each answer. Compared to monolithic multi-modal models, our implementation achieves up to 98% resource savings with minimal accuracy loss, demonstrating its potential for scalable and resource-efficient multi-modal inference.
ASKCOS: an open source software suite for synthesis planning
Jan 03, 2025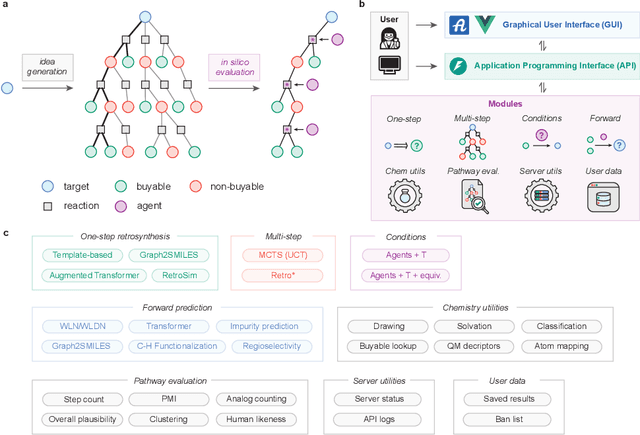



The advancement of machine learning and the availability of large-scale reaction datasets have accelerated the development of data-driven models for computer-aided synthesis planning (CASP) in the past decade. Here, we detail the newest version of ASKCOS, an open source software suite for synthesis planning that makes available several research advances in a freely available, practical tool. Four one-step retrosynthesis models form the basis of both interactive planning and automatic planning modes. Retrosynthetic planning is complemented by other modules for feasibility assessment and pathway evaluation, including reaction condition recommendation, reaction outcome prediction, and auxiliary capabilities such as solubility prediction and quantum mechanical descriptor prediction. ASKCOS has assisted hundreds of medicinal, synthetic, and process chemists in their day-to-day tasks, complementing expert decision making. It is our belief that CASP tools like ASKCOS are an important part of modern chemistry research, and that they offer ever-increasing utility and accessibility.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Infinity-MM: Scaling Multimodal Performance with Large-Scale and High-Quality Instruction Data
Oct 24, 2024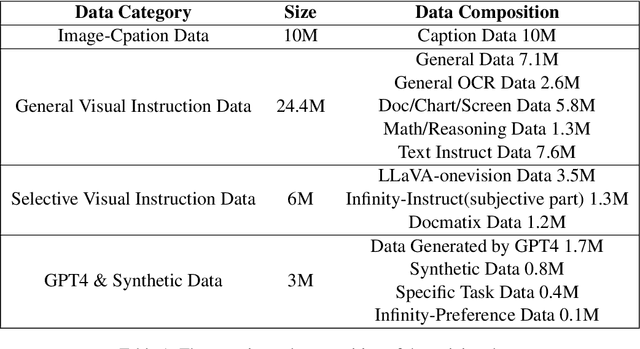
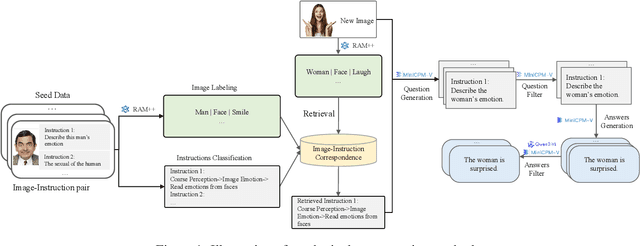
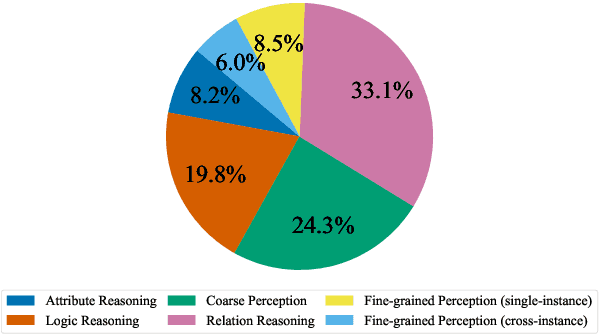
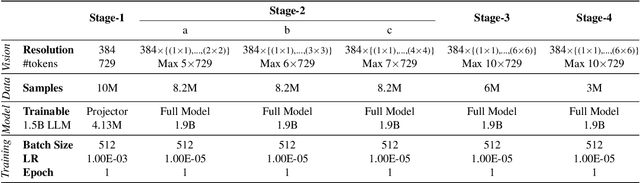
Vision-Language Models (VLMs) have recently made significant progress, but the limited scale and quality of open-source instruction data hinder their performance compared to closed-source models. In this work, we address this limitation by introducing Infinity-MM, a large-scale multimodal instruction dataset with 40 million samples, enhanced through rigorous quality filtering and deduplication. We also propose a synthetic instruction generation method based on open-source VLMs, using detailed image annotations and diverse question generation. Using this data, we trained a 2-billion-parameter VLM, Aquila-VL-2B, achieving state-of-the-art (SOTA) performance for models of similar scale. This demonstrates that expanding instruction data and generating synthetic data can significantly improve the performance of open-source models.
Double-Ended Synthesis Planning with Goal-Constrained Bidirectional Search
Jul 08, 2024



Computer-aided synthesis planning (CASP) algorithms have demonstrated expert-level abilities in planning retrosynthetic routes to molecules of low to moderate complexity. However, current search methods assume the sufficiency of reaching arbitrary building blocks, failing to address the common real-world constraint where using specific molecules is desired. To this end, we present a formulation of synthesis planning with starting material constraints. Under this formulation, we propose Double-Ended Synthesis Planning (DESP), a novel CASP algorithm under a bidirectional graph search scheme that interleaves expansions from the target and from the goal starting materials to ensure constraint satisfiability. The search algorithm is guided by a goal-conditioned cost network learned offline from a partially observed hypergraph of valid chemical reactions. We demonstrate the utility of DESP in improving solve rates and reducing the number of search expansions by biasing synthesis planning towards expert goals on multiple new benchmarks. DESP can make use of existing one-step retrosynthesis models, and we anticipate its performance to scale as these one-step model capabilities improve.
GATSBI: An Online GTSP-Based Algorithm for Targeted Surface Bridge Inspection
Dec 09, 2020
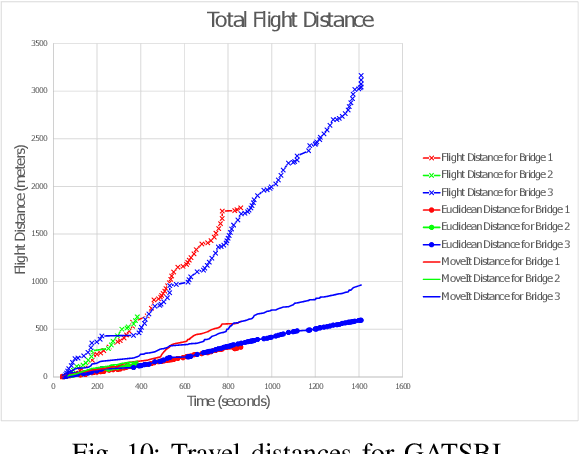
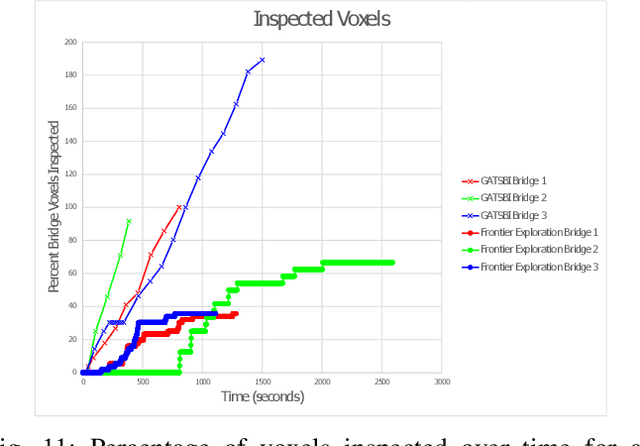
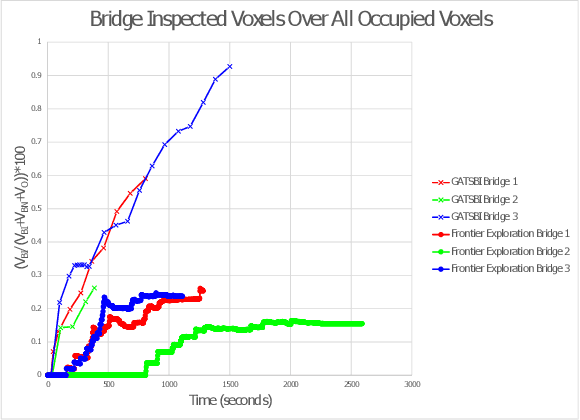
We study the problem of visually inspecting the surface of a bridge using an Unmanned Aerial Vehicle (UAV) for defects. We do not assume that the geometric model of the bridge is known. The UAV is equipped with a LiDAR and RGB sensor that is used to build a 3D semantic map of the environment. Our planner, termed GATSBI, plans in an online fashion a path that is targeted towards inspecting all points on the surface of the bridge. The input to GATSBI consists of a 3D occupancy grid map of the part of the environment seen by the UAV so far. We use semantic segmentation to segment the voxels into those that are part of the bridge and the surroundings. Inspecting a bridge voxel requires the UAV to take images from a desired viewing angle and distance. We then create a Generalized Traveling Salesperson Problem (GTSP) instance to cluster candidate viewpoints for inspecting the bridge voxels and use an off-the-shelf GTSP solver to find the optimal path for the given instance. As more parts of the environment are seen, we replan the path. We evaluate the performance of our algorithm through high-fidelity simulations conducted in Gazebo. We compare the performance of this algorithm with a frontier exploration algorithm. Our evaluation reveals that targeting the inspection to only the segmented bridge voxels and planning carefully using a GTSP solver leads to more efficient inspection than the baseline algorithms.
Coverage of an Environment Using Energy-Constrained Unmanned Aerial Vehicles
Jul 07, 2020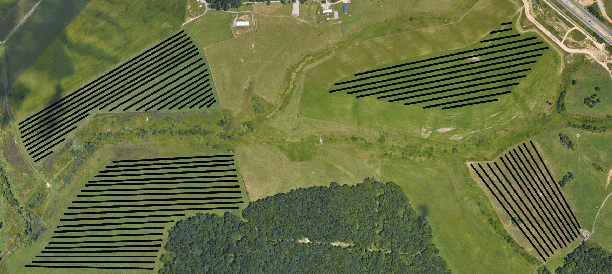
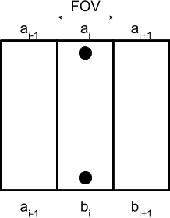

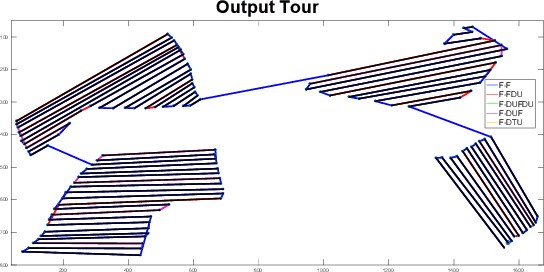
We study the problem of covering an environment using an Unmanned Aerial Vehicle (UAV) with limited battery capacity. We consider a scenario where the UAV can land on an Unmanned Ground Vehicle (UGV) and recharge the onboard battery. The UGV can also recharge the UAV while transporting the UAV to the next take-off site. We present an algorithm to solve a new variant of the area coverage problem that takes into account this symbiotic UAV and UGV system. The input consists of a set of boustrophedon cells -- rectangular strips whose width is equal to the field-of-view of the sensor on the UAV. The goal is to find a coordinated strategy for the UAV and UGV that visits and covers all cells in minimum time, while optimally finding how much to recharge, where to recharge, and when to recharge the battery. This includes flight time for visiting and covering all cells, recharging time, as well as the take-off and landing times. We show how to reduce this problem to a known NP-hard problem, Generalized Traveling Salesperson Problem (GTSP). Given an optimal GTSP solver, our approach finds the optimal coverage paths for the UAV and UGV. Our formulation models multi-rotor UAVs as well as hybrid UAVs that can operate in fixed-wing and Vertical Take-off and Landing modes. We evaluate our algorithm through simulations and proof-of-concept experiments.
Augment Yourself: Mixed Reality Self-Augmentation Using Optical See-through Head-mounted Displays and Physical Mirrors
Jul 06, 2020
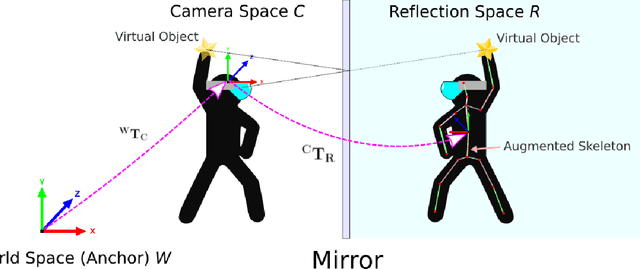
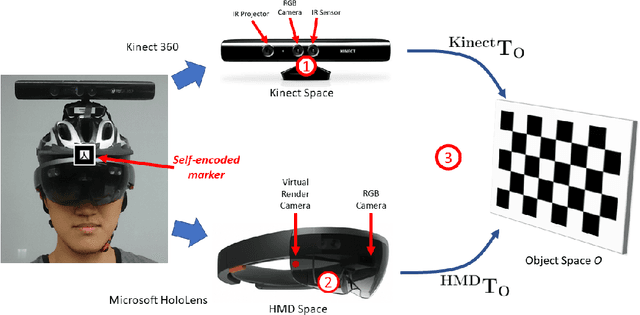
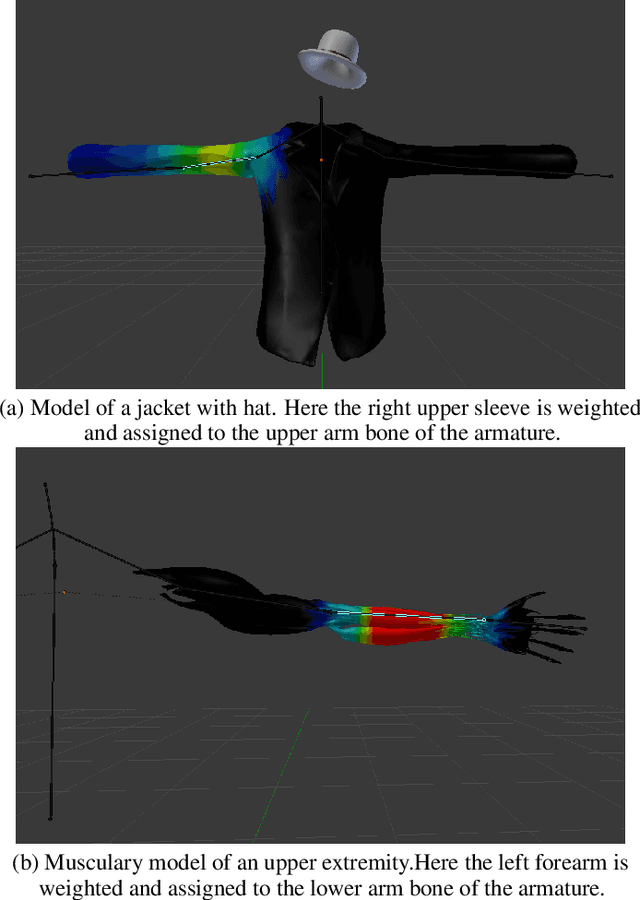
Optical see-though head-mounted displays (OST HMDs) are one of the key technologies for merging virtual objects and physical scenes to provide an immersive mixed reality (MR) environment to its user. A fundamental limitation of HMDs is, that the user itself cannot be augmented conveniently as, in casual posture, only the distal upper extremities are within the field of view of the HMD. Consequently, most MR applications that are centered around the user, such as virtual dressing rooms or learning of body movements, cannot be realized with HMDs. In this paper, we propose a novel concept and prototype system that combines OST HMDs and physical mirrors to enable self-augmentation and provide an immersive MR environment centered around the user. Our system, to the best of our knowledge the first of its kind, estimates the user's pose in the virtual image generated by the mirror using an RGBD camera attached to the HMD and anchors virtual objects to the reflection rather than the user directly. We evaluate our system quantitatively with respect to calibration accuracy and infrared signal degradation effects due to the mirror, and show its potential in applications where large mirrors are already an integral part of the facility. Particularly, we demonstrate its use for virtual fitting rooms, gaming applications, anatomy learning, and personal fitness. In contrast to competing devices such as LCD-equipped smart mirrors, the proposed system consists of only an HMD with RGBD camera and, thus, does not require a prepared environment making it very flexible and generic. In future work, we will aim to investigate how the system can be optimally used for physical rehabilitation and personal training as a promising application.