 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManiSplat: Manipulation Trajectory Synthesis from Monocular Video via Decoupled 3D Gaussian Splatting
Jun 09, 2026Reconstructing dynamic and interactive 3D scenes from real-world observations remains a fundamental challenge in computer vision and robotics. While recent advances in 3D Gaussian Splatting have enabled high-fidelity static reconstruction, extending it to interactive environments with articulated robots and manipulable objects remains difficult due to complex contact interactions and abrupt pose changes. To address these challenges, we introduce ManiSplat, a unified framework that reconstructs controllable and decoupled Gaussian digital twins directly from monocular ego-view robotic videos. Our method introduces a Graph-Structured Disentangled Representation that separates the robot, objects, and background into independently optimizable Gaussian subfields organized within a scene graph. To ensure stability, we propose a Task-Oriented Spatio-Temporal Alignment module that leverages the inherent logic of manipulation tasks-alternating between Motion and Skill phases-to construct accurate pseudo-ground-truth trajectories. Finally, a joint photometric-geometric optimization ensures the reconstructed scenes are temporally coherent, physically consistent, and simulation-ready. Extensive experiments demonstrate that our approach reconstructs interaction-driven dynamic scenes with high fidelity and controllability, effectively supporting downstream robotic tasks and policy learning.
Light-WAM: Efficient World Action Models with State-Fusion Action Decoding
Jun 06, 2026World Action Models (WAMs) extend robot policy learning by incorporating future prediction as an additional training objective, encouraging the policy to encode task-relevant temporal structure in its representations. Current WAMs often rely on large-scale generative architectures that incur high training costs and inference latency, making them difficult to deploy as efficient closed-loop policies. We propose Light-WAM, a lightweight World Action Model for efficient robot manipulation. Specifically, it is built with a compact video backbone and performs future-video supervision in a downsampled latent space, reducing the cost of video co-training while retaining its benefits for representation learning. For action prediction, Light-WAM introduces the StateFusionActionExpert, which reads adapted states from multiple backbone layers, fuses them through learned-query pooling, and directly predicts action chunks in a single forward pass. This design provides an efficient interface between video backbone representations and robot actions, avoiding the need for heavy generative action experts. Experiments demonstrate that Light-WAM maintains strong performance on LIBERO and achieves usable multi-task performance on RoboTwin 2.0, while using only 0.44B trainable parameters. It also achieves 72.03ms inference latency with 4.1GiB peak GPU memory and improved training throughput.
VFIG: Vectorizing Complex Figures in SVG with Vision-Language Models
Mar 25, 2026Scalable Vector Graphics (SVG) are an essential format for technical illustration and digital design, offering precise resolution independence and flexible semantic editability. In practice, however, original vector source files are frequently lost or inaccessible, leaving only "flat" rasterized versions (e.g., PNG or JPEG) that are difficult to modify or scale. Manually reconstructing these figures is a prohibitively labor-intensive process, requiring specialized expertise to recover the original geometric intent. To bridge this gap, we propose VFIG, a family of Vision-Language Models trained for complex and high-fidelity figure-to-SVG conversion. While this task is inherently data-driven, existing datasets are typically small-scale and lack the complexity of professional diagrams. We address this by introducing VFIG-DATA, a large-scale dataset of 66K high-quality figure-SVG pairs, curated from a diverse mix of real-world paper figures and procedurally generated diagrams. Recognizing that SVGs are composed of recurring primitives and hierarchical local structures, we introduce a coarse-to-fine training curriculum that begins with supervised fine-tuning (SFT) to learn atomic primitives and transitions to reinforcement learning (RL) refinement to optimize global diagram fidelity, layout consistency, and topological edge cases. Finally, we introduce VFIG-BENCH, a comprehensive evaluation suite with novel metrics designed to measure the structural integrity of complex figures. VFIG achieves state-of-the-art performance among open-source models and performs on par with GPT-5.2, achieving a VLM-Judge score of 0.829 on VFIG-BENCH.
HoloBrain-0 Technical Report
Feb 12, 2026In this work, we introduce HoloBrain-0, a comprehensive Vision-Language-Action (VLA) framework that bridges the gap between foundation model research and reliable real-world robot deployment. The core of our system is a novel VLA architecture that explicitly incorporates robot embodiment priors, including multi-view camera parameters and kinematic descriptions (URDF), to enhance 3D spatial reasoning and support diverse embodiments. We validate this design through a scalable ``pre-train then post-train" paradigm, achieving state-of-the-art results on simulation benchmarks such as RoboTwin 2.0, LIBERO, and GenieSim, as well as strong results on challenging long-horizon real-world manipulation tasks. Notably, our efficient 0.2B-parameter variant rivals significantly larger baselines, enabling low-latency on-device deployment. To further accelerate research and practical adoption, we fully open-source the entire HoloBrain ecosystem, which includes: (1) powerful pre-trained VLA foundations; (2) post-trained checkpoints for multiple simulation suites and real-world tasks; and (3) RoboOrchard, a full-stack VLA infrastructure for data curation, model training and deployment. Together with standardized data collection protocols, this release provides the community with a complete, reproducible path toward high-performance robotic manipulation.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
Unfolding Spatial Cognition: Evaluating Multimodal Models on Visual Simulations
Jun 05, 2025Spatial cognition is essential for human intelligence, enabling problem-solving through visual simulations rather than solely relying on verbal reasoning. However, existing AI benchmarks primarily assess verbal reasoning, neglecting the complexities of non-verbal, multi-step visual simulation. We introduce STARE(Spatial Transformations and Reasoning Evaluation), a benchmark designed to rigorously evaluate multimodal large language models on tasks better solved through multi-step visual simulation. STARE features 4K tasks spanning foundational geometric transformations (2D and 3D), integrated spatial reasoning (cube net folding and tangram puzzles), and real-world spatial reasoning (perspective and temporal reasoning), reflecting practical cognitive challenges like object assembly, mechanical diagram interpretation, and everyday spatial navigation. Our evaluations show that models excel at reasoning over simpler 2D transformations, but perform close to random chance on more complex tasks like 3D cube net folding and tangram puzzles that require multi-step visual simulations. Humans achieve near-perfect accuracy but take considerable time (up to 28.9s) on complex tasks, significantly speeding up (down by 7.5 seconds on average) with intermediate visual simulations. In contrast, models exhibit inconsistent performance gains from visual simulations, improving on most tasks but declining in specific cases like tangram puzzles (GPT-4o, o1) and cube net folding (Claude-3.5, Gemini-2.0 Flash), indicating that models may not know how to effectively leverage intermediate visual information.
SteROI-D: System Design and Mapping for Stereo Depth Inference on Regions of Interest
Feb 13, 2025



Machine learning algorithms have enabled high quality stereo depth estimation to run on Augmented and Virtual Reality (AR/VR) devices. However, high energy consumption across the full image processing stack prevents stereo depth algorithms from running effectively on battery-limited devices. This paper introduces SteROI-D, a full stereo depth system paired with a mapping methodology. SteROI-D exploits Region-of-Interest (ROI) and temporal sparsity at the system level to save energy. SteROI-D's flexible and heterogeneous compute fabric supports diverse ROIs. Importantly, we introduce a systematic mapping methodology to effectively handle dynamic ROIs, thereby maximizing energy savings. Using these techniques, our 28nm prototype SteROI-D design achieves up to 4.35x reduction in total system energy compared to a baseline ASIC.
Double-Ended Synthesis Planning with Goal-Constrained Bidirectional Search
Jul 08, 2024



Computer-aided synthesis planning (CASP) algorithms have demonstrated expert-level abilities in planning retrosynthetic routes to molecules of low to moderate complexity. However, current search methods assume the sufficiency of reaching arbitrary building blocks, failing to address the common real-world constraint where using specific molecules is desired. To this end, we present a formulation of synthesis planning with starting material constraints. Under this formulation, we propose Double-Ended Synthesis Planning (DESP), a novel CASP algorithm under a bidirectional graph search scheme that interleaves expansions from the target and from the goal starting materials to ensure constraint satisfiability. The search algorithm is guided by a goal-conditioned cost network learned offline from a partially observed hypergraph of valid chemical reactions. We demonstrate the utility of DESP in improving solve rates and reducing the number of search expansions by biasing synthesis planning towards expert goals on multiple new benchmarks. DESP can make use of existing one-step retrosynthesis models, and we anticipate its performance to scale as these one-step model capabilities improve.
EXMODD: An EXplanatory Multimodal Open-Domain Dialogue dataset
Oct 17, 2023


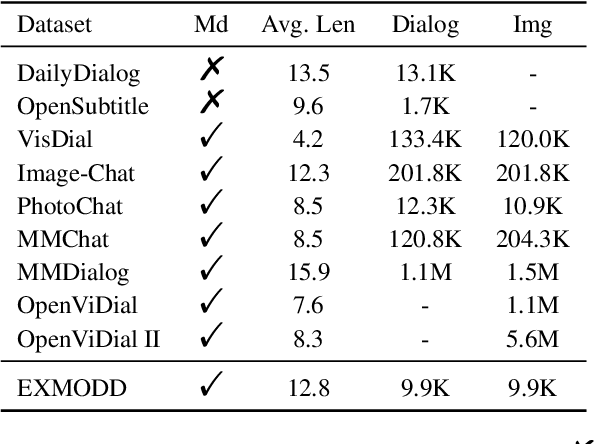
The need for high-quality data has been a key issue hindering the research of dialogue tasks. Recent studies try to build datasets through manual, web crawling, and large pre-trained models. However, man-made data is expensive and data collected from the internet often includes generic responses, meaningless statements, and toxic dialogues. Automatic data generation through large models is a cost-effective method, but for open-domain multimodal dialogue tasks, there are still three drawbacks: 1) There is currently no open-source large model that can accept multimodal input; 2) The content generated by the model lacks interpretability; 3) The generated data is usually difficult to quality control and require extensive resource to collect. To alleviate the significant human and resource expenditure in data collection, we propose a Multimodal Data Construction Framework (MDCF). MDCF designs proper prompts to spur the large-scale pre-trained language model to generate well-formed and satisfactory content. Additionally, MDCF also automatically provides explanation for a given image and its corresponding dialogue, which can provide a certain degree of interpretability and facilitate manual follow-up quality inspection. Based on this, we release an Explanatory Multimodal Open-Domain dialogue dataset (EXMODD). Experiments indicate a positive correlation between the model's ability to generate accurate understandings and high-quality responses. Our code and data can be found at https://github.com/poplpr/EXMODD.
"I am the follower, also the boss": Exploring Different Levels of Autonomy and Machine Forms of Guiding Robots for the Visually Impaired
Feb 07, 2023



Guiding robots, in the form of canes or cars, have recently been explored to assist blind and low vision (BLV) people. Such robots can provide full or partial autonomy when guiding. However, the pros and cons of different forms and autonomy for guiding robots remain unknown. We sought to fill this gap. We designed autonomy-switchable guiding robotic cane and car. We conducted a controlled lab-study (N=12) and a field study (N=9) on BLV. Results showed that full autonomy received better walking performance and subjective ratings in the controlled study, whereas participants used more partial autonomy in the natural environment as demanding more control. Besides, the car robot has demonstrated abilities to provide a higher sense of safety and navigation efficiency compared with the cane robot. Our findings offered empirical evidence about how the BLV community perceived different machine forms and autonomy, which can inform the design of assistive robots.