 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnfolding Spatial Cognition: Evaluating Multimodal Models on Visual Simulations
Jun 05, 2025Spatial cognition is essential for human intelligence, enabling problem-solving through visual simulations rather than solely relying on verbal reasoning. However, existing AI benchmarks primarily assess verbal reasoning, neglecting the complexities of non-verbal, multi-step visual simulation. We introduce STARE(Spatial Transformations and Reasoning Evaluation), a benchmark designed to rigorously evaluate multimodal large language models on tasks better solved through multi-step visual simulation. STARE features 4K tasks spanning foundational geometric transformations (2D and 3D), integrated spatial reasoning (cube net folding and tangram puzzles), and real-world spatial reasoning (perspective and temporal reasoning), reflecting practical cognitive challenges like object assembly, mechanical diagram interpretation, and everyday spatial navigation. Our evaluations show that models excel at reasoning over simpler 2D transformations, but perform close to random chance on more complex tasks like 3D cube net folding and tangram puzzles that require multi-step visual simulations. Humans achieve near-perfect accuracy but take considerable time (up to 28.9s) on complex tasks, significantly speeding up (down by 7.5 seconds on average) with intermediate visual simulations. In contrast, models exhibit inconsistent performance gains from visual simulations, improving on most tasks but declining in specific cases like tangram puzzles (GPT-4o, o1) and cube net folding (Claude-3.5, Gemini-2.0 Flash), indicating that models may not know how to effectively leverage intermediate visual information.
Perception Tokens Enhance Visual Reasoning in Multimodal Language Models
Dec 04, 2024Multimodal language models (MLMs) still face challenges in fundamental visual perception tasks where specialized models excel. Tasks requiring reasoning about 3D structures benefit from depth estimation, and reasoning about 2D object instances benefits from object detection. Yet, MLMs can not produce intermediate depth or boxes to reason over. Finetuning MLMs on relevant data doesn't generalize well and outsourcing computation to specialized vision tools is too compute-intensive and memory-inefficient. To address this, we introduce Perception Tokens, intrinsic image representations designed to assist reasoning tasks where language is insufficient. Perception tokens act as auxiliary reasoning tokens, akin to chain-of-thought prompts in language models. For example, in a depth-related task, an MLM augmented with perception tokens can reason by generating a depth map as tokens, enabling it to solve the problem effectively. We propose AURORA, a training method that augments MLMs with perception tokens for improved reasoning over visual inputs. AURORA leverages a VQVAE to transform intermediate image representations, such as depth maps into a tokenized format and bounding box tokens, which is then used in a multi-task training framework. AURORA achieves notable improvements across counting benchmarks: +10.8% on BLINK, +11.3% on CVBench, and +8.3% on SEED-Bench, outperforming finetuning approaches in generalization across datasets. It also improves on relative depth: over +6% on BLINK. With perception tokens, AURORA expands the scope of MLMs beyond language-based reasoning, paving the way for more effective visual reasoning capabilities.
Gene-Level Representation Learning via Interventional Style Transfer in Optical Pooled Screening
Jun 11, 2024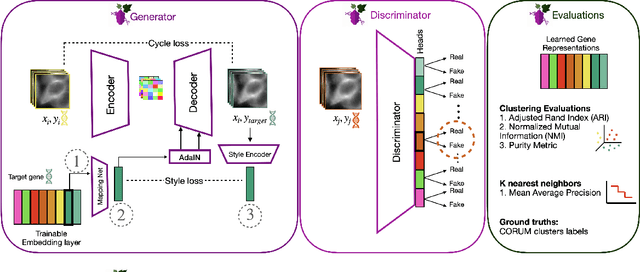
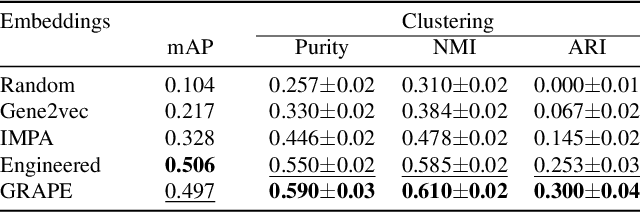
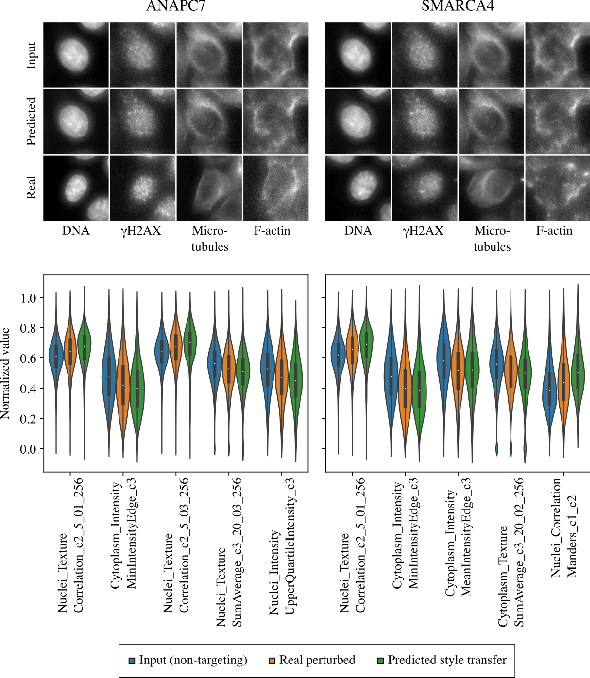

Optical pooled screening (OPS) combines automated microscopy and genetic perturbations to systematically study gene function in a scalable and cost-effective way. Leveraging the resulting data requires extracting biologically informative representations of cellular perturbation phenotypes from images. We employ a style-transfer approach to learn gene-level feature representations from images of genetically perturbed cells obtained via OPS. Our method outperforms widely used engineered features in clustering gene representations according to gene function, demonstrating its utility for uncovering latent biological relationships. This approach offers a promising alternative to investigate the role of genes in health and disease.
Data Alignment for Zero-Shot Concept Generation in Dermatology AI
Apr 19, 2024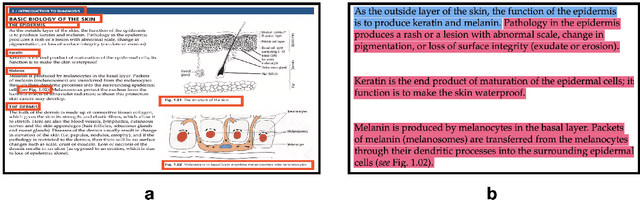



AI in dermatology is evolving at a rapid pace but the major limitation to training trustworthy classifiers is the scarcity of data with ground-truth concept level labels, which are meta-labels semantically meaningful to humans. Foundation models like CLIP providing zero-shot capabilities can help alleviate this challenge by leveraging vast amounts of image-caption pairs available on the internet. CLIP can be fine-tuned using domain specific image-caption pairs to improve classification performance. However, CLIP's pre-training data is not well-aligned with the medical jargon that clinicians use to perform diagnoses. The development of large language models (LLMs) in recent years has led to the possibility of leveraging the expressive nature of these models to generate rich text. Our goal is to use these models to generate caption text that aligns well with both the clinical lexicon and with the natural human language used in CLIP's pre-training data. Starting with captions used for images in PubMed articles, we extend them by passing the raw captions through an LLM fine-tuned on the field's several textbooks. We find that using captions generated by an expressive fine-tuned LLM like GPT-3.5 improves downstream zero-shot concept classification performance.
MIMIC: Masked Image Modeling with Image Correspondences
Jun 28, 2023Many pixelwise dense prediction tasks-depth estimation and semantic segmentation in computer vision today rely on pretrained image representations. Therefore, curating effective pretraining datasets is vital. Unfortunately, the effective pretraining datasets are those with multi-view scenes and have only been curated using annotated 3D meshes, point clouds, and camera parameters from simulated environments. We propose a dataset-curation mechanism that does not require any annotations. We mine two datasets: MIMIC-1M with 1.3M and MIMIC-3M with 3.1M multi-view image pairs from open-sourced video datasets and from synthetic 3D environments. We train multiple self-supervised models with different masked image modeling objectives to showcase the following findings: Representations trained on MIMIC-3M outperform those mined using annotations on multiple downstream tasks, including depth estimation, semantic segmentation, surface normals, and pose estimation. They also outperform representations that are frozen and when downstream training data is limited to few-shot. Larger dataset (MIMIC-3M) significantly improves performance, which is promising since our curation method can arbitrarily scale to produce even larger datasets. MIMIC code, dataset, and pretrained models are open-sourced at https://github.com/RAIVNLab/MIMIC.